
La disuguaglianza economica sta incrementando a livello globale ed è una preoccupazione crescente a causa del suo impatto negativo sulle opportunità di crescita, sulla salute e sul benessere sociale. Le tasse sono lo strumento principale che i governi hanno per ridurre la disuguaglianza, tuttavia trovare una politica fiscale che ottimizzi tanto l’uguaglianza quanto la produttività è un problema irrisolto.
La teoria fiscale si basa sulla semplificazione di ipotesi che sono difficili da provare, come ad esempio l’effetto delle tasse sul tempo che le persone decidono di lavorare. Inoltre, la sperimentazione nel mondo reale delle tasse è quasi impossibile. È in questo contesto che si inserisce il sistema “AI-Economist” elaborato da Salesforce facendo uso dell’intelligenza artificiale, il quale porta per la prima volta il Reinforcement Learning (RL) nella progettazione della politica fiscale per fornire una soluzione completamente basata sulla simulazione e sui dati.
Indice degli argomenti:
Come funziona lo studio AI-Economist?
La simulazione prevede un mondo bidimensionale. Esistono due tipi di risorse: legno e pietra, ma esse sono scarse e appaiono nel mondo a un ritmo limitato. I lavoratori si spostano, raccolgono e commerciano risorse e guadagnano reddito costruendo case (utilizzando pietra e legno). Le case costruite però bloccano l’accesso alle risorse: i lavoratori non possono muoversi attraverso le case costruite da altri. La simulazione gestisce lo sviluppo di ogni economia nel corso di un episodio, equivalente alla “carriera lavorativa” di un lavoratore. Caratteristica fondamentale è che i lavoratori hanno competenze diverse. I lavoratori più qualificati guadagnano di più dalla costruzione di case, il che crea un’utilità maggiore. La costruzione di case costa però fatica, il che ne riduce l’utilità. I lavoratori pagano le imposte sul reddito e l’imposta riscossa viene poi ridistribuita uniformemente tra i lavoratori stessi. Messi insieme, questi fattori economici e altri driver competitivi rendono necessario che i lavoratori siano strategici per massimizzare la propria utilità.
La nostra simulazione economica produce risultati interessanti quando gli agenti di intelligenza artificiale (che sono i lavoratori nella nostra economia) imparano a massimizzare la loro utilità. Una caratteristica saliente è la specializzazione: gli agenti di intelligenza artificiale con abilità inferiori diventano raccoglitori e venditori e guadagnano reddito raccogliendo e vendendo pietra e legno. Gli agenti con competenze più elevate si specializzano come acquirenti e costruttori e acquistano pietra e legno per costruire più rapidamente le case. Non siamo noi a imporre tali ruoli e comportamenti. Piuttosto, la specializzazione emerge perché i lavoratori diversamente qualificati imparano a bilanciare il loro reddito e il loro sforzo. Il Reinforcement Learning è un potente framework in cui gli agenti apprendono dall’esperienza, formatasi attraverso prove ed errori. Usiamo un RL senza modelli, in cui gli agenti non hanno alcuna conoscenza del mondo precedente né vi sono ipotesi di modellazione.
L’approccio basato sul Reinforcement Learning
Il nostro approccio basato sul Reinforcement Learning produce politiche fiscali dinamiche che producono un compromesso nettamente migliore tra uguaglianza e produttività rispetto ai metodi solitamente utilizzati. Tutte le politiche fiscali fanno uso di sette fasce di reddito, seguendo il quadro del programma federale delle imposte sul reddito degli Stati Uniti, ma cambiano le aliquote fiscali. L’imposta totale viene calcolata sommando l’imposta per ogni fascia in cui vi è reddito, suddivisi in dieci periodi fiscali di uguale lunghezza. Durante ogni periodo fiscale gli agenti interagiscono con l’ambiente per guadagnare reddito e, alla fine del periodo, i redditi sono tassati secondo il corrispondente programma fiscale e ridistribuiti equamente tra i lavoratori. La politica fiscale di AI Economist consente al programma fiscale di variare tra i diversi periodi. Il sistema economico è concepito in modo tale che la percentuale di lavoratori per ogni fascia di reddito sia paragonabile a quella statunitense.
