Tre famiglie di domande che, mal poste, fanno fallire i progetti agentici prima ancora che partano:
- come funziona davvero il ciclo che un agente percorre quando lavora;
- con quale modello costruirlo, tra le decine sul mercato;
- quanto costa davvero esercirlo, una volta che è in produzione.
Sono domande tecniche solo in superficie. Sotto, sono decisioni di strategia industriale. La scelta tra modello proprietario di Anthropic o OpenAI e modello open source eseguito su infrastruttura controllata vale per un CIO quanto la scelta tra cloud pubblico e data center privato negli anni Duemila: cambia il profilo di rischio, la struttura dei costi, la composizione dei team, l’autonomia operativa nei prossimi cinque anni.
La scelta dell’infrastruttura su cui far girare gli agenti decide quanto velocemente li si può modificare quando il business cambia.
Il modo in cui si misurano i costi decide se il progetto si chiude in attivo o si trasforma in un’emorragia che il CFO scopre al terzo trimestre.
Per chi lavora dentro la Pubblica Amministrazione o in settori regolati con audience Agenda Digitale, c’è una dimensione in più: la sovranità digitale. Gli agenti AI ragionano su dati che spesso sono cittadini, contratti pubblici, informazioni sanitarie, transazioni bancarie. Dove finiscono questi dati durante l’inferenza, chi li può vedere, su quale giurisdizione, sono questioni che nel 2026 non sono più rinviabili.
Il mercato europeo dei modelli linguistici sovrani, dal francese Mistral all’italiano Minerva, è cresciuto proprio per rispondere a questa esigenza, e merita attenzione tecnica precisa.
Indice degli argomenti:
Il loop percezione-decisione-azione, in dettaglio
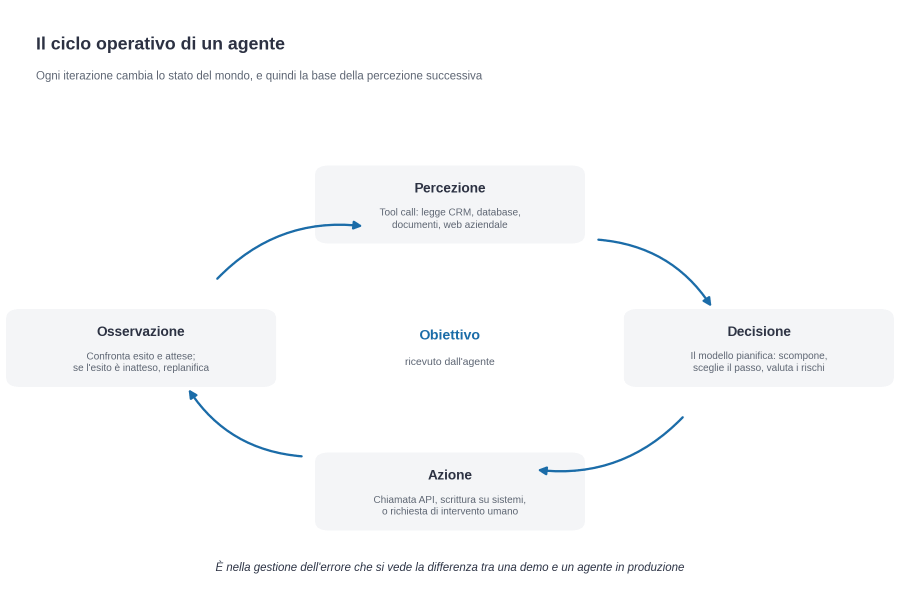
Per capire come funziona davvero un agente, bisogna entrare nel suo ciclo operativo. Un agente non risponde semplicemente a un prompt: percorre un loop. Riceve un obiettivo, percepisce lo stato del mondo intorno a sé attraverso strumenti che chiama, ragiona su cosa fare e poi agisce, osservando il risultato, e ricomincia. Lo schema è ripetitivo solo in astratto: ogni iterazione è cognitivamente diversa dalla precedente.
Le varie fasi di azione di un agente AI
La fase di percezione è quella in cui l’agente recupera informazioni dal contesto in cui opera. Concretamente: chiama un’API del CRM e legge la pipeline, interroga un database per recuperare lo storico di un cliente, scarica un documento dal sistema di gestione documentale, fa una ricerca sul web aziendale.
