
Il colosso dei dati finanziari Bloomberg ha presentato BloombergGPT, un modello linguistico addestrato su una “vasta gamma” di dati finanziari per supportare una serie “diversificata” di attività NLP nel settore, come ha affermato la società.
Bloomberg ha preferito creare un proprio modello perché, ha affermato, “la complessità e la terminologia unica del dominio finanziario giustificano un modello specifico del dominio”.
BloombergGPT sarà utilizzato per attività di NLP finanziario come l’analisi del sentiment, il riconoscimento delle entità nominate, la classificazione delle notizie e la risposta alle domande.
Il modello sarà utilizzato anche per introdurre nuovi modi di estrarre informazioni dai molti dati sul terminale Bloomberg, che per anni ha utilizzato un’interfaccia utente complessa.
Il CTO di Bloomberg, Shawn Edwards ha dichiarato in un blog che BloombergGPT consentirà all’azienda di affrontare nuovi tipi di applicazioni più velocemente, con “prestazioni più elevate” all’inizio rispetto alla creazione di modelli personalizzati per ogni applicazione.
Un documento che delinea il modello può essere trovato su arXiv.
Indice degli argomenti:
Come si confronta BloombergGPT?
In termini di dimensioni, BloombergGPT è composto da 50 miliardi di parametri. Per metterlo in prospettiva, GPT-3 di OpenAI, che recentemente è stato superato da GPT-4, è di 175 miliardi di parametri.
BloombergGPT è relativamente piccolo per un LLM e il confronto delle dimensioni più vicino sarebbe il modello LLaMA da 65 miliardi di Meta. Tuttavia, il modello è addestrato specificamente per attività NLP finanziarie altamente specifiche, il che significa che non avrebbe bisogno di dati più generali come un modello OpenAI.
Il modello è stato creato utilizzando l’ampio archivio di dati finanziari di Bloomberg, con un set di dati di 363 miliardi di token costituito da documenti finanziari inglesi, aumentati con un set di dati pubblico di 345 miliardi di token, per creare un ampio corpus di addestramento con oltre 700 miliardi di token.
Gli ingegneri di Bloomberg ML hanno quindi addestrato un modello di linguaggio causale da 50 miliardi di decodificatori di parametri, con il modello risultante convalidato su benchmark NLP specifici per la finanza, nonché una suite di standard interni.
In termini di benchmark NLP popolari come BIG-bench Hard e MMLU, Bloomberg ha affermato che il suo modello “supera i modelli aperti esistenti di dimensioni simili su attività finanziarie con ampi margini, pur continuando a performare alla pari o meglio sui benchmark NLP generali”.
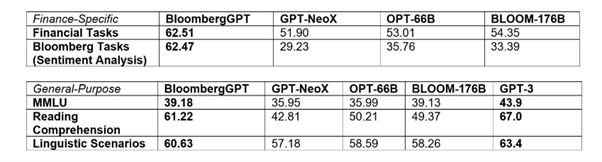
Per i benchmark specifici della finanza, BloombergGPT può competere con modelli open source più grandi, come Bloom e OPT-66B. Bloomberg ha anche ottenuto un punteggio migliore rispetto ai modelli open source più piccoli come GPT-NeoX di Hugging Face.
Nei test di benchmark più generali, BloombergGPT non è riuscito tuttavia a battere GPT-3 di OpenAI, ma ha ottenuto risultati non troppo lontani.
“La qualità dei modelli di machine learning e NLP dipende dai dati che si inseriscono”, ha spiegato Gideon Mann, responsabile del team ML Product and Research di Bloomberg. “Grazie alla raccolta di documenti finanziari che Bloomberg ha curato per oltre quattro decenni, siamo stati in grado di creare con cura un set di dati ampio e pulito, specifico del dominio, per addestrare un LLM più adatto per i casi d’uso finanziari. Siamo entusiasti di utilizzare BloombergGPT per migliorare i flussi di lavoro NLP esistenti, immaginando allo stesso tempo nuovi modi per mettere in pratica questo modello per soddisfare i nostri clienti”.
Gli LLM crescono
OpenAI e Google stanno utilizzando i loro modelli linguistici di grandi dimensioni per alimentare nuove offerte per attività come la generazione di codice e miglioramenti del flusso di lavoro di produzione.
Ma con l’aumentare dell’interesse per le LLM, aumenta anche il numero di attori che sviluppano le proprie iterazioni. A fine marzo 2023, Cerebras, la startup produttrice di chip, ha presentato i propri modelli linguistici di grandi dimensioni addestrati sul suo supercomputer AI, Andromeda. E Salesforce ha creato EinsteinGPT per la gestione delle relazioni con i clienti.
I ricercatori di intelligenza artificiale di Stanford hanno presentato Alpaca, un modello linguistico addestrato con soli 600 dollari, anche se una demo problematica è stata rimossa a causa delle allucinazioni del modello. Riducendo ulteriormente i costi, Databricks ha presentato il clone di ChatGPT Dolly che è stato realizzato con appena 30 dollari…



