
Meta ha annunciato ufficialmente il lancio dei primi modelli della serie Llama 4, segnando l’inizio di una nuova era per l’intelligenza artificiale nativamente multimodale. I modelli Llama 4 Scout e Llama 4 Maverick promettono esperienze più personalizzate e prestazioni superiori, aprendo la strada a nuove opportunità per sviluppatori, aziende e utenti finali.
Indice degli argomenti:
Llama 4 Scout: efficienza estrema in un’unica GPU
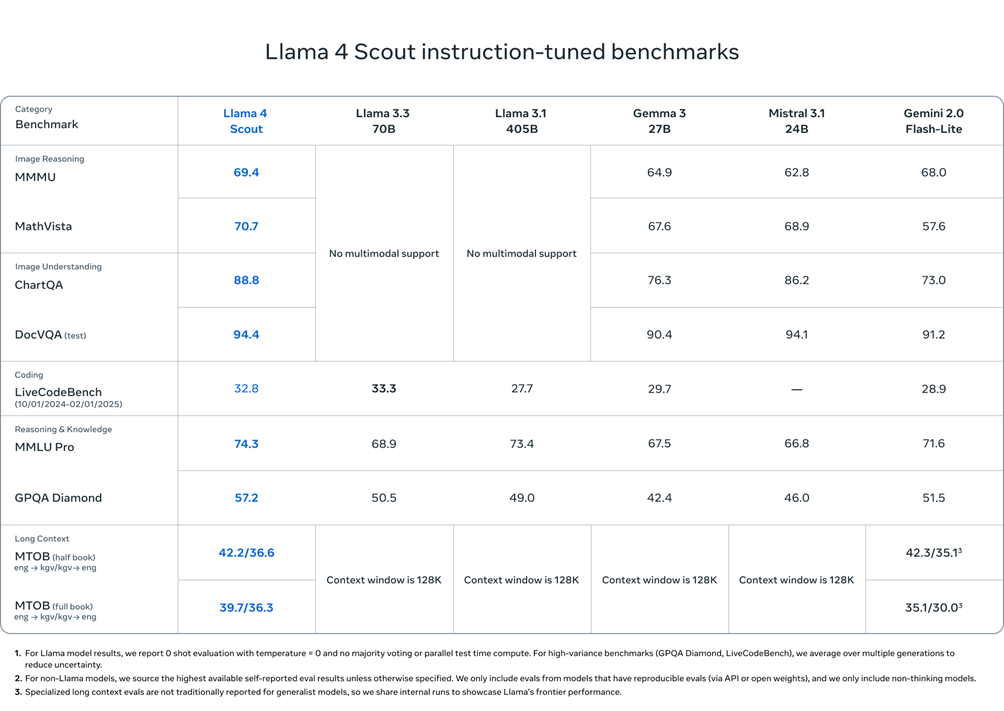
Llama 4 Scout è un modello da 17 miliardi di parametri attivi con 16 esperti, progettato per essere il miglior modello multimodale della sua categoria. Può essere eseguito su una singola GPU NVIDIA H100 grazie a un’architettura compatta ed efficiente. Con una finestra di contesto leader del settore da 10 milioni di token, Scout supera modelli come Gemma 3, Gemini 2.0 Flash-Lite e Mistral 3.1 in benchmark ampiamente riconosciuti.
Llama 4 Maverick: ottimo rapporto prestazioni-costo
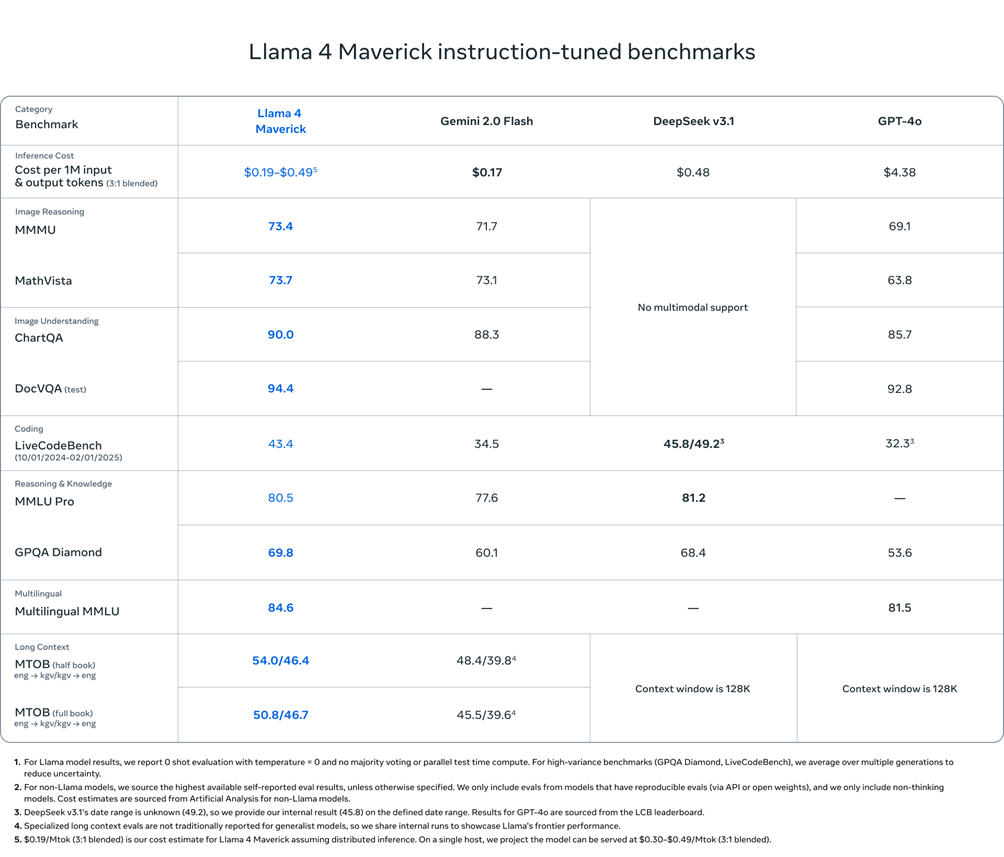
Accanto a Scout, Meta presenta Llama 4 Maverick, anch’esso con 17 miliardi di parametri attivi ma con ben 128 esperti. Maverick batte GPT-4o e Gemini 2.0 Flash, offrendo un ottimo rapporto prestazioni-costo. Con una valutazione ELO di 1417 su LMArena, Maverick si afferma come il modello ideale per casi d’uso di chat, assistenza virtuale e comprensione multimodale.