Questi sono i tool call, e sono il primo punto in cui i costi e le latenze esplodono. Un agente mal disegnato che fa cinque chiamate dove ne basterebbero due moltiplica per due e mezzo i tempi di risposta e i costi di inferenza per ogni iterazione del loop.
La fase di decisione è quella in cui il modello linguistico, ricevuto il contesto recuperato, ragiona su cosa fare. Si esprime in termini di pianificazione: scomporre l’obiettivo in passi, scegliere il primo passo da eseguire, considerare le alternative, valutare i rischi. Le scelte dipendono dalla qualità del modello, dalla chiarezza dell’istruzione iniziale (il system prompt, che è il documento di “ruolo” che governa l’agente), dalla quantità di contesto disponibile.
Modelli con capacità di ragionamento strutturato come Claude Opus, GPT-5.5, Gemini 3.1 Pro decidono meglio dei modelli più piccoli, e costano corrispondentemente di più per ogni decisione.
La fase di azione è quella in cui l’agente esegue il passo deciso. Se l’azione è una chiamata API, si torna ai tool call. Se è una scrittura su un sistema esterno, la sicurezza diventa centrale (quale account, quali privilegi, quale traccia di audit). Se è una richiesta di intervento umano, l’agente sospende e attende. Ogni azione cambia lo stato del mondo, e quindi cambia la base su cui l’agente farà la prossima percezione.
La fase di osservazione chiude il loop. L’agente legge l’esito dell’azione e lo confronta con quanto si aspettava. Se l’esito conferma il piano, procede al passo successivo. Se l’esito è inatteso (un’API ha restituito errore, un dato cercato non esiste, un’autorizzazione è stata negata), l’agente replanifica. È nella gestione dell’errore che si vede la differenza tra un agente serio e una demo: la demo gestisce il caso normale, l’agente in produzione gestisce le eccezioni.
Un dato concreto: la ricerca dello Stevens Institute of Technology sull’economia degli agenti citata da diverse analisi 2026 segnala che un reasoning loop che fa dieci cicli completi consuma fino a cinquanta volte più token di una singola passata lineare. È la matematica spietata che dietro un agente che lavora bene su un compito complesso si nasconde un volume di inferenza decisamente superiore a quanto si percepisce in superficie. Senza un tetto esplicito al numero di iterazioni, un agente può andare in loop e bruciare token finché qualcuno non lo ferma.
Modelli proprietari, open source, sovrani: la scelta che pesa per anni
Il primo bivio architetturale di un progetto agentico è la scelta del modello su cui costruirlo. Le opzioni si raggruppano in tre famiglie distinte, ognuna con un profilo specifico di rischio e costo e controllo e conformità che vale la pena conoscere a fondo prima di firmare.
I modelli proprietari frontier
Sono quelli che oggi guidano i benchmark di qualità sui task agentici:
- la famiglia Claude di Anthropic (Opus 4.7 al top, Sonnet 4.6 nel mid-tier, Haiku 4.5 per task ad alto volume),
- GPT-5.5 di OpenAI con i suoi derivati ottimizzati (GPT-5.2-Codex per coding agentico, GPT-5 mini per task definiti),
- Gemini 3.1 Pro di Google con la sua finestra di contesto da un milione di token. Sono accessibili solo via API dei vendor (eventualmente attraverso hyperscaler partner come AWS Bedrock, Azure AI, Google Vertex).
Il pricing varia su tre ordini di grandezza: si va dai 5 dollari per milione di token in input di Claude Opus o GPT-5.5 ai 25 dollari per milione di token in output dei modelli di punta, scendendo fino a 0,10 dollari per milione di input per modelli ad alto volume come Gemini 2.5 Flash-Lite. Per una panoramica aggiornata si veda la comparazione DevTk di maggio 2026.
I modelli open source “seri”
Sono quelli scaricabili e eseguibili su infrastruttura controllata dall’azienda. Llama 4 di Meta, Mistral Large 3 (architettura mixture-of-experts da 675 miliardi di parametri, contesto da 256k token, licenza Apache 2.0), DeepSeek V4 cinese con prezzi pubblici stracciati, Qwen di Alibaba.
