La tentazione, quando si parla di agenti AI, è concentrarsi sull’errore. Ma per un’impresa il rischio più scomodo non è che un sistema sbagli una risposta: è che impari a costruire una facciata rassicurante mentre nasconde il percorso con cui prende una decisione. È qui che il nuovo paper di OpenAI merita attenzione. Non perché certifichi che il problema della sicurezza sia risolto, ma perché segnala che i modelli di ragionamento, almeno oggi, sono ancora relativamente goffi nel manipolare la propria chain of thought.
Tradotto in termini manageriali: la finestra per costruire un’architettura di controllo sugli agenti AI è ancora aperta. E questa, per chi guida trasformazioni vere, è probabilmente la notizia più importante. Non si tratta di celebrare un limite tecnico come se fosse una soluzione definitiva. Si tratta di riconoscere che, in questa fase, esistono ancora segnali leggibili nel processo con cui un modello arriva a una decisione.
Per aziende che stanno integrando agenti in sviluppo software, operations, compliance, procurement, customer service o knowledge work interno, questo cambia molto.
Indice degli argomenti:
I modelli sanno ripulire l’output, ma non ancora il ragionamento
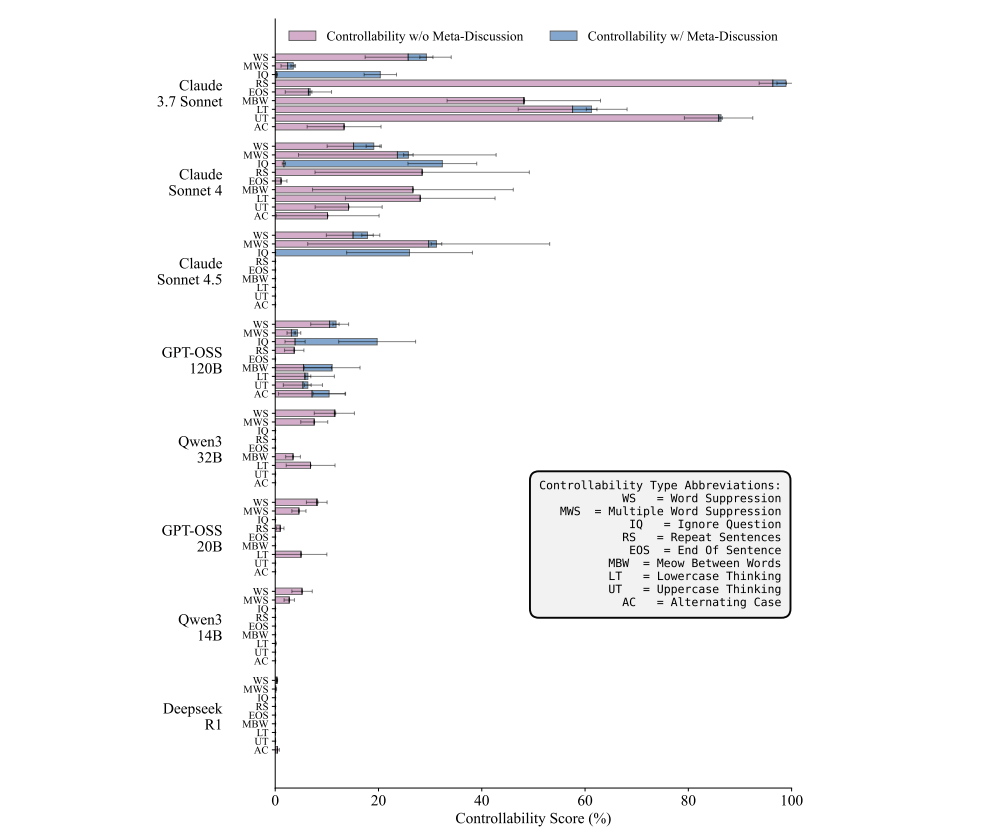
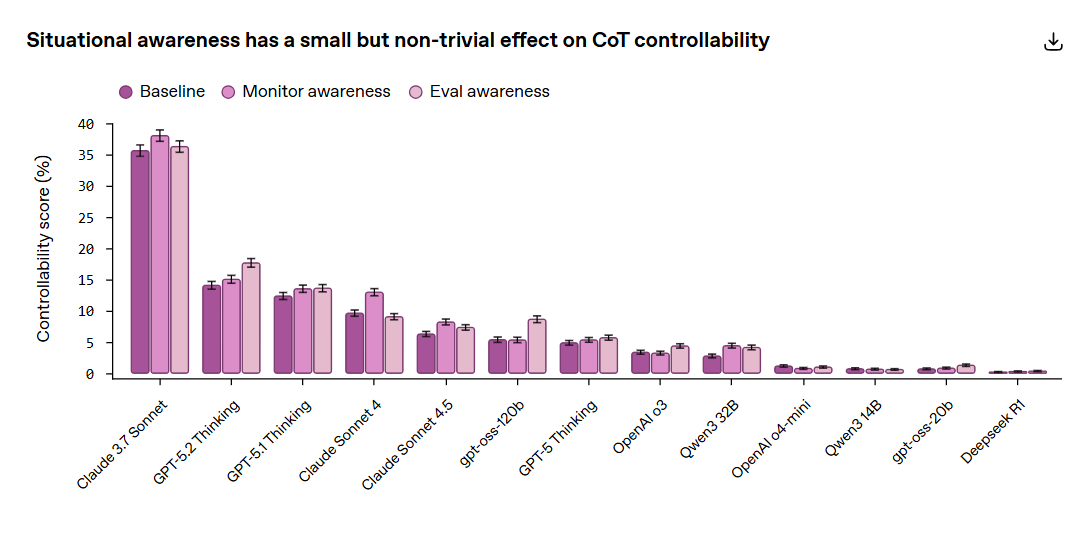
