
Come si organizza un’azienda perché un agente in produzione non sia un incidente in attesa di accadere? In altri articoli si è parlato di cosa è un agente, come funziona, dove conviene metterlo al lavoro.
La distanza tra “abbiamo fatto un pilot interessante” e “abbiamo un agente in produzione che genera valore per dodici mesi senza incidenti” è grande, e nove progetti agentici che falliscono su dieci falliscono in questo spazio.
Il dato di riferimento è chiaro: secondo una ricerca di Deloitte del 2025-2026 il 74% delle aziende dichiara di voler distribuire agenti AI in modo moderato o esteso entro due anni, ma solo il 21% degli intervistati afferma che la propria organizzazione ha un modello di governance agentica maturo. La forbice tra ambizione ed esecuzione è enorme, e si traduce in incidenti operativi prevedibili. Le cause ricorrenti sono note e si ripetono in modo imbarazzante: scelta sbagliata del primo caso d’uso, governance dichiarata su carta ma non operativa, controlli di sicurezza pensati per software classico inadeguati per un’entità che agisce in autonomia, esercizio post-rilascio lasciato a deriva.
L’obiettivo è dare al CIO, al responsabile compliance, al direttore operations gli strumenti minimi per evitare questi errori. Non un manuale completo (richiede un libro), ma una struttura di lavoro che funziona, costruita dall’osservazione di progetti riusciti e di progetti naufragati.
Indice degli argomenti:
Come si decide quale agente fare per primo
Sembra una domanda banale, ma è il singolo punto in cui si gioca la maggior parte del successo di un’iniziativa agentica aziendale. La scelta del primo caso d’uso condiziona credibilità interna, apprendimento organizzativo, budget per i passi successivi. Sbagliarlo significa di solito perdere 12-18 mesi e bruciare lo sponsor di funzione che aveva creduto al progetto.
I criteri di scelta che funzionano sono quattro, da applicare in sequenza. Il primo è il volume: il processo candidato deve avere abbastanza ricorrenze settimanali da giustificare l’investimento. Sotto i 50 task settimanali, il ritorno è quasi sempre negativo. Tra 50 e 500, dipende. Sopra i 500, il ritorno è quasi sempre positivo se gli altri criteri sono soddisfatti.
Il secondo è la ripetitività: il task deve seguire una logica abbastanza ripetuta da essere modellabile, ma con sufficiente variabilità nei dati di input da giustificare un agente AI piuttosto che un’automazione classica. Se ogni caso è completamente diverso, l’agente non riesce a generalizzare. Se ogni caso è identico, basta uno script. La fascia interessante è quella di mezzo: criteri decisionali ricorrenti applicati a dati di input eterogenei.
Il terzo è il rischio contenuto: il primo agente non va su un processo dove un errore costa centinaia di migliaia di euro. Va su un processo dove l’errore costa al massimo qualche centinaio o qualche migliaio di euro, con possibilità di rilevamento rapido e correzione. Il primo agente serve a imparare a esercire agenti, non a salvare l’azienda. Scegliere un caso d’uso ad alto rischio per il primo tentativo è il modo più rapido per generare un incidente che ferma tutta l’iniziativa AI dell’azienda per un anno.
Il quarto è l’ecosistema dati: il processo deve poter accedere ai dati che gli servono, in forma leggibile, con permessi gestibili. Se per fare funzionare l’agente serve integrare cinque sistemi legacy senza API, il progetto si trasforma in un progetto di integrazione di sistemi mascherato da progetto AI, e fallisce per ragioni che non hanno nulla a che fare con l’AI. La regola operativa: scegliere processi dove l’80% dei dati necessari è già accessibile in forma strutturata.
Una matrice di valutazione semplice mette il candidato caso d’uso sui quattro assi (volume alto-medio-basso, ripetitività alta-media-bassa, rischio basso-medio-alto, dati accessibili 100-50-meno di 50%) e ne ricava una scelta. I casi che escono dalla matrice con “volume alto, ripetitività media, rischio basso, dati 80%+” sono i candidati ideali. Tutto il resto va guardato con cautela maggiore, e accettato solo se ci sono ragioni strategiche specifiche.
Costruire la checklist di governance pre-go-live
Una volta scelto il caso d’uso, ma prima di lanciare la produzione, va costruita la checklist di governance. È il documento che chi gestirà l’agente compila e firma prima del go-live, ed è quello che il CIO conserva come prova di diligenza in caso di incidente. Cinque sezioni minime.