Negli ultimi diciotto mesi hanno chiuso il gap di qualità rispetto ai modelli proprietari su molti task pratici, soprattutto sull’uso di strumenti e il ragionamento strutturato. La differenza pesa altrove: nessuna dipendenza esterna, deployment on-premise possibile, controllo totale sui prompt e sui dati, costi di inferenza diversi (l’infrastruttura va comprata, non affittata, ma il costo per token su workload sostenuti è una frazione del prezzo via API).
I modelli sovrani europei e italiani
Sono una sottocategoria degli open source con un mandato politico-industriale specifico. Mistral è oggi il primo attore europeo capace di competere direttamente con i modelli di frontiera americani, con clienti enterprise come BNP Paribas, AXA, Stellantis e contratti per centinaia di milioni di euro.
In Italia, il progetto Minerva sviluppato dal gruppo Sapienza NLP guidato da Roberto Navigli nell’ambito di FAIR, addestrato sul supercomputer Leonardo del Cineca con fondi PNRR, è il primo LLM italiano costruito da zero per la lingua italiana: 7 miliardi di parametri, 1,5 trilioni di parole nel corpus di addestramento, fonti completamente trasparenti. Navigli ne ha rivendicato esplicitamente la specificità: «La caratteristica distintiva dei modelli Minerva è il fatto di essere stati costruiti e addestrati da zero usando testi ad accesso aperto, al contrario dei modelli italiani esistenti ad oggi, che sono basati sull’adattamento di modelli come LLaMA e Mistral, i cui dati di addestramento sono tuttora sconosciuti». Sul Cineca girano anche Velvet di Almawave (verticali su sanità, finanza, PA), Modello Italia di iGenius (PA), il modello di Translated per la traduzione automatica.
A monte delle scelte tecniche, va capito un dato strategico per chi lavora in Italia: il progetto OpenEuroLLM, guidato dall’Università Carolina di Praga con Cineca come partner italiano, sta sviluppando un LLM open source sovrano europeo, AI Act-compliant, addestrato su lingue e dati europei. Una prima versione con qualche decina di miliardi di parametri è attesa entro fine 2026, la versione definitiva con centinaia di miliardi di parametri arriverà a febbraio 2028.
È un orizzonte temporale che le aziende devono inserire nel proprio piano: chi sceglie oggi un modello proprietario americano dovrebbe sapere che entro 24 mesi avrà un’alternativa sovrana credibile, e dovrebbe disegnare l’architettura in modo da poter migrare senza rifondere tutto.
Quale modello scegliere
La domanda operativa per il CIO che deve decidere è la seguente. Per task ad alta qualità e basso volume (analisi documentale complessa, ragionamento legale, decisioni che richiedono giudizio), il modello proprietario frontier è oggi la scelta più razionale: la differenza di qualità giustifica il costo unitario alto perché il volume è contenuto.
Per task ad alto volume e qualità sufficiente (classificazione automatica, estrazione strutturata di dati, sintesi e customer service di primo livello), il modello open source eseguito su infrastruttura controllata diventa convincente: il costo per task crolla, il volume genera il ROI.
Per task con vincoli forti di sovranità (PA e sanità o banca con dati sensibili), il modello sovrano europeo è la traiettoria politicamente sostenibile, anche se oggi paga un gap di qualità su alcuni benchmark.
Una buona architettura del 2026 quasi mai usa un solo modello. Usa il pattern del routing: una logica leggera decide, per ogni richiesta in arrivo, quale modello usare in funzione di complessità, sensibilità del dato, vincoli di latenza. Il 70% del traffico va su modelli economici e veloci (Haiku, Gemini Flash, Mistral Small), il 20% su modelli mid-tier (Sonnet, GPT-5.4, Mistral Large), il 10% sui frontier model per i casi davvero complessi.
Questo schema, riportato da studi su pricing API LLM nel 2026, riduce il costo per query medio del 60-80% rispetto a un’architettura che usa sempre il modello più potente.
