
Il 24 aprile 2026 DeepSeek ha rilasciato su Hugging Face, con licenza MIT, due nuovi modelli in versione preview: V4-Pro da 1,6 trilioni di parametri totali (49 miliardi attivati) e V4-Flash da 284 miliardi totali (13 miliardi attivati), entrambi con finestra di contesto da 1 milione di token.
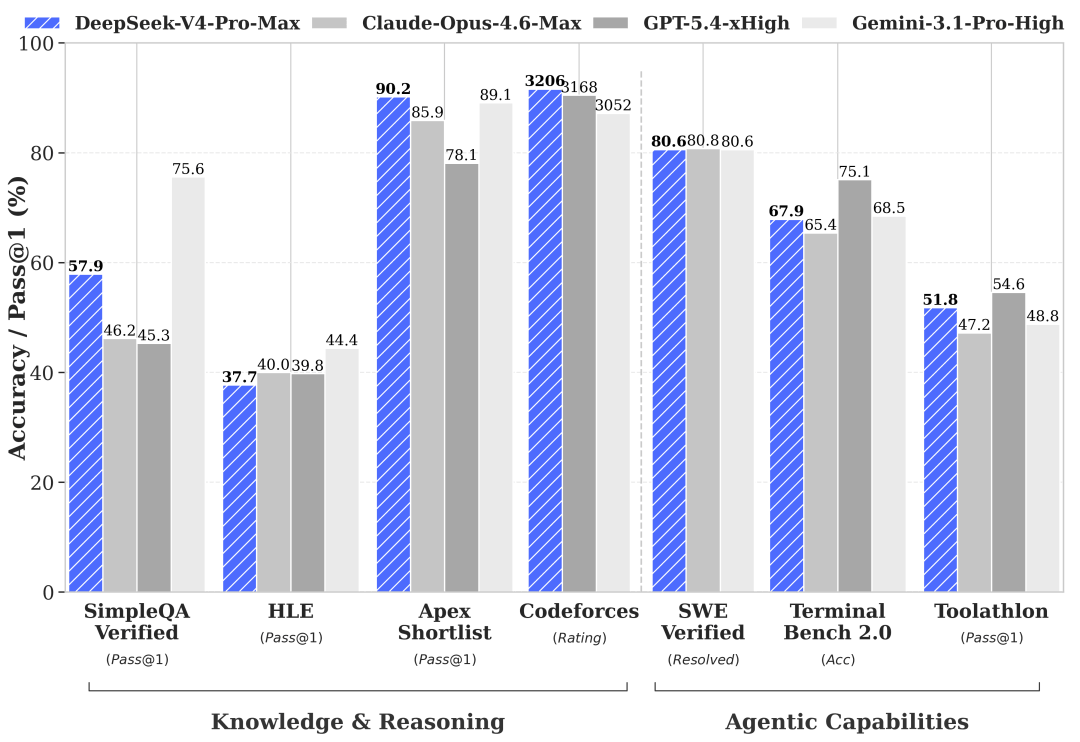
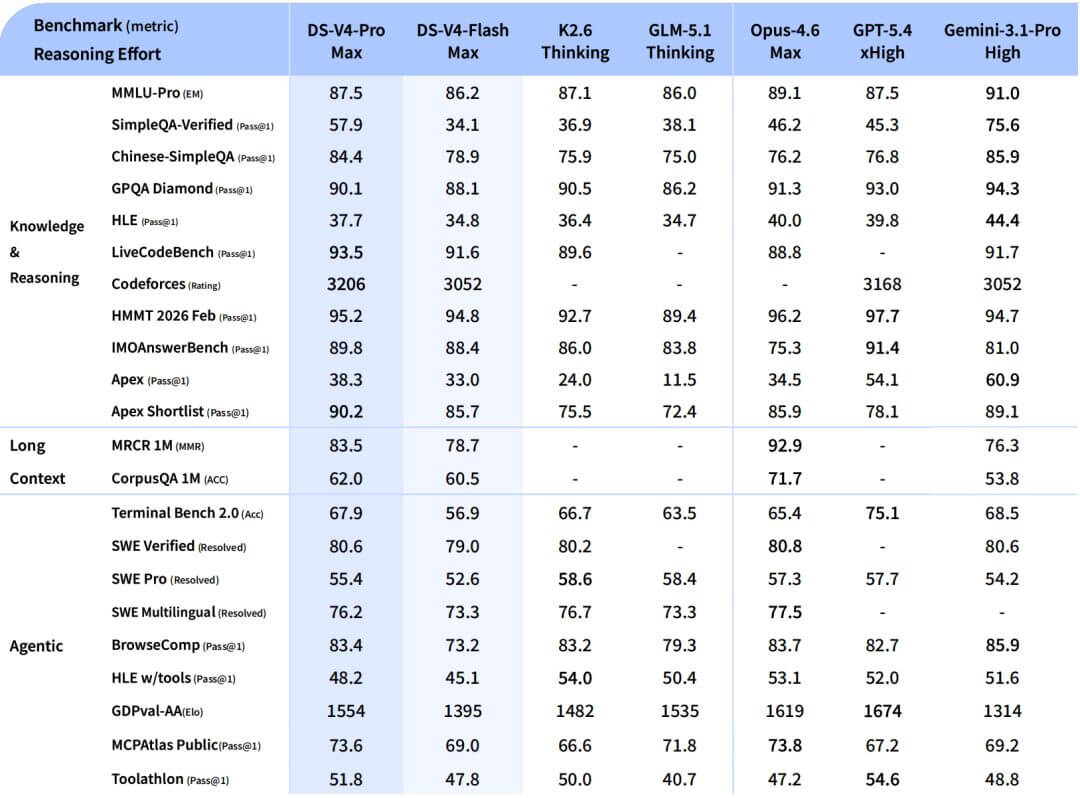
Sul piano delle prestazioni dichiarate il quadro è netto: V4-Pro in modalità Max supera Claude Opus 4.6, GPT-5.4 e Gemini 3.1-Pro su LiveCodeBench (93,5), su Codeforces (rating 3206) e su Apex Shortlist (90,2), si tiene a contatto su SWE-Verified (80,6 contro 80,8 di Opus) e resta dietro solo a Gemini 3.1-Pro sulla conoscenza generale.
In Italia il sistema arriva mentre il Garante tiene ancora attivo il blocco al servizio DeepSeek deciso a gennaio 2025, e questa asimmetria, tra modello open-weight e servizio cloud vietato, è il nodo che chi valuta l’adozione deve sciogliere prima di qualsiasi confronto tecnico.

Indice degli argomenti:
Al vertice nel coding, dietro sulla conoscenza
V4-Pro-Max tocca 87,5 su MMLU-Pro, allineandosi esattamente a GPT-5.4 e restando sotto Gemini 3.1-Pro (91,0) e Claude Opus 4.6 (89,1).
Su HLE, il benchmark più duro per conoscenza e ragionamento, si ferma a 37,7 contro 40,0 di Opus e 44,4 di Gemini.