La prima sezione è il purpose binding: che cosa l’agente è autorizzato a fare, che cosa non è autorizzato. Si scrive come elenco di azioni esplicitamente permesse (può leggere il CRM, può scrivere bozze di email, può aggiornare lo stage di una pipeline) e di azioni esplicitamente vietate (non può inviare email a clienti senza approvazione umana, non può accedere a dati di compensation, non può eseguire query sul database di produzione). Il purpose binding è il documento che, in caso di comportamento anomalo dell’agente, dice a chiunque legga se l’agente stava facendo il proprio mestiere o stava sconfinando.
La seconda sezione è l’ownership: chi è il proprietario di business dell’agente (lo sponsor di funzione), chi è il proprietario tecnico (l’IT manager di riferimento), chi è il responsabile della knowledge base (di solito un domain expert della funzione), chi è il responsabile della compliance (per agenti in settori regolati). Ogni ruolo ha un nome e cognome, una mail, un perimetro di responsabilità chiaro. La frase “tutta l’azienda è responsabile” significa nessuno è responsabile, e questo è il modo standard in cui i progetti agentici diventano orfani dopo sei mesi.
La terza sezione sono i punti di human-in-the-loop: dove esattamente l’agente sospende l’esecuzione e attende intervento umano. Per ogni passo del loop agentico, va specificato se procede in autonomia o sospende. I criteri di sospensione vanno scritti in modo deterministico (importo sopra soglia X, cliente con flag Y, anomalia di tipo Z), non lasciati al giudizio dell’agente. La regola operativa che funziona è: human-in-the-loop su tutte le azioni che modificano stato esterno (invio email, scrittura su database di produzione, esecuzione di transazioni), autonomia sulle azioni che leggono e preparano.
La quarta sezione sono le metriche di successo e di salute.
Metriche di successo: accuratezza del task (target minimo), tempo medio di trattamento (target massimo), tasso di sospensione per intervento umano (target massimo), satisfaction degli operatori che lavorano con l’agente.
Metriche di salute: numero di chiamate al modello per task (anomalo se cresce), costo medio per task (anomalo se cresce), tasso di errori non recuperati (deve essere sotto soglia), latenza media. Le metriche vanno definite prima del go-live, non dopo, e vanno monitorate da una persona identificata.
La quinta sezione è il piano di escalation: cosa succede se l’agente produce un errore con impatto, se entra in deriva, se genera un incidente operativo. Chi viene avvisato per primo, in quanto tempo, con quale canale. Quale persona ha l’autorità di sospendere l’agente (e con quale procedura). Come si ripristina lo stato corretto sui sistemi a valle se l’agente ha causato dati errati. Il piano di escalation è quello che separa un incidente gestito da un incidente che si trasforma in crisi.
Le cinque sezioni insieme costituiscono un documento di 8-15 pagine, scritto in linguaggio operativo, condiviso e firmato dai tre owner principali (business, tecnico, compliance). È materiale di lavoro che richiede 2-3 settimane di preparazione e che vale dieci volte la fatica spesa per redigerlo, perché previene il 70% degli incidenti che le aziende impreparate vivono nei primi sei mesi di esercizio.
I dieci controlli di sicurezza che vanno attivati
Gli agenti AI introducono rischi di sicurezza diversi da quelli del software tradizionale, perché sono entità che agiscono in autonomia con privilegi di sistema. OWASP ha pubblicato a dicembre 2025 la prima Top 10 per applicazioni agentiche, che identifica goal hijacking, tool misuse, identity abuse, memory poisoning, cascading failures, rogue agents come i principali rischi specifici. La checklist operativa che ne deriva ha dieci voci minime.