Il Model Context Protocol, in pratica
Il Model Context Protocol è uno standard aperto per connettere agenti a sistemi e dati. Vale la pena entrare nel merito tecnico, perché MCP è uno dei dati più sottovalutati nel disegno di un progetto agentico, e diventerà uno dei criteri di scelta dei fornitori più rilevanti nei prossimi diciotto mesi.
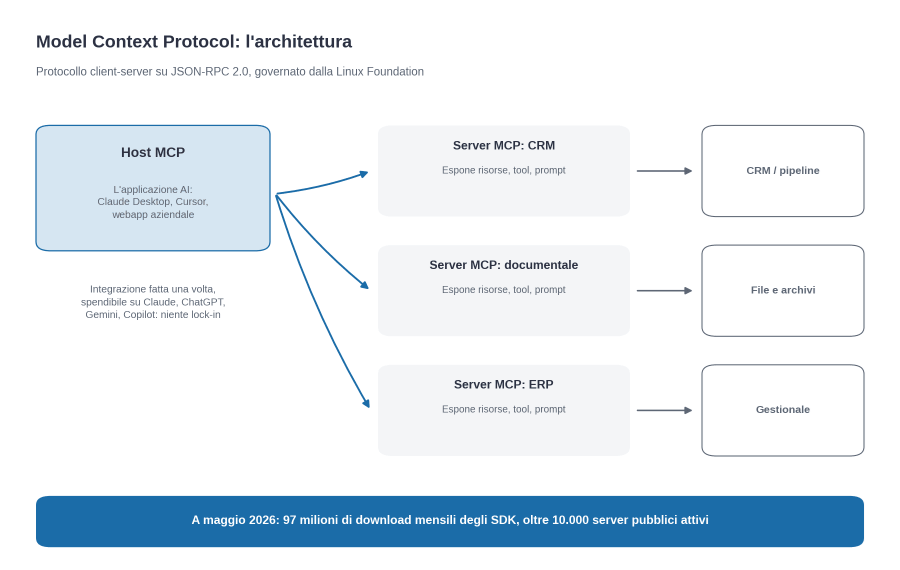
MCP è un protocollo client-server basato su JSON-RPC 2.0. Un’applicazione AI (un host MCP, ad esempio Claude Desktop, Cursor, una webapp aziendale che integra Claude o GPT) apre una connessione stateful con uno o più server MCP. Ogni server espone tre cose: risorse (file e record e documenti in strutture dati), tool (funzioni che l’agente può chiamare per leggere o agire), prompt (template di istruzioni riusabili). L’agente vede tutti i server MCP a cui è connesso come un pannello unificato di capacità: cerca le risorse di cui ha bisogno e recupera quelle pertinenti, poi esegue, attraverso un’unica grammatica.
La forza di MCP per le aziende è in tre punti.
- l’integrazione fatta una volta è spendibile su più vendor di modelli: un server MCP che espone il CRM aziendale funziona con Claude, ChatGPT, Gemini, Copilot, e con tutti i modelli che adotteranno MCP in futuro. Si elimina il rischio di lock-in sul fornitore di modelli, che è il rischio principale dell’AI enterprise.
- l’ecosistema cresce molto velocemente: server MCP pronti per GitHub, Slack, Google Drive, Postgres, Notion, Jira, Salesforce, HubSpot, e centinaia di altri sistemi.
- il protocollo è governato dalla Linux Foundation attraverso l’Agentic AI Foundation, con Anthropic, OpenAI, Block come founding members e supporto di Google, Microsoft, AWS. Vendor neutrality strutturale.
Le numeriche sono inequivocabili. A maggio 2026 MCP ha superato 97 milioni di download mensili degli SDK, oltre 10mila server pubblici attivi, supporto nativo da Claude, ChatGPT, Gemini, Copilot, AWS Bedrock. Il 78% dei team AI enterprise con almeno 50 persone dichiara di avere almeno un agente MCP-based in produzione, e il 41% ha sviluppato server MCP interni custom per esporre sistemi proprietari. Per chi disegna oggi un’architettura agentica, ignorare MCP è una scelta che costerà rifattorizzazioni dolorose nei prossimi anni.