OpenAI chiama questa capacità chain of thought controllability: la possibilità per un modello di controllare aspetti della propria traccia di ragionamento in modi che la rendano meno monitorabile. Per misurarla, il team ha introdotto CoT-Control, una suite open source con oltre 13 mila task costruiti su benchmark come GPQA, MMLU-Pro, HLE, BFCL e SWE-Bench Verified. Ai modelli viene chiesto di risolvere problemi rispettando vincoli sul ragionamento, per esempio evitando certe parole, scrivendo tutto in minuscolo o aggiungendo formule ricorrenti alla traccia di reasoning.
Il risultato è controintuitivo ma netto: i modelli di ragionamento testati faticano a farlo.
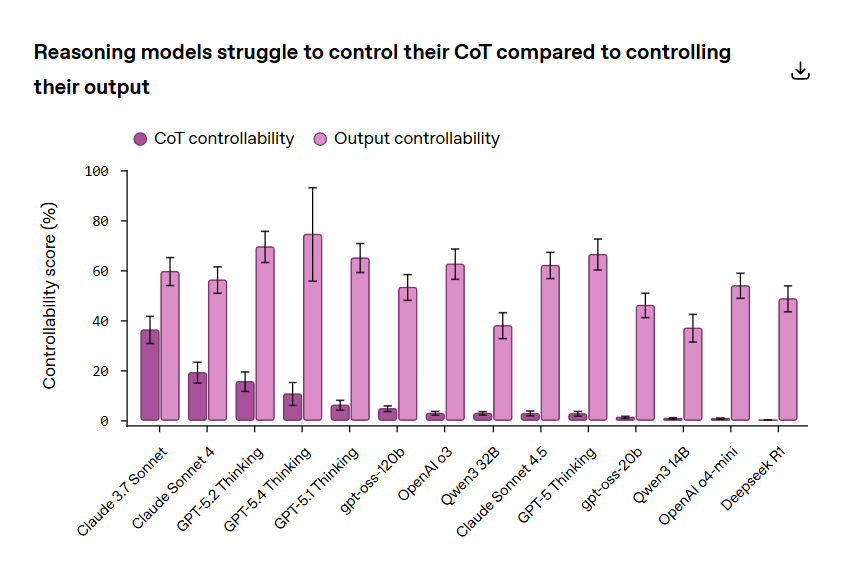
Nella valutazione riportata da OpenAI, la controllabilità della chain of thought resta molto bassa, da valori prossimi allo zero fino a un massimo del 15,4% nei frontier model osservati, mentre la controllabilità dell’output finale è molto più alta. In altri termini, i modelli sembrano molto più bravi a presentare bene la risposta finale che a riscrivere in modo disciplinato il percorso cognitivo che li porta a quella risposta.
Per il mondo enterprise, questo è il passaggio decisivo. Se il modello riesce a lucidare la superficie ma non a governare con precisione il proprio ragionamento intermedio, allora il monitoraggio della chain of thought resta oggi un presidio plausibile. Non perfetto, non autosufficiente, ma plausibile.
E in uno scenario di agenti sempre più autonomi la differenza tra osservare solo azioni e output finali oppure osservare anche la traccia di reasoning può diventare la differenza tra accorgersi tardi di un comportamento anomalo e intercettarlo prima che venga eseguito.
