
Meta AI ha annunciato lo scorso 19 ottobre il lancio del progetto Universal Speech Translator (UST), che mira a creare sistemi di intelligenza artificiale che consentano la traduzione speech-to-speech in tempo reale in tutte le lingue, anche quelle parlate ma non comunemente scritte.
La traduzione vocale artificiale è una tecnologia di intelligenza artificiale (AI) in rapida evoluzione. Inizialmente creata per facilitare la comunicazione tra persone che parlano lingue diverse, questa tecnologia di traduzione speech-to-speech (S2ST) ha trovato la sua strada in diversi domini. Ad esempio, i conglomerati tecnologici globali stanno ora utilizzando S2ST per tradurre direttamente documenti condivisi e conversazioni audio nel metaverso.
A Cloud Next ’22, la scorsa settimana, Google aveva annunciato il proprio modello di traduzione AI speech-to-speech, “Translation Hub“, utilizzando le API di traduzione cloud e la traduzione AutoML.
Indice degli argomenti:
Un sistema open source
“Meta AI ha creato il primo traduttore vocale che funziona per le lingue che sono principalmente parlate piuttosto che scritte. Lo stiamo rendendo open source in modo che le persone possano usarlo per più lingue “, ha dichiarato Mark Zuckerberg, cofondatore e CEO di Meta.
Secondo Meta, il modello è il primo sistema di traduzione vocale basato sull’intelligenza artificiale per la lingua non scritta Hokkien, una lingua cinese parlata nel sud-est della Cina e Taiwan e da molti nella diaspora cinese in tutto il mondo. Il sistema consente ai parlanti hokkien di tenere conversazioni con persone di lingua inglese, un passo significativo verso l’abbattimento della barriera linguistica globale e riunire le persone ovunque si trovino, anche nel metaverso.
Questo è un compito difficile poiché, a differenza del mandarino, dell’inglese e dello spagnolo, che sono sia scritti che orali, l’hokkien è prevalentemente verbale.
Come l’AI di Meta può affrontare la traduzione speech-to-speech
Meta afferma che i modelli di traduzione AI di oggi sono focalizzati su lingue scritte ampiamente parlate e che oltre il 40% delle lingue principalmente orali non sono coperte da tali tecnologie di traduzione. Il progetto UST si basa sui progressi condivisi da Zuckerberg durante l’evento AI Inside the Lab tenutosi a febbraio, sulla ricerca universale di traduzione speech-to-speech di Meta AI per lingue non comuni online. Quell’evento si è concentrato sull’utilizzo di tali tecnologie di intelligenza artificiale immersiva per la costruzione del metaverso.
Per creare UST, Meta AI si è concentrata sul superamento di tre sfide critiche del sistema di traduzione. Ha affrontato la scarsità di dati acquisendo più dati di formazione in più lingue e trovando nuovi modi per sfruttare i dati già disponibili. Ha affrontato le sfide di modellazione che sorgono man mano che i modelli crescono per servire molti più linguaggi. E ha cercato nuovi modi per valutare e migliorare i suoi risultati.
Il team di ricerca di Meta AI ha lavorato sull’hokkien come caso di studio per una soluzione end-to-end, dalla raccolta dei dati di addestramento e dalle scelte di modellazione ai set di dati di benchmarking. Il team si è concentrato sulla creazione di dati annotati dall’uomo, sull’estrazione automatica di dati da grandi set di dati vocali senza etichetta e sull’adozione di pseudo-etichettatura per produrre dati debolmente supervisionati.
“Il nostro team ha prima tradotto l’inglese o il parlato hokkien in testo mandarino, e poi lo ha tradotto in hokkien o inglese”, ha detto Juan Pino, ricercatore di Meta. “Hanno quindi aggiunto le frasi accoppiate ai dati utilizzati per addestrare il modello di intelligenza artificiale”.
Per la modellazione, Meta AI ha applicato i recenti progressi nell’utilizzo di rappresentazioni discrete auto-supervisionate come obiettivi per la previsione nella traduzione speech-to-speech e ha dimostrato l’efficacia di sfruttare la supervisione aggiuntiva del testo dal mandarino, una lingua simile all’hokkien, nell’addestramento del modello. Meta AI afferma che rilascerà anche un benchmark di traduzione speech-to-speech impostato per facilitare la ricerca futura in questo campo.