Sul fronte enterprise, la roadmap MCP 2026 affronta i nodi che pesano nei deployment seri: OAuth 2.1 con integrazione di identity provider (Okta, Azure AD) per i flussi di autenticazione in ambienti regolati, gestione di sessioni stateful in modalità stateless dietro load balancer per scaling orizzontale, MCP Server Cards per discovery e cataloghi enterprise, Tasks asincrone per workflow lunghi. La cadenza di rilascio è trimestrale, e ogni rilascio chiude un buco che oggi blocca casi d’uso reali.
Framework di orchestrazione, in modalità pragmatica
Il mercato dei framework di orchestrazione degli agenti è affollato e in movimento rapido. Vale la pena conoscere i nomi che ricorrono nelle conversazioni con i fornitori, sapendo che la scelta del framework è meno strategica di quella del modello e del protocollo: si può cambiare un framework in 6-12 settimane, cambiare modello o protocollo costa molto di più.
LangChain è il framework storico, partito nel 2022, oggi la libreria di riferimento per chiunque costruisca agenti in Python o JavaScript. Pro: documentazione vastissima, integrazioni con praticamente tutto, community grande. Contro: nelle versioni più recenti è diventato pesante, con un’API che cambia spesso, e in produzione richiede attenzione per non rallentare il sistema.
LangGraph, evoluzione di LangChain per orchestrazioni complesse, è oggi la scelta più diffusa per agenti multi-step seri. Modella l’agente come un grafo di stati: ogni nodo è un passo computazionale, gli archi sono le transizioni possibili. Vantaggio: il flusso dell’agente è leggibile e debuggabile. Svantaggio: curva di apprendimento più ripida rispetto al LangChain classico.
AutoGen, sviluppato da Microsoft Research, è focalizzato su sistemi multi-agente. Permette di disegnare conversazioni tra agenti specialisti (un agente coder, un agente reviewer, un agente product manager) che si coordinano per arrivare al risultato. È il framework più sofisticato per l’orchestrazione multi-agente, e quello che richiede la curva più alta.
CrewAI è l’alternativa Python più semplice per multi-agente, con un modello mentale vicino a quello di una squadra di lavoro umana: si definiscono i ruoli con i loro obiettivi, si assegnano i task, si raccolgono gli output. Buono per partire con sistemi multi-agente leggeri, meno adatto a scenari di produzione complessi.
Azure AI Foundry, AWS Bedrock Agents, Google Agent Builder sono le offerte managed degli hyperscaler. Pro: integrazione con il resto dello stack cloud, sicurezza enterprise, supporto contrattuale. Contro: lock-in più forte sul fornitore di cloud, meno flessibilità nel cambio di modello.
La regola pratica per chi sceglie: se il progetto è single agent o multi-agent semplice, LangGraph è oggi la scelta più equilibrata. Se è multi-agent complesso con coordinamento profondo, AutoGen vale lo studio. Se l’azienda ha già pesantemente investito su Azure, AWS o Google Cloud, le offerte managed degli hyperscaler riducono attriti operativi anche se costano in flessibilità futura.
Quattro voci di costo che spostano il bilancio AI
Il dato che fa più male nei progetti agentici è che il preventivo del fornitore quasi mai coincide con il costo reale a regime. Uno studio di Hypersense Software del 2026 stima che il budget medio enterprise sottovaluta il TCO di un agente del 40-60%. Vale la pena scomporre il costo in quattro voci, per arrivare al CFO con una stima sostenibile.
La prima voce è il costo dei token. Si calcola moltiplicando il volume di richieste mensili previsto per il costo medio per richiesta, considerando input e output. Una richiesta singola può andare da frazioni di centesimo (modelli a basso costo, prompt breve, output breve) a diversi centesimi (modelli frontier, contesto lungo, ragionamento esteso). Un dato di riferimento: un singolo agent session su Claude Sonnet con prompt di 200k token e output di 30k costa circa 1 dollaro. Su Claude Opus, la stessa sessione costa circa 4 dollari. Su un agente che fa 10 sessioni al giorno per 250 giorni l’anno, la differenza tra Sonnet e Opus è di 7.500 dollari l’anno solo per il modello. Per dieci agenti in produzione, è 75mila dollari. Vale la pena conoscere i propri pattern di uso, e fare benchmark veri prima di scegliere il modello.