Behemoth: il colosso da 2 trilioni di parametri
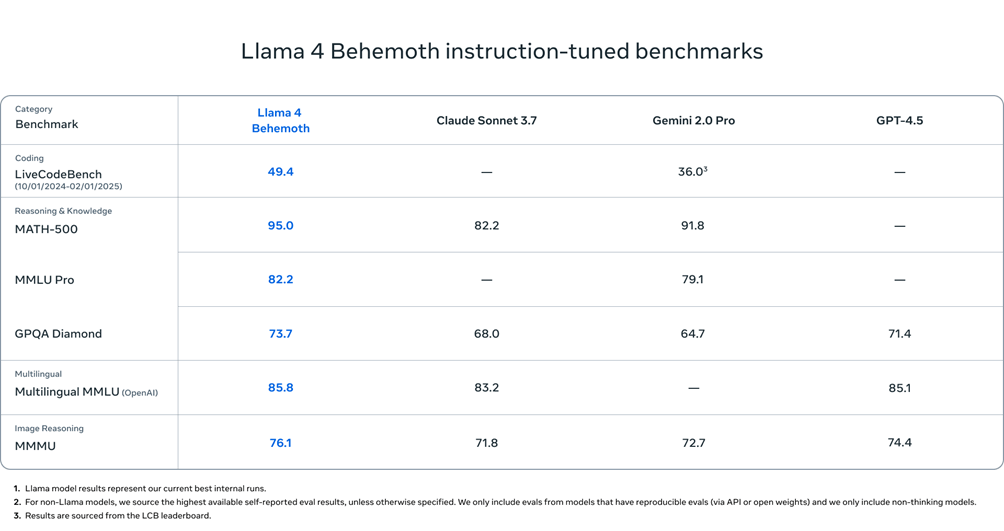
A supporto di questa nuova generazione, Meta sta sviluppando Llama 4 Behemoth: un modello con 288 miliardi di parametri attivi e quasi duemila miliardi di parametri totali. Non ancora completato, Behemoth promette prestazioni superiori rispetto a GPT-4.5, Claude Sonnet 3.7 e Gemini 2.0 Pro nei benchmark STEM e sarà il “professore” che formerà i futuri modelli Llama.
Llama 4, una nuova architettura per un’AI migliore
Llama 4 introduce un’architettura a “Mixture of Experts” (MoE), in cui solo una parte dei parametri viene attivata per ogni token, migliorando l’efficienza sia nell’addestramento che nell’inferenza. L’integrazione nativa di modalità testuali e visive permette a Scout e Maverick di gestire testo, immagini e video in un unico flusso.
La nuova tecnica di training, denominata MetaP, consente di settare automaticamente parametri chiave come il learning rate per layer, rendendo Llama 4 estremamente adattabile e più performante su più di 200 lingue.
