
L’arrivo di Gemini 3 segna un passaggio importante nella corsa ai modelli generativi di nuova generazione. Dopo le iterazioni 2.0 e 2.5, Google propone un modello che non si limita a incrementare parametri e potenza computazionale, ma punta esplicitamente su tre assi: ragionamento più profondo, agenti più efficaci e maggiore robustezza sul piano della sicurezza.
Parlare di “test di Gemini 3” significa quindi andare oltre la classica lista di benchmark, per capire come Google sta ridefinendo il modo in cui si misura l’intelligenza di un modello multimodale.
In questo articolo intreccio i risultati ufficiali con una serie di prove pratiche condotte personalmente sul modello, in scenari reali di lavoro e prototipazione. I
In particolare sono stati testati Gemini 3 Pro e Gemini 3 Deep Think in contesti di sviluppo software, analisi documentale e creazione di contenuti, raccogliendo osservazioni sistematiche su punti di forza e limiti.

Indice degli argomenti:
Gemini 3, le varianti Pro e Deep Think
Gemini 3 viene presentato in due varianti principali, Pro e Deep Think, con l’obiettivo di coprire sia gli scenari interattivi a bassa latenza sia i compiti più complessi che richiedono catene di ragionamento articolate e pianificazione di lungo periodo. Secondo i dati ufficiali, 3.0 Pro supera i principali modelli concorrenti in 19 benchmark su 20, e in test come Humanity’s Last Exam supera la versione Pro di GPT‑5 con un margine significativo, segnalando un progresso non solo incrementale ma sostanziale nella comprensione di compiti eterogenei e ad alta complessità.
Gli strumenti di valutazione
Per interpretare correttamente questi risultati occorre però entrare nel merito degli strumenti di valutazione. Da anni la comunità utilizza batterie di benchmark come MMLU per le conoscenze multitask, GSM8K per la matematica di livello scolastico, HumanEval per la generazione di codice, oltre ai nuovi test multimodali che intrecciano testo, immagini, audio e video.