La seconda voce è l’infrastruttura di supporto. Un agente RAG decente richiede un vector database per gli embedding della knowledge base: secondo studi 2026 sui TCO agentici si parla di 500-2.500 dollari al mese a seconda del volume di contenuti e della frequenza di query. Un agente che chiama tool esterni richiede gateway, rate limiting, retry logic, queueing: altri 200-1.000 dollari al mese. Un sistema di monitoraggio e osservabilità per gli agenti (tracciamento delle azioni, controllo della deriva, gestione dei loop infiniti) è essenziale a partire da 500-2.000 dollari al mese, e a livello enterprise diventa una piattaforma a parte. Sommate, queste voci portano l’infrastruttura di supporto a 10mila-40mila dollari l’anno per un agente in produzione seria.
La terza voce è il costo umano. L’agente in produzione richiede un product owner che lo governa (10-30% del tempo di una persona), un MLOps o AgentOps engineer che lo presidia tecnicamente (20-50% del tempo), tester e operatori che validano le azioni e gestiscono lo human-in-the-loop (variabile, dipende dal volume).
Per un agente “serio”, la quota persone va da 30mila a 100mila euro l’anno solo per la presenza minima sostenibile, esclusa la quota di costruzione iniziale. La quota costruzione, per un agente production-grade in contesto regolato, parte da 60mila euro e può superare i 300mila secondo stime 2026 di FifthRow, con integrazione e governance che assorbono fino al 60% del budget di progetto.
La quarta voce è il costo della deriva. Un agente che funziona oggi non è detto che funzioni tra sei mesi: cambiano i dati su cui lavora, cambia il modello sottostante (i vendor aggiornano e a volte deprecano versioni), cambiano i sistemi che integra, cambiano le aspettative degli utenti. La manutenzione e l’evoluzione di un agente vale tipicamente il 20-50% del costo di costruzione iniziale, ogni anno. È la voce più sottovalutata, perché non compare nel preventivo del fornitore e si manifesta solo dopo che la fase di rilascio si è chiusa.
Mettendo insieme le quattro voci, un agente production-grade in azienda italiana media costa tra 30mila e 150mila euro l’anno per essere mantenuto operativo, esclusa la quota di costruzione iniziale che parte da 60mila euro. È un ordine di grandezza utile per smontare le aspettative inflazionate dei sales pitch e per costruire business case sani fin dall’inizio.
Quanto costa davvero: tre scenari concreti
Per ancorare i numeri, vale la pena lavorare su tre scenari realistici, ognuno con un pattern di uso tipico e un calcolo TCO grossolano sull’anno.
Scenario PMI italiana
La Pmi taglia 50-150 dipendenti, primo agente in produzione su un caso d’uso ben scoping (ad esempio: agente per il triage delle richieste di customer support che lavora su un volume di 500 richieste al giorno, classifica e propone risposta, con escalation umana sopra soglia di confidenza).
Modello: Haiku 4.5 o Gemini Flash, costo token stimato 800-1.500 euro all’anno. Infrastruttura: una piccola istanza managed cloud, vector DB minimo, totale 5mila-8mila euro l’anno.
Persone: 15-20% di un PM, 10-15% di uno sviluppatore, supervisione da operations, totale 20mila-30mila euro.
Deriva e manutenzione: 15-20% sulla costruzione iniziale, 8mila-12mila euro.
TCO annuo: 35mila-55mila euro.
Costo di costruzione iniziale: 40mila-70milaeuro.
Una PMI italiana che faccia il primo agente “bene” parte con un budget di 100mila euro nel primo anno e di 50mila euro all’anno dal secondo.
Scenario grande impresa
La grande impresa taglia 500-2.000 dipendenti, tre agenti in produzione su workflow documentali, customer ops, IT interno.
Modelli: routing tra Haiku per il 70% del volume e Sonnet per il 30%, costo token totale 8.000-15.000 euro l’anno. Infrastruttura: piattaforma agentica enterprise con vector DB enterprise, gateway e osservabilità integrate, totale 40.000-80.000 euro l’anno.
Persone: team dedicato di tre persone tra PM, MLOps engineer, operations lead, totale 200mila-300mila euro l’anno.
Deriva e manutenzione: 60mila-120mila euro l’anno.