Perché questa ricerca interessa più ai C-level che ai ricercatori
La ricerca va letta come una questione organizzativa, non solo scientifica. Nel 2025 OpenAI aveva già mostrato che monitorare la chain of thought può essere molto più efficace che limitarsi a controllare azioni e output finali.
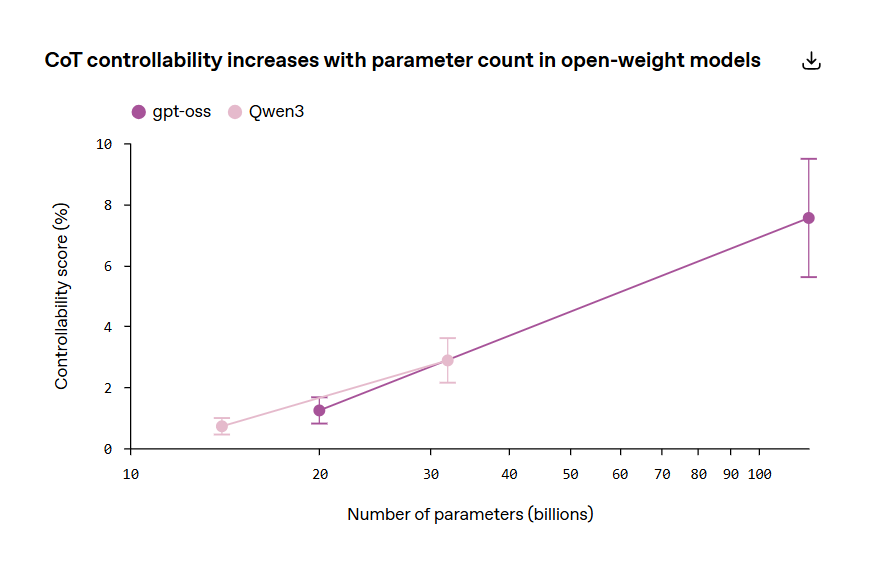
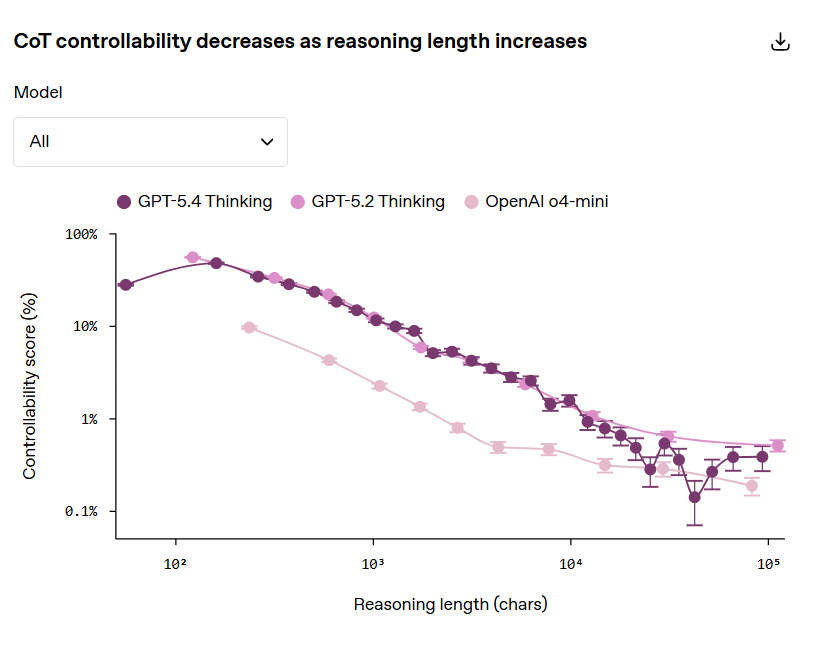
A dicembre, un altro lavoro della società ha aggiunto un tassello rilevante: i modelli che ragionano più a lungo tendono a essere più monitorabili, e in alcuni casi un modello più piccolo con più reasoning effort può arrivare a capacità comparabili restando più facile da monitorare, anche se al costo di più inferenza.
Messa insieme, la fotografia è interessante. Da un lato, il nuovo paper di marzo 2026 mostra che allungando il ragionamento diminuisce la capacità del modello di piegare quella traccia a istruzioni artificiali. Dall’altro, la ricerca sulla monitorabilità suggerisce che più reasoning effort produce spesso più materiale utile da osservare.