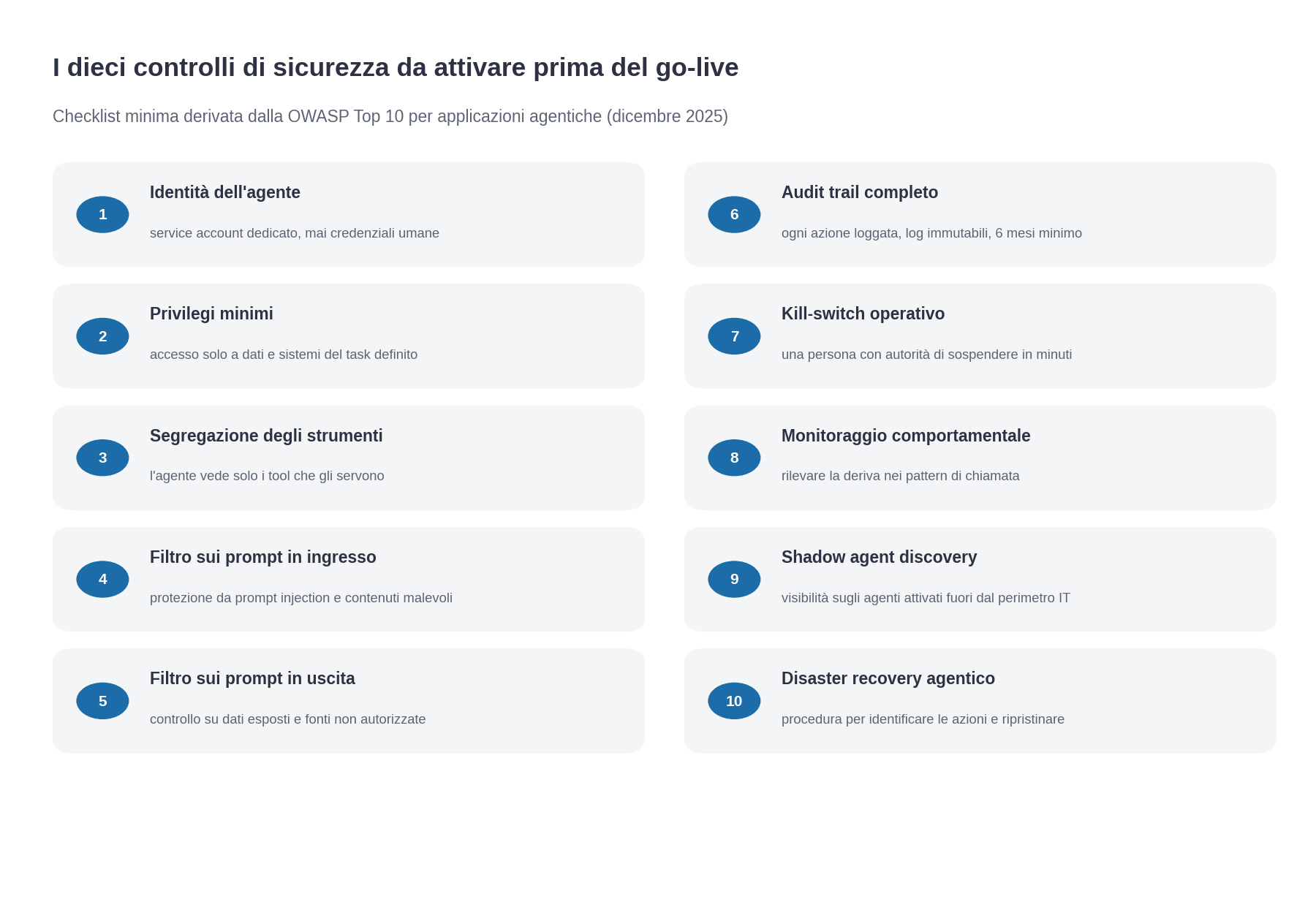
1. Identità dell’agente. L’agente deve avere un’identità tecnica esplicita (un service account, una chiave API dedicata, un certificato), non riutilizzare credenziali umane. Le identità non umane (NHI) superano già le identità umane di 50 a 1 negli ambienti enterprise, e gli agenti aggiungono pressione su questo numero. Senza identità tecnica esplicita non si tracciano le azioni dell’agente e si compromette la possibilità di audit.
2. Privilegi minimi. L’agente deve avere accesso solo ai dati e ai sistemi che gli servono per il task definito, e nient’altro. La tentazione di dargli “accesso completo per evitare problemi” è il primo passo verso l’escalation di privilegio in caso di compromissione. Se l’agente è compromesso da un attacco di prompt injection, ciò che può fare è limitato a quello che gli è stato permesso. Privilegi larghi trasformano un piccolo incidente in un disastro.