Nel caso di Gemini 3, Google enfatizza in particolare le prove di ragionamento composizionale e tool use, cioè quei compiti in cui il modello deve scomporre un problema in passi, richiamare strumenti esterni e orchestrare interazioni con API, database o sistemi di esecuzione del codice.
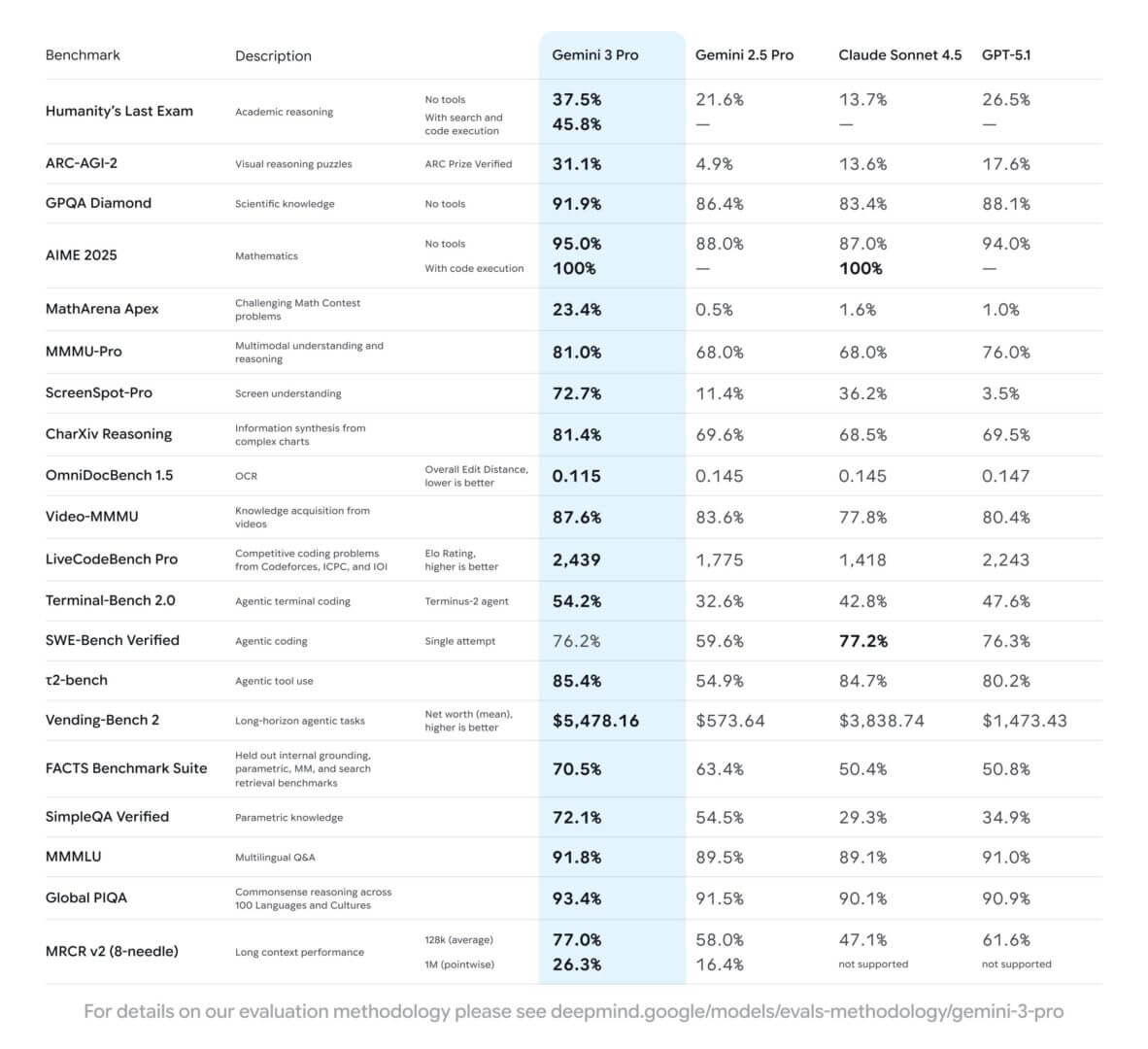
Vending Bench
Un test emblematico in questo senso è il cosiddetto Vending Bench, una simulazione in cui il modello deve pianificare azioni e usare strumenti per risolvere scenari progressivamente più complessi, arrivando a ragionare su stati del mondo che evolvono nel tempo. Qui Gemini 3 mostra un salto di qualità rispetto alle generazioni precedenti, avvicinandosi a ciò che ci si aspetta da un “agente” più che da un semplice chatbot. Non si tratta più soltanto di rispondere correttamente a una domanda, ma di mantenere un obiettivo, aggiornare il proprio piano e usare risorse esterne in modo coerente.

Gemini 3, modello multimodale
Accanto ai benchmark testuali tradizionali, Gemini 3 viene valutato in profondità come modello multimodale. Dal punto di vista pratico, questo significa verificare la capacità di combinare testo, immagini, audio e video in modo fluido, non solo come canali di input separati ma come elementi intrecciati nella stessa sessione.
Le prove includono compiti di comprensione di diagrammi, analisi di video con eventi distribuiti nel tempo, descrizione di scene complesse a partire da sequenze di frame e trasformazione di contenuti visivi in codice o specifiche strutturate.

Una parte interessante dell’ecosistema di test ruota attorno a Gemini 3 Pro Image, la base del modello di generazione e editing Nano Banana Pro, pensato per la creazione di immagini ad alta fedeltà, infografiche e diagrammi con testo multilingue accurato. Qui l’attenzione non è solo estetica. Vengono misurati la coerenza semantica tra prompt e immagine, la correttezza del testo incorporato nelle figure, la capacità di mantenere la consistenza di personaggi e oggetti su più generazioni e la precisione nell’editing locale, come modifiche di illuminazione, inquadratura o elementi specifici all’interno della scena.
