
Ecco una serie di novità nel campo dell’AI e della robotica annunciate negli ultimi giorni.
Un team di ingegneri dell’Università di Glasgow ha sviluppato una “pelle artificiale” che può imparare a sperimentare e reagire al dolore simulato. I ricercatori di DeepMind hanno sviluppato un sistema di apprendimento automatico che prevede dove i giocatori di calcio correranno sul campo, mentre gruppi dell’Università cinese di Hong Kong (CUHK) e dell’Università Tsinghua hanno creato algoritmi in grado di generare foto realistiche – e persino video – di modelli umani.
Indice degli argomenti:
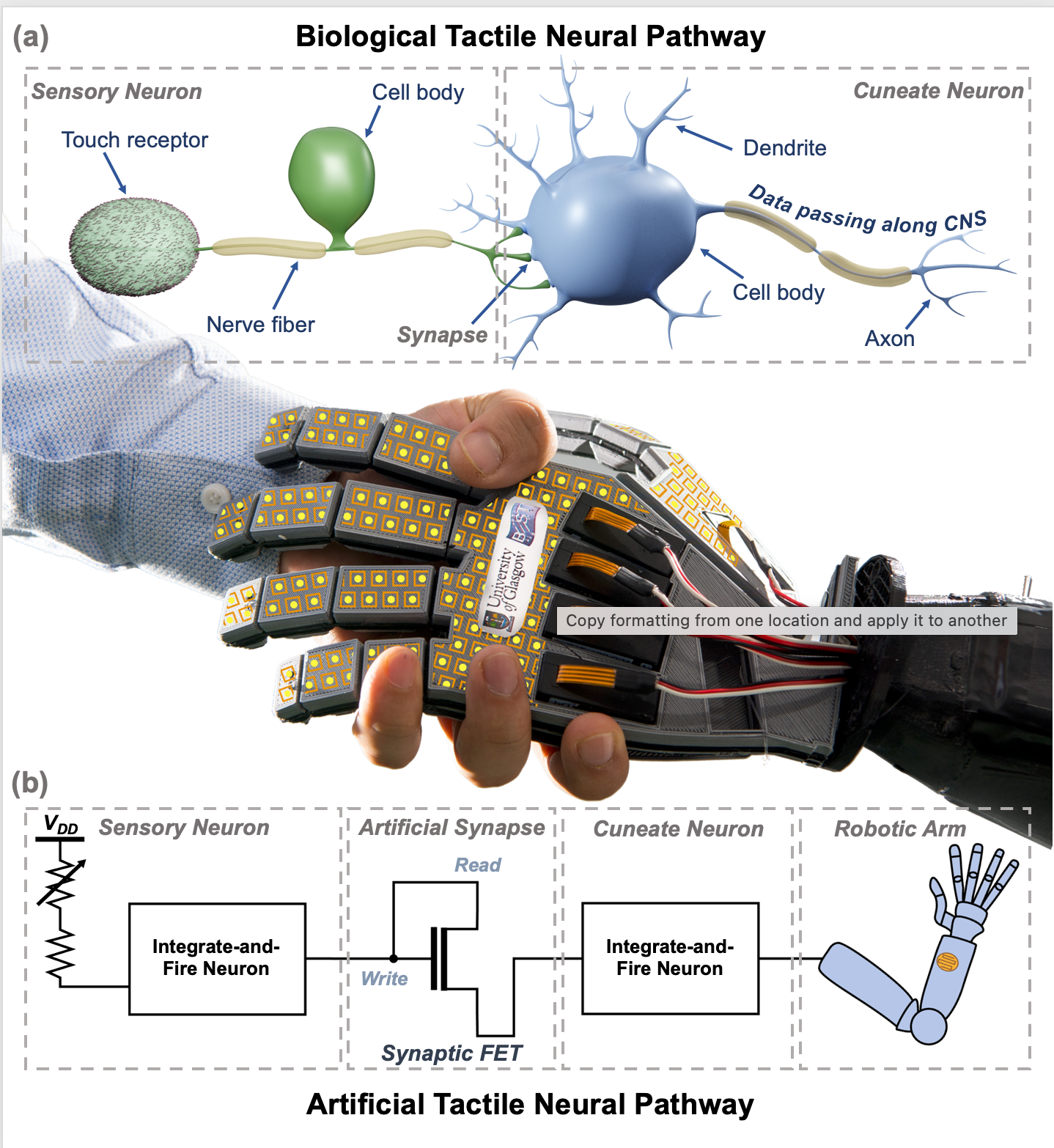
La “pelle artificiale” per i robot
La pelle artificiale del team dell’Università di Glasgow sfrutta un nuovo tipo di sistema di elaborazione basato su “transistor sinaptici” progettati per imitare i percorsi neurali del cervello. I transistor, realizzati con nanofili di ossido di zinco stampati sulla superficie di una plastica flessibile, collegati a un sensore cutaneo che registra cambiamenti nella resistenza elettrica.