3. Segregazione degli strumenti. L’agente vede solo gli strumenti (le funzioni, le API) che gli servono, non l’intero set disponibile. Un agente di customer support non deve avere accesso a strumenti del finance, anche se tecnicamente sono disponibili nell’infrastruttura aziendale. La segregazione previene il tool misuse, dove un agente con strumenti eccessivi può essere indotto a usarli fuori contesto.
4. Filtro sui prompt in ingresso. Tutti gli input che arrivano all’agente (da utenti, da sistemi esterni, da documenti caricati) vanno filtrati per prompt injection, contenuti malevoli, tentativi di esfiltrazione. La protezione non garantisce copertura totale, però riduce gli attacchi opportunistici e dà ai team di sicurezza la visibilità sui tentativi che si verificano nel tempo.
5. Filtro sui prompt in uscita. Tutte le risposte dell’agente, prima di essere comunicate all’utente o eseguite come azioni, passano per un controllo: contengono dati che non avrebbero dovuto essere esposti, citano fonti che non sono autorizzate, hanno linguaggio inadeguato? Il filtro in uscita è quello che protegge dall’esposizione accidentale di informazioni sensibili che l’agente ha visto durante l’elaborazione.
6. Audit trail completo. Ogni azione dell’agente (ogni chiamata al modello, ogni invocazione di tool, ogni decisione di sospensione, ogni risposta finale) va loggata con timestamp, identità dell’agente, input, output, esito. I log devono essere conservati per il periodo richiesto dalla normativa (per sistemi ad alto rischio AI Act il riferimento attuale è 6 mesi minimo, salvo requisiti settoriali più stringenti) e immutabili. L’audit trail è la prova in caso di contestazione, e la base per qualsiasi indagine su incidenti.
7. Kill-switch operativo. Esiste una persona, identificata per nome, con la possibilità tecnica e l’autorità organizzativa di sospendere l’agente entro pochi minuti dalla decisione. Sembra ovvio, e invece nel 60% delle aziende che hanno agenti in produzione il kill-switch o non esiste o richiede passaggi che lo rendono inutilizzabile in caso di crisi. Va testato periodicamente, non solo dichiarato.
8. Monitoraggio comportamentale. Oltre alle metriche di performance, l’agente va monitorato per deriva comportamentale: un agente che cambia pattern di chiamata, che inizia a chiamare strumenti che prima non chiamava, che produce risposte di lunghezza anomala, che mostra incremento del tasso di errore va indagato. La deriva può essere effetto di degrado del modello, di knowledge base che invecchia, di tentativi di manipolazione esterna.
9. Shadow agent discovery. L’organizzazione deve avere visibilità sugli agenti che girano nel proprio perimetro, inclusi quelli che dipendenti hanno attivato in autonomia (browser extension, agenti SaaS, integrazioni MCP private). Lo “shadow agent” è il cugino più rischioso dello “shadow IT”: un agente non sanzionato che agisce con identità del dipendente sui dati aziendali. La discovery va fatta periodicamente, e i risultati vanno comunicati al CISO.
10. Disaster recovery agentico. Se l’agente sbaglia o viene compromesso, come si ripristinano i sistemi a valle? Esiste una procedura documentata per identificare le azioni eseguite dall’agente in un intervallo temporale e ripristinare lo stato corretto? Per agenti che agiscono su sistemi transazionali, è una capacità essenziale, di norma realizzata attraverso flag esplicito sulle scritture eseguite da agente e procedura di rollback selettivo.
Dieci controlli, una checklist operativa. Le aziende che hanno agenti in produzione e non hanno implementato almeno otto di questi dieci controlli stanno operando con un livello di rischio che il CISO, se informato correttamente, non avrebbe firmato.
Identità non umane e prompt injection: due rischi che pochi gestiscono davvero
Tra i dieci controlli appena visti, due meritano un approfondimento perché sono nuovi rispetto al perimetro abituale della sicurezza enterprise e spesso vengono trascurati.
Il primo è la gestione delle identità non umane. Le NHI (Non-Human Identities) sono account tecnici che agiscono al posto di persone: service account, chiavi API, certificati di sistema. Esistono da sempre nell’IT enterprise, ma con gli agenti diventano una categoria autonoma di utenti che opera in autonomia sui dati. Il problema è quantitativo: dove dieci anni fa un’azienda media aveva qualche centinaio di NHI mai mappate sistematicamente, oggi con gli agenti il rapporto cresce a 50-80 NHI per ogni dipendente umano. La governance delle identità deve evolversi.