In questo caso i benchmark si intrecciano con test di usabilità, perché il modello è pensato per applicazioni reali in ambito comunicazione, design e contenuti marketing.
Gemini 3 a confronto con le versioni precedenti
Il confronto con le versioni precedenti di Gemini aiuta a capire dove avviene il salto. Già con la serie 2.0 e 2.5 Google aveva introdotto contesti fino a un milione di token, nativa comprensione di audio e video e un focus marcato sul ragionamento per step.

In molti benchmark testuali e di coding queste versioni erano già competitive con i modelli più avanzati della concorrenza, in alcuni casi superandoli, soprattutto nei compiti che richiedevano l’analisi di grandi basi di codice o documentazione.
Gemini 3 capitalizza su questa base estendendo il ragionamento multimodale e spostando il baricentro dai compiti “one shot” verso scenari di agenti che interagiscono con ambienti complessi.
Gemini 3, la sicurezza
Un’altra dimensione cruciale dei test su Gemini 3 riguarda la sicurezza. Questo aspetto non emerge solo dalla documentazione ufficiale ma anche dai test diretti che ho svolto, nei quali il modello tende a mettere in discussione istruzioni ambigue o rischiose invece di seguirle in modo acritico.
Google descrive il modello come il più sottoposto a valutazioni di sicurezza nella storia interna dell’azienda, con particolare attenzione alla riduzione della sycophancy, cioè la tendenza del modello a compiacere l’utente anche quando questo propone affermazioni scorrette o pericolose, e alla resistenza agli attacchi di prompt injection e jailbreak.
Le prove includono tanto suite automatizzate, in cui migliaia di prompt avversari vengono generati e variati sistematicamente, quanto valutazioni condotte da red team umani specializzati nel far emergere vulnerabilità legate a disinformazione, abuso di strumenti o supporto a cyberattacchi.
Agenti AI: la metrica di successo
Queste valutazioni di sicurezza hanno una ricaduta diretta sulle applicazioni agentiche che Google sta promuovendo attorno a Gemini 3. Nei tool per sviluppatori, dalla AI Studio al supporto nei framework open source per orchestrare agenti, i test si concentrano non solo su precisione e latenza ma anche sulla capacità dei modelli di rispettare vincoli di policy, per esempio limitando l’accesso a determinate API in base al contesto o riconoscendo richieste che tentano di aggirare controlli esistenti.
In pratica ciò significa che la metrica di successo di un agente non è più soltanto “risolve il task”, ma “lo risolve in modo sicuro e conforme alle regole definite”.
Gemini 3 sul piano industriale
Sul piano industriale, i test di Gemini 3 includono scenari d’uso end‑to‑end che si avvicinano a casi reali:
- assistenti per sviluppatori in grado di operare su repository di grandi dimensioni,
- sistemi di supporto decisionale che combinano dati testuali,
- tabelle e visualizzazioni, strumenti per la creazione di contenuti che partono da appunti disordinati e li trasformano in documenti strutturati o storyboard multimediali.
Nei test ho usato Gemini 3 Pro per refactoring di codice, analisi di repository e sintesi di documentazione tecnica aziendale e ho osservato una riduzione tangibile delle correzioni manuali rispetto a Gemini 2.5 Pro, soprattutto nei flussi che richiedono di mantenere coerenza tra più file e più fonti informative. Qui la valutazione si allarga a metriche come il tasso di correzioni richieste dall’utente, la quantità di interventi manuali necessari per portare un output in produzione e il risparmio di tempo rispetto a workflow tradizionali.
È inevitabile che i risultati ufficiali di Google vengano messi in prospettiva rispetto ai benchmark indipendenti. Report e analisi condotti da terze parti negli ultimi anni mostrano come i grandi modelli tendano a occupare nicchie di eccellenza diverse, con alcuni più forti sul coding complesso, altri sulla scrittura creativa, altri ancora sulla velocità e i costi di esecuzione.