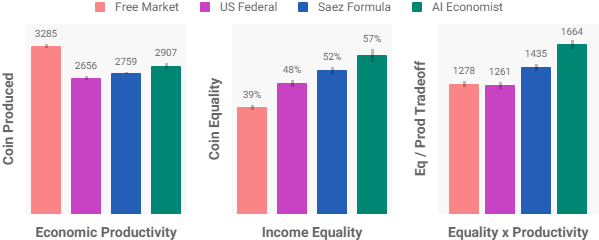
I nostri esperimenti dimostrano che AI Economist ottiene un risultato migliore almeno del 16% nel trade-off tra uguaglianza/produttività rispetto al miglior framework, che è quello della Formula di Saez. AI Economist migliora l’uguaglianza del 47% rispetto a un mercato completamente libero, con un calo della produttività dell’11%.
Rispetto alle teorie più utilizzate, AI Economist presenta una struttura più idiosincratica: una miscela di programmi progressivi e regressivi. In particolare, è presente un’aliquota fiscale superiore più elevata (reddito superiore a 510), un’aliquota fiscale più bassa per i redditi tra 160 e 510 e aliquote fiscali sia più alte che più basse su redditi inferiori a 160. Le imposte riscosse sono ridistribuite uniformemente tra gli agenti. Di fatto, gli agenti a basso reddito ricevono un sussidio netto, anche se le loro aliquote fiscali sono più elevate (prima dei sussidi). In altre parole, con AI Economist, i redditi più bassi hanno un carico fiscale inferiore.
Abbiamo cercato di comprendere se AI Economist fosse efficace anche con partecipanti umani. Questi esperimenti hanno utilizzato un set di regole più semplice per garantire una maggiore fruibilità, per esempio rimuovendo la possibilità di commerciare. Tuttavia, sono stati applicati gli stessi driver economici e gli stessi trade-off. I partecipanti sono stati pagati con denaro reale per l’utilità che guadagnavano dalla costruzione di case. Quindi, i partecipanti sono stati incentivati a costruire il numero di case che massimizzasse la loro utilità. Per gli esperimenti con partecipanti umani, abbiamo selezionato dal set di politiche AI-Driven un programma fiscale a forma di “dorso di cammello”. In 125 partite con oltre 100 partecipanti negli Stati Uniti, il programma camelback ha ottenuto un compromesso tra uguaglianza e produttività che è significativamente migliore rispetto al libero mercato e competitivo con altre teorie mainstream. Rispetto agli agenti di intelligenza artificiale, le persone erano più inclini a comportamenti contraddittori non ottimali, come l’ostacolare altri lavoratori. Ciò ha aumentato significativamente la varianza della produttività. È interessante notare che il programma camelback è qualitativamente differente dalle altre teorie fiscali. Tuttavia, le sue prestazioni relative sono soddisfacenti in tutti gli esperimenti, tanto nelle partite con agenti di intelligenza artificiale, quanto in quelle con gli esseri umani
Conclusioni e possibili sviluppi futuri
L’assenza di sostanziali differenze nelle partite giocate da umani e agenti AI è sorprendente e incoraggiante. Pertanto, questi risultati suggeriscono prospettive promettenti nell’uso di AI Economist come strumento per trovare buone politiche fiscali nelle economie reali.
Le simulazioni economiche basate sull’intelligenza artificiale presentano ancora dei limiti. Non modellano ancora i fattori comportamentali umani, le interazioni sociali tra le persone, e considerano un’economia relativamente piccola. Tuttavia, questo tipo di simulazioni fornisce una visione trasparente e oggettiva sulle conseguenze economiche delle diverse politiche fiscali. Inoltre, questo particolare approccio può essere utilizzato per qualsiasi obiettivo sociale al fine di trovare una politica fiscale con prestazioni elevate. Le simulazioni future potrebbero migliorare la fedeltà degli agenti economici utilizzando i dati del mondo reale, mentre i progressi in RL e ingegneria su larga scala potrebbero aumentare la portata delle simulazioni economiche.