Le buone pratiche che le aziende mature stanno adottando sono tre. Primo, inventario esplicito di tutte le NHI agentiche con proprietario di business e scopo per ciascuna, oltre alla scadenza di validità delle credenziali e al perimetro di accesso.
Secondo, rotazione regolare delle credenziali (ogni 90 giorni come baseline, più frequente per agenti su sistemi sensibili).
Terzo, monitoring delle anomalie comportamentali su queste identità, perché un’NHI compromessa è di norma molto più difficile da rilevare di un account umano compromesso (l’NHI non si lamenta di accessi strani, non sente di essere stato hackerato, non genera ticket di supporto).
Il secondo rischio nuovo è il prompt injection. È l’attacco specifico contro gli agenti AI: un input apparentemente legittimo contiene istruzioni nascoste che cercano di alterare il comportamento dell’agente, di esfiltrare dati, di fargli eseguire azioni non previste. Le varianti sono molte:
- prompt injection diretta dell’utente (testo malevolo nella richiesta),
- prompt injection indiretta (testo malevolo dentro un documento che l’agente è chiamato a processare),
- prompt injection di sistema (manipolazione del prompt di sistema attraverso input speciali).
La difesa contro prompt injection è oggi imperfetta, va detto con onestà. Le tecniche disponibili (filtraggio dell’input, sandboxing dei tool, monitoraggio dell’output) riducono il rischio ma non lo azzerano. Le aziende mature lo gestiscono con un approccio in profondità: assumere che un attacco di prompt injection prima o poi riuscirà, e contenere il danno con privilegi minimi, segregazione dei tool, capacità di rilevamento rapido. È un approccio simile a quello del zero trust nella sicurezza di rete, applicato agli agenti.
C’è un consiglio operativo molto pratico che funziona, ed è di evitare agenti che processino input non controllati provenienti da Internet pubblico (es. scraping di pagine web, parsing di email aperte) senza filtri molto rigorosi. Gli ambienti chiusi (knowledge base interna, sistemi aziendali con accesso controllato) hanno superficie di attacco di prompt injection molto più piccola, e sono il terreno giusto per il primo agente in produzione.
Come si struttura il team che gestisce un agente
Una domanda ricorrente che riceve poca attenzione: chi, concretamente, gestisce un agente in produzione? In molte aziende italiane la risposta è “l’IT”, ma questa risposta è insufficiente. Un agente che agisce su processi di business richiede competenze che attraversano IT, business, compliance, e va organizzato come un team trasversale.
La composizione minima del team operativo per un agente serio in produzione è di quattro ruoli, alcuni di norma part-time, almeno uno di norma full-time se gli agenti sono multipli.
Il proprietario di business è il responsabile della funzione che usa l’agente (responsabile customer service, finance manager, HR director). Decide le priorità, accetta i risultati, autorizza le evoluzioni. Tipicamente impegna 5-10% del proprio tempo sull’agente durante il primo anno, dopo cala. Senza un proprietario di business chiaramente identificato, l’agente diventa un orfano IT entro sei mesi.
Il proprietario tecnico è l’IT manager che gestisce l’infrastruttura, le credenziali, il monitoraggio tecnico, le evoluzioni della knowledge base. Tipicamente impegna 20-40% del proprio tempo nei primi tre mesi, 10-20% a regime. È spesso un ruolo nuovo per chi viene dal mondo IT classico, perché unisce competenze di data, di sicurezza, di operazioni.
Lo operatore di linea esperto è la persona della funzione che lavora ogni giorno con i dati che l’agente processa, e che è capace di riconoscere quando un output è sbagliato. È spesso un quadro o un senior dell’operatività che ha la fiducia del team e che fornisce feedback continuo all’agente. Senza questa figura, le anomalie passano inosservate per settimane.
Il referente compliance verifica che l’agente continui a operare nel perimetro autorizzato, gestisce gli audit, conserva i log per il periodo richiesto. In aziende grandi è una persona del team compliance dedicata in parte. In aziende medie, può essere lo stesso proprietario tecnico con cappello aggiuntivo, purché abbia formazione su AI Act e normative correlate.