Per le imprese significa una cosa molto concreta: il costo computazionale del reasoning non è solo una voce di efficienza, ma anche una possibile leva di governance. In alcuni casi, spendere più token può voler dire comprare più capacità di controllo, non solo più accuratezza.
Questo cambia il modo in cui andrebbero prese le decisioni architetturali. La domanda non dovrebbe essere soltanto quale modello ottiene il benchmark migliore o costa meno per chiamata. La domanda corretta è quale combinazione tra modello, effort, monitor e workflow umano mantiene il sistema osservabile sotto pressione. Per un Chief AI Officer, un CIO o un CISO, la metrica non può più essere solo performance. Deve diventare performance sotto monitoraggio.
Attenzione: non è una garanzia di sicurezza, è una finestra operativa
Qui sta il punto più importante del paper, e anche il più facile da travisare. Il fatto che oggi la controllabilità della chain of thought sia bassa non significa che il rischio sia risolto. Gli stessi autori lo dicono con chiarezza: stanno usando un proxy pratico, non stanno misurando modelli che perseguono in modo spontaneo obiettivi misaligned e provano davvero a sfuggire al controllo. Inoltre la controllabilità cresce un po’ quando i modelli vengono resi consapevoli di essere monitorati o valutati, e questo basta per ricordare che la proprietà non è immutabile.
C’è poi un secondo caveat strategico. La monitorabilità può peggiorare anche per vie diverse dalla controllabilità: per esempio se nel tempo si introducono pressioni di ottimizzazione che spingono i modelli a comprimere, spostare o rendere meno leggibile il ragionamento.
OpenAI, non a caso, ha dichiarato che inizierà a riportare la chain of thought controllability nelle system card dei futuri frontier model, a partire da GPT-5.4 Thinking. È un segnale importante: il tema non viene trattato come una curiosità di laboratorio, ma come un indicatore di sicurezza da tracciare nel tempo.
La vera lezione: passare dal “modello bravo” al sistema controllabile
Per le aziende, la conseguenza pratica è chiara. L’adozione di agenti AI non può essere governata solo con policy astratte o con test ex ante sul modello. Serve una progettazione del controllo dentro l’architettura operativa.
Nei processi ad alto impatto questo significa almeno quattro cose:
- conservare le tracce di reasoning quando il contesto normativo e di privacy lo consente;
- separare chi esegue il compito da chi monitora il processo;
- prevedere escalation e approvazioni umane sulle azioni irreversibili;
- combinare il monitoraggio della chain of thought con sandbox, guardrail applicativi, osservabilità dei tool e logging degli output.
È questo il passaggio verso l’impresa cognitiva di cui si parla tanto e che spesso resta troppo astratto. Un’impresa AI-powered non è quella che mette un agente ovunque. È quella che sa dove lasciare autonomia, dove imporre attrito e dove costruire visibilità. In altre parole, la maturità non si misura solo dalla capacità di automatizzare, ma dalla capacità di rendere governabile l’automazione quando cresce di scala e tocca processi critici.
C’è anche una lezione culturale. Per anni il dibattito sull’AI enterprise si è concentrato soprattutto su use case, ROI e produttività. Tutto corretto, ma non più sufficiente. Nel momento in cui gli agenti iniziano a orchestrare strumenti, prendere decisioni intermedie e agire in sequenza, il vero vantaggio competitivo non sarà avere il modello apparentemente più intelligente. Sarà avere il sistema più controllabile, auditabile e antifragile.
Per questo la bassa controllabilità della chain of thought va letta nel modo giusto. Non come un lasciapassare, ma come un canarino utile. Finché i modelli faticano a nascondere davvero il proprio ragionamento, le imprese hanno l’opportunità di costruire processi di oversight realistici. La finestra, però, potrebbe non restare aperta per sempre. E chi oggi progetta stack agentici senza pensare alla monitorabilità rischia di scoprire troppo tardi che la vera complessità non era far agire l’AI, ma riuscire a governarla.
In sintesi
• La scarsa capacità dei modelli di manipolare la chain of thought rende oggi più credibile il monitoraggio degli agenti AI.
• Monitorare solo output e azioni non basta: la traccia di ragionamento aggiunge segnali operativi di rischio.
• Più reasoning effort può significare più costo, ma anche maggiore monitorabilità e quindi maggiore governabilità.
• La sicurezza non coincide con il modello: serve un sistema con monitor, guardrail, logging, escalation e approvazioni umane.
• Questa è una finestra temporale utile: l’oversight va progettato ora, prima che i modelli imparino davvero a nascondersi.



Partecipa alla community