Su IMOAnswerBench raggiunge 89,8, sopra Opus (75,3) e Gemini (81,0), sotto GPT-5.4 (91,4). Su HMMT 2026 fa 95,2, con Opus (96,2) e GPT-5.4 (97,7) leggermente avanti.
Sul coding competitivo il rating Codeforces di 3206 è il più alto dei frontier model riportati, superiore a GPT-5.4 (3168) e Gemini (3052).
La lettura onesta di questi dati è duplice.
Sul lato coding, reasoning matematico e agentic workflow V4-Pro è dentro la banda dei migliori modelli al mondo, spesso davanti.
Sul lato conoscenza generale e world knowledge fattuale, il divario con Gemini 3.1-Pro resta visibile, in particolare su SimpleQA-Verified dove Gemini fa 75,6 e V4-Pro si ferma a 57,9.
DeepSeek stessa nel model card descrive la propria traiettoria come tre-sei mesi dietro la frontiera closed-source, una stima realistica che aiuta a tarare le aspettative.
V4-Pro: 27% dei FLOP, 10% di KV cache
La parte tecnicamente più interessante del rilascio sta nel modo in cui DeepSeek ottiene quelle prestazioni su un contesto da 1 milione di token.
L’architettura di attenzione ibrida combina Compressed Sparse Attention (CSA) e Heavily Compressed Attention (HCA): la prima comprime la KV cache lungo la dimensione della sequenza e applica selezione sparsa (top-k 1024 in V4-Pro, top-k 512 in V4-Flash), la seconda usa un fattore di compressione 128 con attenzione densa per garantire copertura globale a costo ridotto. I due meccanismi sono interlacciati nello stack.