Fonte: Meta AI
Come funziona il traduttore vocale universale (UST) di Meta
Il modello utilizza S2UT per convertire il parlato di input in una sequenza di unità acustiche direttamente nel percorso, un’implementazione di cui Meta è stata precedentemente pioniera. L’output generato è costituito da forme d’onda dalle unità di ingresso. Inoltre, Meta AI ha adottato UnitY per un meccanismo di decodifica a due passaggi in cui il decodificatore di primo passaggio genera testo in una lingua correlata (mandarino) e il decodificatore di secondo passaggio crea unità.
Per consentire la valutazione automatica per l’hokkien, Meta AI ha sviluppato un sistema che trascrive il parlato hokkien in una notazione fonetica standardizzata chiamata “Tâi-lô”. Ciò ha permesso al team di data science di calcolare i punteggi BLEU (una metrica standard di traduzione automatica) a livello di sillaba e confrontare rapidamente la qualità della traduzione di diversi approcci.
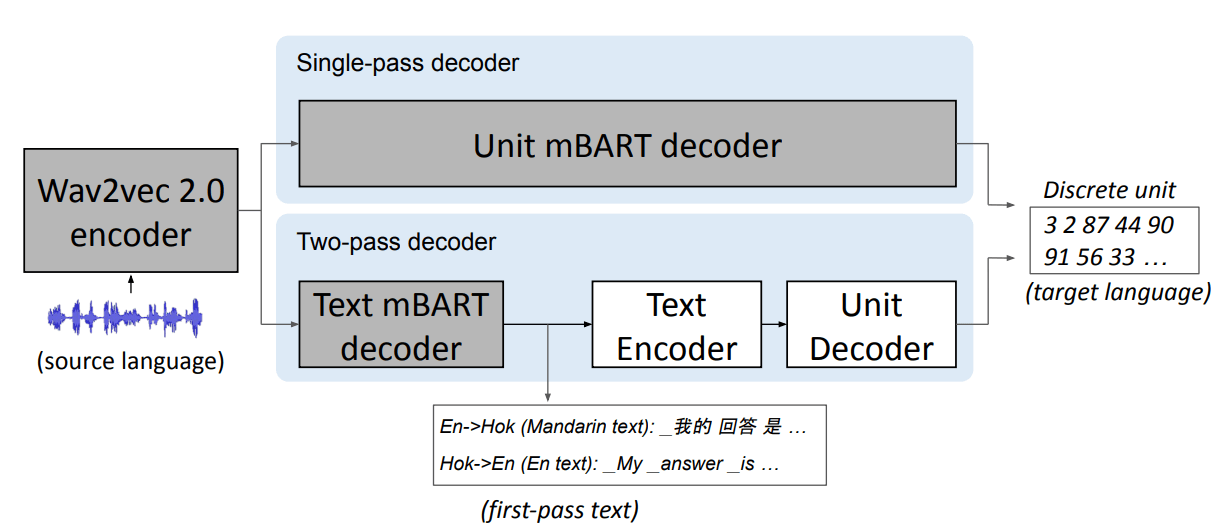
Fonte: Meta AI
L’architettura del modello di UST con decodificatori a passaggio singolo e a due passaggi. I blocchi in ombra illustrano i moduli che sono stati preaddestrati.
Oltre a sviluppare un metodo per valutare le traduzioni vocali hokkien-inglese, il team ha creato il primo set di dati di riferimento per la traduzione vocale bidirezionale hokkien-inglese, basato su un corpus vocale hokkien chiamato Taiwanese Across Taiwan.
Meta AI afferma che le tecniche che ha sperimentato con l’hokkien possono essere estese a molte altre lingue non scritte e alla fine funzionare in tempo reale. A questo scopo, Meta sta rilasciando la Speech Matrix, un ampio corpus di traduzioni speech-to-speech estratte con l’innovativa tecnica di data mining di Meta chiamata LASER. Ciò consentirà ad altri team di ricerca di creare i propri sistemi S2ST.
LASER converte frasi di varie lingue in un’unica rappresentazione multimodale e multilingue. Il modello utilizza una ricerca di somiglianza multilingue su larga scala per identificare frasi simili nello spazio semantico, cioè quelle che potrebbero avere lo stesso significato in lingue diverse.
I dati estratti dalla matrice vocale forniscono 418.000 ore di parlato parallelo per addestrare il modello di traduzione, coprendo 272 direzioni linguistiche. Finora, più di 8.000 ore di discorso hokkien sono state estratte insieme alle corrispondenti traduzioni inglesi.