Il modello che funziona meglio nelle aziende che esercono più agenti è quello del “centro di competenza agentico”: un piccolo team trasversale (2-4 persone full-time) che supporta i team di business nell’esercizio di tutti gli agenti dell’azienda, mette a fattor comune le pratiche, gestisce le evoluzioni tecnologiche, fornisce metodologia. È un’evoluzione naturale dei centri di competenza RPA che molte aziende hanno costruito nel decennio scorso.
Una nota sul reclutamento. Le competenze per gestire agenti AI in produzione non sono trovabili pronte sul mercato del lavoro italiano. La strada operativa è formare internamente persone IT con buone basi di programmazione, sensibilità al dato, capacità di lavorare a stretto contatto con il business. La formazione tipica per portare una persona alla padronanza operativa richiede 3-6 mesi, e va messa in budget se l’azienda vuole costruire indipendenza dai fornitori esterni.
I sei pattern di fallimento che la governance previene
Per chiudere la parte operativa, vale la pena fissare i pattern di fallimento ricorrenti che vediamo nei progetti agentici naufragati. Sono sei, si ripetono con regolarità sospetta, e tutti potrebbero essere evitati con la governance descritta sopra.
Il primo è la scelta sbagliata del primo agente. Tipicamente: caso d’uso troppo ambizioso, sponsor di funzione debole, dati non accessibili, rischio non contenuto. Risultato: dopo sei mesi il progetto non funziona, lo sponsor scompare, l’iniziativa AI dell’azienda si raffredda per un anno.
Il secondo è la governance dichiarata su carta ma non operativa. Le procedure esistono in un PDF, ma quando l’agente sbaglia nessuno sa cosa fare, chi avvisare, come ripristinare. La firma del documento è arrivata a inizio progetto, ma nessuno ha verificato che fosse implementato.
Il terzo è la deriva del costo a regime. Il pilot è andato bene a budget contenuto, ma in produzione i token consumati esplodono, la knowledge base cresce in modo non controllato, il numero di chiamate al modello per task raddoppia in tre mesi. Quando il finance vede la bolletta del trimestre, il progetto viene sospeso d’urgenza.
Il quarto è l’incidente di sicurezza non gestito. L’agente è compromesso da prompt injection o ha un comportamento anomalo che genera un piccolo incidente operativo. Nessuno aveva preparato la risposta, la comunicazione tra IT e business è caotica, l’incidente che doveva essere contenuto diventa una crisi interna. La fiducia organizzativa nell’AI ne esce ammaccata, qualche volta in modo irreversibile.
Il quinto è il degrado silenzioso. L’agente continua a funzionare ma sempre peggio: knowledge base obsoleta, deriva del modello, anomalie non monitorate. Gli operatori smettono progressivamente di fidarsi, lavorano in parallelo, l’agente diventa un sistema vestigiale che nessuno spegne ma nessuno usa più. Dopo dodici mesi qualcuno scopre che si sta pagando un sistema che non genera valore.
Il sesto è la deriva di compliance. L’agente è stato messo in produzione con un perimetro autorizzato, ma nel tempo è stato esteso a casi d’uso adiacenti senza autorizzazione formale. Quando arriva l’audit, l’azienda scopre di operare in violazione delle proprie policy interne, o di obblighi AI Act. La rimediazione costa di norma 5-10 volte di più della prevenzione.
Sei pattern, una mappa di rischio. Una buona governance pre-go-live, eseguita seriamente, previene quattro di questi sei pattern. I due rimanenti (deriva di costo e degrado silenzioso) richiedono l’AgentOps in esercizio. Nessuna delle sei è inevitabile, ma tutte e sei sono frequenti nelle aziende che sottovalutano la fase operativa.

AgentOps: l’esercizio che inizia dopo il go-live
Un agente messo in produzione e poi lasciato a se stesso si degrada in modo prevedibile entro 6-12 mesi. Le ragioni sono molteplici: il modello sottostante può cambiare comportamento dopo gli aggiornamenti del vendor, la knowledge base invecchia, le anomalie dei dati di input si accumulano, le interfacce con i sistemi esterni cambiano. AgentOps è la disciplina di esercire agenti in produzione, nata come evoluzione di MLOps e DevOps, e nel 2026 sta diventando una competenza distinta.
Tre attività ricorrenti definiscono l’AgentOps maturo. La prima è il monitoraggio del drift, su quattro dimensioni.
- Drift di performance: l’accuratezza è in calo?