V4-Pro richiede il 27% dei FLOP per token e il 10% della KV cache rispetto a V3.2 su contesto da 1 milione di token.
Il risultato misurato è che V4-Pro su contesto da 1M richiede il 27% dei FLOP per token rispetto a V3.2 e il 10% della KV cache. Tradotto: stesso modello, dieci volte meno memoria occupata dalla cache durante l’inferenza, un quarto del calcolo. Questa è la leva economica che permette pricing API a 0,28 dollari per milione di token in input, circa cinquanta volte meno di Claude Opus 4.6.
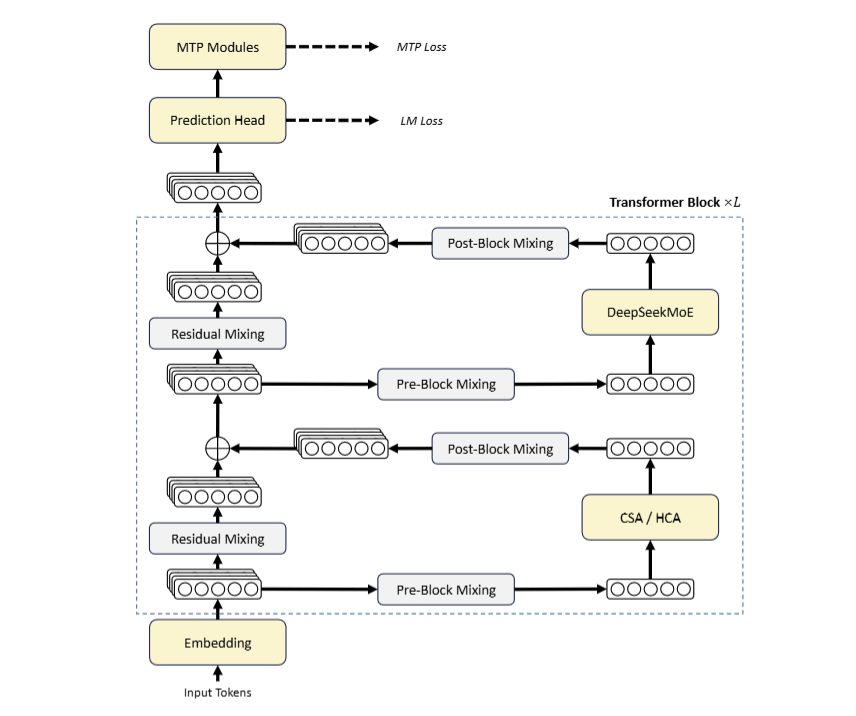
Accanto all’attenzione ci sono due ingredienti complementari: le Manifold-Constrained Hyper-Connections (mHC) per stabilizzare la propagazione del segnale negli strati profondi, e l’optimizer Muon per convergenza più veloce in training. L’insieme, pre-addestrato su 32 trilioni di token, è l’esito di una scelta industriale chiara, produrre intelligenza a costo sostenibile invece di inseguire lo scaling puro.
Il Garante per la privacy non ha sbloccato DeepSeek
Il 30 gennaio 2025 il Garante per la privacy ha imposto una limitazione definitiva e di carattere d’urgenza al trattamento dei dati personali degli utenti italiani da parte di Hangzhou DeepSeek Artificial Intelligence e Beijing DeepSeek Artificial Intelligence.
La contestazione non è tecnica, è di principio: la privacy policy indicava archiviazione dei dati in Cina senza le garanzie previste dall’articolo 32 GDPR, mancava una base giuridica documentata per il trattamento, non era stato designato un rappresentante UE ai sensi dell’articolo 27, e la società aveva risposto alla richiesta di chiarimenti sostenendo di non essere soggetta al GDPR perché non operante in Italia.
Il Garante ha giudicato la risposta insufficiente e ha bloccato il servizio in via definitiva, una posizione rafforzata a febbraio 2026 da un’analisi IAPP che evidenzia come la Cina non abbia una decisione di adeguatezza europea e come il quadro regolatorio cinese ponga questioni specifiche sulla sicurezza del trattamento.