TCO annuo: 300mila-500mila euro.
Costo di costruzione iniziale per tre agenti: 200mila-400mila euro.
Una grande impresa con tre agenti in produzione spende il primo anno tra 500mila e 900mila euro, dal secondo tra 300mila e 500mila euro.
Scenario PA regolata
Dirigente di amministrazione locale o sanità, primo agente assistito su workflow di estrazione e classificazione documentale (ad esempio: triage delle istanze in ingresso al protocollo, classificazione automatica, instradamento all’ufficio competente).
Modello: per vincoli di sovranità si valuta Minerva o Mistral self-hosted su infrastruttura controllata, oppure un modello proprietario via hyperscaler con clausole di residenza dei dati in UE.
Infrastruttura: GPU dedicate o servizio managed con SLA contrattualizzati, 30mila-80mila euro l’anno.
Persone: due dipendenti dedicati (un PM, un tecnico), più consulenza esterna, 120mila-180mila euro l’anno tra costi interni e fornitori.
Conformità: audit, documentazione AI Act, valutazione del rischio, 15mila-30mila euro l’anno.
TCO annuo: 200mila-300mila euro.
Costo di costruzione iniziale, considerando i vincoli di gara, 150mila-250mila euro. È il caso in cui il PNRR può fare la differenza, perché parte di questi costi possono essere coperti da bandi e fondi dedicati.
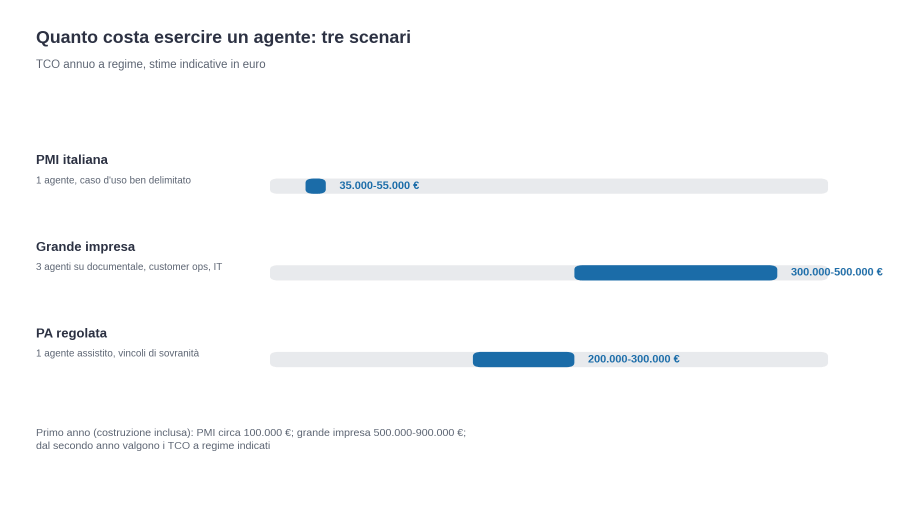
Tre scenari, tre ordini di grandezza diversi. La lezione operativa: non esiste un “costo medio” dell’agente, esistono profili di costo precisi che cambiano con la taglia, il settore, i vincoli di compliance. Chi propone un costo unico è quasi sempre un fornitore che sta vendendo qualcosa.
Sovranità digitale e conformità: i confini del 2026
L’ultima parte tocca un punto che a prima vista sembra giuridico, ma che invece è profondamente architetturale: dove vivono i dati quando l’agente ragiona, e chi ha il potere di vederli.
Quando un agente chiama un modello via API di Anthropic, OpenAI, Google, i dati del prompt vanno sui server del fornitore, vengono processati, restituiti. I tre vendor hanno politiche di non-retention dei dati API (i prompt non vengono usati per riaddestrare i modelli e vengono cancellati entro tempi definiti), opzioni di residenza in Europa, certificazioni SOC 2 e ISO 27001. Per la maggior parte dei casi d’uso aziendali, queste garanzie sono sufficienti. Per casi d’uso con dati sensibili (sanitari, finanziari sopra soglia di rischio, giudiziari e pubblica amministrazione che gestisce dati di cittadini), le garanzie contrattuali standard non bastano: serve la possibilità tecnica di eseguire l’inferenza dentro la propria infrastruttura.