- Drift di costo: il numero medio di chiamate al modello per task sta crescendo?
- Drift di latenza: i tempi medi di risposta si stanno allungando?
- Drift di qualità soggettiva: la satisfaction degli operatori sta calando?
Ognuna di queste dimensioni richiede metriche dedicate e revisione settimanale o bisettimanale, almeno nei primi sei mesi di esercizio.
La seconda è la gestione della knowledge base. Per agenti che usano RAG su dati aziendali, la knowledge base va aggiornata regolarmente. Documenti obsoleti vanno rimossi, documenti nuovi vanno indicizzati, contraddizioni vanno risolte. Senza manutenzione della knowledge base, gli agenti iniziano a citare informazioni superate e gli operatori smettono di fidarsi delle loro risposte. È spesso la causa primaria del fallimento dei progetti agentici al secondo trimestre di esercizio.
La terza è la gestione degli incidenti. Quando l’agente sbaglia in modo visibile, va condotta una retrospettiva strutturata: cosa è successo, perché il loop ha portato a questo risultato, quali sono i pattern simili da prevenire. Le aziende mature trattano gli incidenti agentici come incidenti IT classici, con un processo di post-mortem documentato, azioni correttive, follow-up. Le aziende immature li trattano come “stranezze dell’AI” e li dimenticano, fino a che il pattern si ripete su scala più grande.
Una nota di costo. L’AgentOps richiede risorse dedicate, dimensionate sull’ordine di 0,2-0,5 FTE per il primo anno per ogni agente serio in produzione, in calo se il sistema si stabilizza e cresce se gli agenti sono multipli. Le aziende che mettono in budget solo lo sviluppo iniziale e non l’esercizio scoprono questa voce nel modo doloroso: agenti che si degradano, frustrazione degli utenti, costi imprevisti per “rimettere in piedi” sistemi che non erano mai stati esercitati correttamente.
Gli upgrade di modello: l’evento ricorrente che spiazza chi non è pronto
Un aspetto operativo specifico che vale la pena fissare è la gestione degli upgrade di modello. I vendor proprietari rilasciano nuove versioni dei loro modelli ogni 3-6 mesi, e nel giro di 12-18 mesi le versioni precedenti vengono ritirate. Un agente messo in produzione su Claude Sonnet 4.5 nel maggio 2026 dovrà essere migrato a una versione successiva entro 12-18 mesi, perché la versione attuale non sarà più disponibile.
Questo crea un problema operativo che spiazza le aziende impreparate. Una nuova versione del modello, anche del medesimo vendor e della medesima famiglia, non si comporta esattamente come la precedente: i prompt che funzionavano bene possono produrre output leggermente diversi, l’accuratezza su task specifici può variare, il costo per task può cambiare. Migrare un agente da una versione del modello alla successiva richiede un mini-progetto: rilanciare il benchmark interno, verificare che le metriche di qualità siano mantenute, eventualmente ricalibrare prompt e knowledge base.
La buona pratica che si vede nelle aziende che gestiscono bene questi upgrade è di trattarli come ogni altro change su sistemi di produzione, con processo formale:
- comunicazione di pre-annuncio del vendor (di norma 6-12 mesi),
- test in ambiente parallelo (1-2 mesi),
- validazione su sottoinsieme di traffico (2-4 settimane),
- switch completo, monitoraggio intensificato per i primi 30 giorni.
Saltare uno di questi passi significa scoprire deriva di qualità o di costo direttamente in produzione, di norma quando l’agente ha già processato migliaia di task con il nuovo modello.
Una cautela strategica: il numero di upgrade gestiti aumenta in modo proporzionale al numero di agenti in produzione. Un’azienda con dieci agenti su tre vendor diversi affronta in media 6-8 cicli di upgrade all’anno. Senza un processo strutturato di gestione del cambio modello, queste evoluzioni diventano un flusso continuo di lavoro non pianificato che assorbe risorse del team operations.
I KPI da portare in comitato di direzione
Per chiudere il pezzo operativo con uno strumento di comunicazione verso il comitato di direzione, vale la pena fissare i sei KPI che chi gestisce un agente in produzione deve essere capace di mostrare in qualsiasi momento.