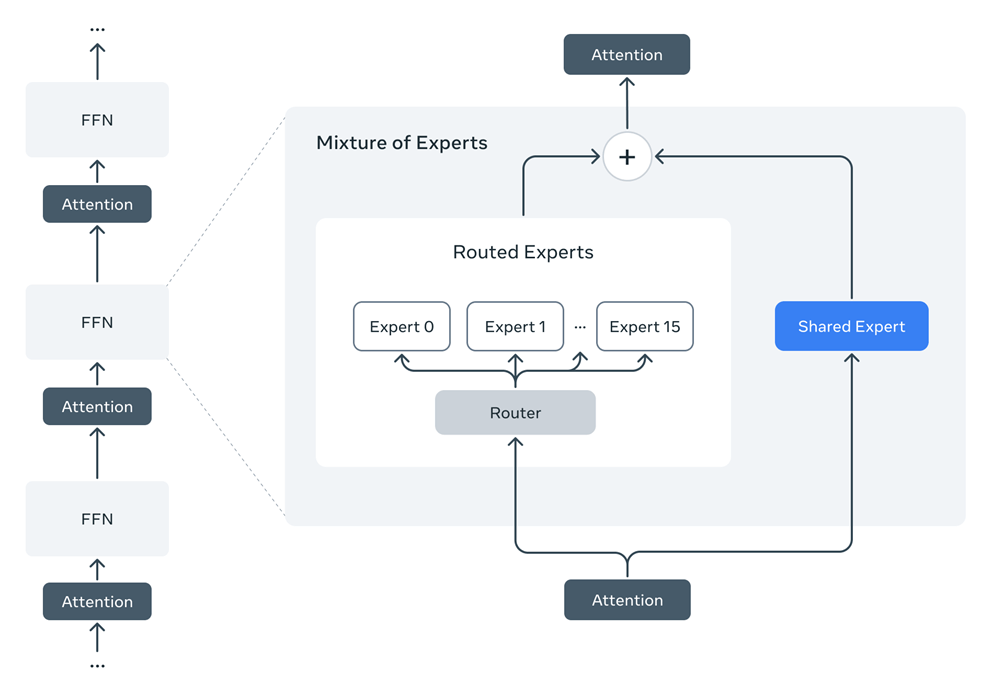
Ad esempio, i modelli Llama 4 Maverick hanno 17B parametri attivi e 400B parametri totali. Per garantire l’efficienza dell’inferenza, Meta utilizza alternativamente strati densi e misti di esperti (MoE). Gli strati MoE utilizzano 128 esperti instradati e un esperto condiviso. Ogni token viene inviato all’esperto condiviso e anche a uno dei 128 esperti instradati. Di conseguenza, mentre tutti i parametri sono memorizzati, solo un sottoinsieme dei parametri totali viene attivato durante il funzionamento di questi modelli. Questo migliora l’efficienza dell’inferenza riducendo i costi e la latenza del servizio dei modelli. Lama 4 Maverick può essere eseguito su un singolo host NVIDIA H100 DGX per una facile implementazione, o con inferenza distribuita per la massima efficienza.
Post-training: la chiave del successo
Il post-training dei modelli Llama 4 è stato rivoluzionato con una pipeline leggera basata su fine-tuning supervisionato, reinforcement learning online e ottimizzazione delle preferenze. Attraverso un sistema di filtraggio dinamico dei prompt e un continuo adattamento, i modelli hanno migliorato significativamente le capacità di ragionamento, codifica e comprensione multimodale.
Sicurezza e bias sotto controllo
Meta ha integrato strategie avanzate di mitigazione dei rischi in ogni fase dello sviluppo di Llama 4. Strumenti come Llama Guard e Prompt Guard aiutano a proteggere input e output, mentre la piattaforma CyberSecEval supporta la valutazione dei rischi di sicurezza. Inoltre, Llama 4 mostra miglioramenti significativi nella gestione dei bias politici e sociali, rispondendo in modo più equilibrato rispetto alla generazione precedente.
Behemoth: la sfida dell’addestramento su larga scala
Il training del modello Behemoth ha richiesto una revisione completa delle infrastrutture di reinforcement learning, permettendo una scalabilità senza precedenti. Grazie a una nuova infrastruttura di RL asincrona, Meta è riuscita a ottenere un miglioramento dell’efficienza di dieci volte rispetto alle generazioni precedenti.
Conclusioni
Con la disponibilità immediata di Llama 4 Scout e Maverick su llama.com e su Hugging Face, Meta riafferma il suo impegno verso l’open source. Gli sviluppatori possono integrare i modelli nelle proprie applicazioni o provare Meta AI su WhatsApp, Messenger, Instagram Direct e Meta.AI.
Il viaggio di Llama 4 è solo all’inizio: il 29 aprile, durante LlamaCon, verranno svelate nuove visioni e opportunità per una AI sempre più intelligente, accessibile e personale.