La pelle artificiale è già stata tentata in precedenza, ma il team afferma che il loro design differisce in quanto utilizza un circuito integrato nel sistema per agire come una “sinapsi artificiale”, riducendo l’ingresso a un picco di tensione. Ciò accelera l’elaborazione e permette al team di “insegnare” alla pelle come rispondere al dolore simulato, impostando una soglia di tensione di ingresso la cui frequenza varia in base al livello di pressione applicato sulla pelle.
Il team prevede un utilizzo nella robotica per la pelle artificiale, dove potrebbe, ad esempio, impedire a un braccio robotico di entrare in contatto con temperature pericolosamente elevate.
Graph Imputer di DeepMind prevede le mosse dei calciatori
Correlato alla robotica, DeepMind afferma di aver sviluppato un modello di intelligenza artificiale, Graph Imputer, in grado di anticipare dove si muoveranno i giocatori di calcio utilizzando le registrazioni della telecamera di un sottoinsieme di giocatori. Il sistema può fare previsioni sui giocatori oltre la vista della telecamera, permettendo di tracciare la posizione della maggior parte – se non di tutti – i giocatori sul campo in modo abbastanza accurato.
Graph Imputer non è perfetto, ma i ricercatori di DeepMind dicono che potrebbe essere usato per applicazioni come la modellazione del controllo del campo, o la probabilità che un giocatore possa controllare la palla supponendo che si trovi in una determinata posizione. Diverse squadre leader della Premier League utilizzano modelli di controllo del campo durante le partite, nonché nell’analisi pre-partita e post-partita. Oltre al calcio e ad altre analisi sportive, DeepMind prevede che le tecniche alla base di Graph Imputer saranno applicabili a domini come la modellazione pedonale su strade e la modellazione della folla negli stadi.

Text2Human, video da testo
Text2Human, sviluppato dal Multimedia Lab di CUHK, può tradurre una didascalia come “la signora indossa una maglietta a maniche corte con motivi di colore puro e una gonna corta e denim” in una foto di una persona che in realtà non esiste.
In collaborazione con l’Accademia di Intelligenza Artificiale di Pechino, l’Università Tsinghua ha creato un modello ancora più ambizioso chiamato CogVideo in grado di generare videoclip dal testo (ad esempio “un uomo nello sci”, “un leone sta bevendo acqua”). Le clip sono piene di artefatti e altre stranezze visive, ma considerando che si tratta di scene completamente immaginarie, non si possono criticare.
![[SIGGRAPH 2022] Text2Human Demo Video](https://www.ai4business.it/wp-content/plugins/wp-youtube-lyte/lyteCache.php?origThumbUrl=https%3A%2F%2Fi.ytimg.com%2Fvi%2FyKh4VORA_E0%2F0.jpg)
Video Text2Human
Machine learning nella scoperta di nuovi farmaci
L’apprendimento automatico viene spesso utilizzato nella scoperta di nuovi farmaci, dove la varietà quasi infinita di molecole che appaiono in letteratura devono essere ordinate e caratterizzate al fine di trovare effetti potenzialmente benefici. Ma il volume di dati è così grande e il costo dei falsi positivi potenzialmente così alto (è costoso e dispendioso in termini di tempo inseguire i lead) che anche l’accuratezza del 99% non è abbastanza. Questo è particolarmente vero per i dati molecolari non etichettati, di gran lunga la maggior parte di ciò che è là fuori (rispetto alle molecole che sono state studiate manualmente nel corso degli anni).
I ricercatori della Carnegie Mellon University hanno lavorato per creare un modello per ordinare miliardi di molecole non caratterizzate addestrandolo a dare loro un senso senza alcuna informazione aggiuntiva. Lo fa apportando lievi modifiche alla struttura della molecola (virtuale), come nascondere un atomo o rimuovere un legame e osservare come cambia la molecola risultante. Ciò consente di apprendere le proprietà intrinseche di come tali molecole si formano e si comportano e lo porta a superare altri modelli di intelligenza artificiale nell’identificazione di sostanze chimiche tossiche in un database di test.