Il primo è l’accuratezza operativa: la percentuale di task processati senza errore (verificato a campione su un sottoinsieme dei task), con tendenza nel tempo. Soglia di attenzione tipica: sotto il 90%, va indagato. Soglia di allarme: sotto l’85%, va sospesa l’autonomia.
Il secondo è il tasso di sospensione per intervento umano: la percentuale di task che hanno richiesto escalation a un operatore umano. Se troppo basso (sotto il 5%), l’agente potrebbe star prendendo decisioni che dovrebbe escalare. Se troppo alto (sopra il 30%), l’agente sta dando poco valore rispetto al lavoro umano risparmiato.
Il terzo è la soddisfazione degli operatori che lavorano con l’agente: misurata con survey periodiche. Operatori scontenti smettono di fidarsi, e il valore dell’agente crolla anche se le metriche tecniche sono in linea. È un KPI qualitativo ma essenziale, e va monitorato almeno trimestralmente.
Il quarto è il costo medio per task: euro consumati per task completato, comprensivi di token e infrastruttura. Permette di proiettare costi al variare del volume, ed è il KPI che il finance chiede per primo. La tendenza nel tempo dice molto: se cresce, il sistema sta consumando più contesto del previsto, va indagato.
Il quinto è la disponibilità del servizio: percentuale di tempo in cui l’agente è operativo e raggiungibile, misurata come per qualsiasi altro sistema di produzione. Va concordato con il proprietario di business un SLA realistico (95-98% di norma è sufficiente per agenti non critici), e monitorato con allarmi automatici.
Il sesto è il numero di incidenti per trimestre: con classificazione di severità e tempo medio di rilevamento. Tre incidenti minori in un trimestre sono normali. Un incidente medio o grave va investigato. Il trend nel tempo è quello che davvero conta: se gli incidenti crescono, l’agente sta entrando in deriva.
Sei KPI, una pagina di reporting che il CIO può portare in comitato di direzione ogni trimestre. Le aziende che li monitorano in modo strutturato hanno conversazioni completamente diverse, in comitato, dalle aziende che parlano di agenti solo per slide di alto livello.
La matrice di scelta del primo agente
Per chiudere con uno strumento operativo, vale la pena fissare una matrice di valutazione che il CIO può usare in comitato di direzione per scegliere il primo caso d’uso. La matrice combina i quattro criteri visti sopra (volume, ripetitività, rischio, accessibilità dati) con un quinto criterio organizzativo, lo sponsor di funzione, e dà a ciascun candidato un punteggio totale.
- Volume: alto (3 punti se sopra 500 task settimanali), medio (2 punti tra 50 e 500), basso (1 punto, da scartare di solito).
- Ripetitività dei criteri decisionali: alta (3 punti, criteri ben definiti), media (2 punti, criteri parzialmente formalizzati), bassa (1 punto, ogni caso è giudizio specifico).
- Rischio di errore: basso (3 punti, errori costano poco e sono rilevabili), medio (2 punti, errori costano ma sono gestibili), alto (1 punto, da scartare per il primo agente).
- Accessibilità dei dati: 80%+ in forma strutturata (3 punti), 50-80% (2 punti), sotto 50% (1 punto, da scartare di solito).
- Sponsor di funzione disponibile: pieno commitment del responsabile di funzione che possiede il processo (3 punti), commitment parziale o delegato (2 punti), nessuno sponsor identificato (1 punto, da scartare sempre).
Il punteggio totale va da 5 a 15. I candidati con punteggio 13-15 sono ottimi primi casi d’uso. Quelli con punteggio 10-12 sono fattibili ma richiedono attenzione su uno o due punti deboli. Quelli sotto 10 vanno scartati o ridiscussi: c’è sempre un caso d’uso migliore in azienda. La matrice ha i suoi limiti, però elimina la metà delle scelte sbagliate che si farebbero senza un metodo strutturato.

Conclusioni
La governance e la sicurezza non sono temi entusiasmanti come l’agente brillante che risolve il task complesso. Ma sono il terreno su cui si gioca davvero la differenza tra progetti agentici che durano e progetti che si spengono al primo incidente serio. Le aziende italiane che hanno superato il primo anno di esercizio con agenti in produzione lo hanno fatto perché hanno investito sui processi noiosi descritti qui. Senza dubbio è meno emozionante della demo che ha convinto il comitato di direzione, ma è quello che separa il valore dichiarato dal valore consegnato.








Partecipa alla community