Il punto che cambia tutto è l’architettura della distribuzione DeepSeek. I pesi dei modelli sono pubblicati con licenza MIT su Hugging Face, la stessa licenza che regola software completamente libero per uso commerciale. Chi scarica V4-Pro o V4-Flash e li esegue sulla propria infrastruttura non sta usando il servizio che il Garante ha bloccato: sta usando un modello matematico, che una volta caricato in memoria non comunica con i server DeepSeek, non trasmette prompt, non invia telemetria. Il blocco regolatorio riguarda il servizio chat.deepseek.com e l’app mobile, non i pesi neurali in sé.
Questa distinzione ha conseguenze pratiche pesanti per chi valuta l’adozione: l‘opzione cloud DeepSeek è preclusa nel contesto italiano, l’opzione self-hosting rimane tecnicamente aperta, con tutti i vincoli GDPR che restano in capo al titolare del trattamento.
Quando vale davvero l’air-gapped
L’ipotesi di eseguire V4-Pro su hardware aziendale va inquadrata senza marketing. La versione FP8 Mixed del modello base occupa circa 862 miliardi di parametri in formato tensor, la versione instruct usa FP4 per i parametri degli expert MoE e FP8 per il resto.
Per l’inferenza in production su V4-Pro servono cluster multi-GPU con tensor parallelism e pipeline parallelism, l’ordine di grandezza è quello dei datacenter enterprise con otto-sedici H100 (Nvidia) o superiori.
V4-Flash da 284 miliardi totali è più gestibile, ma resta fuori dalla portata di una singola workstation. Le versioni distillate della famiglia R1 già disponibili, da 1,5 a 70 miliardi di parametri, girano su hardware molto più accessibile: un RTX 4090 da 24 GB di VRAM regge tranquillamente la variante 32B quantizzata, un laptop con 8 GB di VRAM fa girare la 7-8B attraverso Ollama in pochi minuti di setup.
Per il mondo finance, healthcare, pubblica amministrazione, legal, lo scenario concretamente interessante è il deployment air-gapped: modello distribuito su infrastruttura interna, nessuna connessione esterna, prompt e output che non escono mai dal perimetro di rete. Questo risolve il problema sorveglianza estera e risolve anche il problema sovranità del dato, due dimensioni che nessun fornitore cloud, europeo o americano o cinese, può garantire allo stesso livello.
Il costo, ovviamente, è elevato: hardware, competenze ML-ops, manutenzione, aggiornamenti del modello quando esce una versione nuova. Chi lo sostiene lo fa perché il dato vale più del risparmio.
Open-weight cinese, servizio cloud proibito
V4 arriva in un mercato dove il gap tra modelli open-weight cinesi e frontier closed-source occidentali è ormai di mesi, non di generazioni.
Il premier cinese Li Qiang a marzo ha rivendicato pubblicamente che i grandi modelli AI cinesi guidano lo sviluppo dell’ecosistema open-source globale, affermazione confermata dai numeri: il 63% dei nuovi modelli fine-tuned su Hugging Face partono da basi cinesi.
Sullo sfondo resta l’accusa, sollevata da Anthropic a febbraio 2026, secondo cui DeepSeek avrebbe usato migliaia di account fraudolenti per generare milioni di conversazioni con Claude e usarle come training data, accusa che DeepSeek non ha né confermato né smentito in modo dettagliato.
La stessa settimana del lancio, lo Science and Technology Office della Casa Bianca ha parlato di campagne di distillation industriale per rubare tecnologia AI americana, riferendosi principalmente a entità cinesi.
La scelta su cosa farne, per un’impresa, non passa dal benchmark migliore. Passa da quale rischio di compliance, di sovranità e di reputazione si è disposti ad accettare, e da quale architettura di deployment rende quel rischio gestibile.
I pesi di V4 sono un artefatto tecnico di valore, separato dal servizio che il Garante ha bloccato, usabile con cautela e con un presidio di governance serio.
Ma la domanda che questa release solleva è meno tecnologica e più politica: se il miglior modello open-weight al mondo viene dalla Cina, e se il servizio cloud che lo espone al mercato non è conforme al nostro quadro normativo, cosa impedisce all’Europa di costruire la propria alternativa con pesi aperti, infrastruttura continentale e garanzie di compliance by design?
Senza dubbio, a valle di una lettura di questi numeri ci si chiede perché la risposta europea non sia ancora arrivata.





Partecipa alla community