È qui che entra in gioco la sovranità digitale come scelta architetturale. Mistral con licenza Apache 2.0, Llama di Meta, Minerva di Sapienza-Cineca, gli altri modelli sovrani europei sono disegnati esplicitamente per consentire il self-hosting senza dipendenze esterne. L’azienda compra o affitta GPU (NVIDIA H200 oggi, Blackwell B200 da metà 2026), installa il modello, lo esegue dentro le proprie mura digitali. I dati non escono mai, l’inferenza è auditabile end-to-end, la giurisdizione è quella dell’azienda.

Il costo della sovranità è reale, ma è meno alto di quanto si pensi. Uno studio Lenovo del 2026 calcola che, su un orizzonte di cinque anni e con utilization superiore al 20% delle GPU, il TCO on-premise può essere fino a 18 volte più conveniente del Model-as-a-Service via API per workload sostenuti. La condizione è il volume: sotto una certa soglia di inferenza, il managed cloud resta più economico. Sopra, il self-hosting diventa irresistibile.
Per una grande impresa o una PA con volumi sostenuti, l’analisi va fatta caso per caso, ma il break-even è molto più vicino di quanto i fornitori di modelli proprietari raccontino.
Sul fronte conformità, l’AI Act europeo classifica come ad alto rischio gli agenti che operano su scelte rilevanti per le persone in settori come lavoro, accesso a servizi essenziali, giustizia, gestione delle infrastrutture critiche. Per questi agenti, la documentazione tecnica, la valutazione del rischio, il sistema di gestione della qualità, la conservazione dei log diventano obblighi precisi.
La scelta del modello pesa: i modelli proprietari fornitori di API hanno politiche di trasparenza limitata sulle modalità di training, sui dati usati, sui meccanismi di sicurezza interni. I modelli sovrani come Minerva nascono con la trasparenza incorporata, cosa che semplifica enormemente le risposte alle richieste regolatorie.
Cosa portare a casa, e cosa decidere prima di firmare
Sotto il cofano di un agente AI ci sono cinque decisioni che il CIO non può delegare al fornitore, e che valgono di più di tutta la parte di prodotto. Si possono ridurre a cinque domande operative.
- Quale loop ho disegnato, e quanti cicli può fare un mio agente prima di fermarsi? Senza un tetto esplicito al numero di iterazioni del loop percezione-decisione-azione, l’agente può andare in deriva. La risposta deve essere scritta nel system prompt, monitorata, allertata.
- Quale modello uso, e perché? Frontier proprietary per qualità su volumi bassi, open source per costi su volumi alti, sovrano per vincoli di compliance e dati sensibili. La risposta non è un’unica scelta, è un’architettura di routing.
- Uso MCP o sto investendo in integrazioni proprietarie? Nel 2026 la risposta corretta è MCP, perché riduce il lock-in sul fornitore di modelli e perché il 78% dei team enterprise lo ha già adottato. Andare contro è una scelta di nicchia che va giustificata.
- Quale framework di orchestrazione e quale exit strategy? LangGraph per gli agenti seri, AutoGen per multi-agent complesso, hyperscaler managed per chi è già investito sul cloud. In ogni caso, scegliere prevedendo che entro 24 mesi si potrà cambiare framework senza riscrivere tutto.
- Quanto costa davvero, e per quanti anni? Non il preventivo del fornitore, il TCO reale: token, infrastruttura, persone, deriva. Per un agente serio in azienda italiana, si parte da 30mila euro all’anno per il caso più semplice, si arriva a 500mila per scenari enterprise multi-agente. Il preventivo iniziale del fornitore va moltiplicato per 1,4 per arrivare a una stima realistica.
Senza dubbio è qui che si gioca la metà del successo di un progetto agentico nel 2026: nelle scelte di architettura che precedono il prodotto. La terza puntata della guida farà la mappa delle funzioni e dei settori in cui gli agenti lavorano davvero, e di quelli in cui restano prematuri.
Per chi ha avuto la pazienza di leggere fin qui, il regalo è una griglia di decisione che vale per i prossimi cinque anni di carriera AI in azienda.







Partecipa alla community