I primi test comparativi che includono Gemini 3 suggeriscono che il modello di Google si posiziona ai vertici soprattutto nei compiti di ragionamento strutturato, pianificazione e agenticità, mentre la partita sulla qualità fine della generazione testuale resta più sfumata e spesso dipende dal dominio e dalla lingua di riferimento.
La governance di Gemini 3
Un elemento spesso sottovalutato nei test, ma centrale per l’adozione in azienda, è la governance del modello. Con Gemini 3, Google integra più strettamente i log di interazione, i controlli di audit e gli strumenti per definire policy personalizzate su dati e strumenti accessibili al modello. Questo si riflette nella progettazione dei test per i clienti enterprise, che non si limitano a verificare la qualità di singole risposte ma misurano come il sistema si comporta nel tempo rispetto a vincoli normativi, requisiti di privacy e integrazione con i processi già esistenti.
L’evoluzione dei test di Gemini 3
In prospettiva, i test che oggi fotografano lo stato di Gemini 3 sono destinati a evolversi rapidamente. La crescente attenzione verso agenti autonomi, robotica basata su modelli linguistico‑visivi e sistemi di supporto decisionale in contesti critici richiederà benchmark più vicini al mondo reale, capaci di catturare non solo l’accuratezza media ma anche i casi limite, i fallimenti rari e le dinamiche emergenti quando più agenti interagiscono tra loro.
Gemini 3, con il suo focus su ragionamento, multimodalità e sicurezza, sembra progettato proprio per questa nuova fase, ma sarà il tempo, e non solo i grafici dei benchmark, a confermare quanto sia solida la promessa.
Conclusioni
Per chi lavora nel mondo tecnologico, il messaggio è duplice. Da un lato, i risultati dei test su Gemini 3 indicano che il livello di capacità dei modelli generalisti ha superato una nuova soglia, rendendo credibili applicazioni che fino a poco tempo fa erano considerate di frontiera, dai copiloti per sviluppatori ai sistemi di knowledge management realmente conversazionali.
Dall’altro, emerge con forza che la valutazione non può più limitarsi a punteggi sintetici su benchmark statici: diventa necessario disegnare suite di test specifiche per il proprio dominio, che misurino affidabilità, sicurezza e costi lungo l’intero ciclo di vita delle applicazioni.
In questo contesto, e alla luce dei test diretti che svolti su Gemini 3 in ambienti e dataset reali, considerare il modello semplicemente “promosso” o “bocciato” è una semplificazione eccessiva.
Il modello si colloca nettamente tra i più avanzati oggi disponibili e spinge verso nuovi standard di ragionamento multimodale e sicurezza, ma la sua reale efficacia dipenderà dalla capacità di integrarlo in ecosistemi di strumenti, dati e processi progettati con cura. I test, più che un giudizio definitivo, diventano un dialogo continuo tra chi sviluppa il modello e chi lo applica sul campo, con il duplice obiettivo di sfruttarne al meglio le potenzialità e contenerne i rischi.
Bibliografia
Analisi comparative di modelli come GPT‑4.1, Gemini 2.5 Pro e successori su siti e blog tecnici aggiornati al 2025 [articoli di confronto e benchmark].
Google, “A new era of intelligence with Gemini 3” blog post ufficiale
Google, “Introducing Nano Banana Pro (Gemini 3 Pro Image)” blog post ufficiale
Google Developers Blog, “Build with Nano Banana Pro, our Gemini 3 Pro Image model” articolo per sviluppatori
Google Developers Blog, “Building AI Agents with Google Gemini 3 and Open Source Frameworks” articolo per sviluppatori
Voce “Gemini (language model)” su Wikipedia, sezione aggiornata su Gemini 3 voce enciclopedica
The Wall Street Journal, “How Google Finally Leapfrogged Rivals With New Gemini Rollout” articolo di approfondimento





Partecipa alla community