
L’intelligenza artificiale generativa sta dimostrando una sorprendente capacità di creare contenuti testuali, immagini, audio e video che spesso appaiono indistinguibili da quelli prodotti dall’uomo. Modelli linguistici di grandi dimensioni (LLM) come GPT-4, Claude, modelli di diffusione per la generazione di immagini come DALL-E 2 e Stable Diffusion, e strumenti per la creazione di musica e video stanno rivoluzionando settori creativi e industriali.
La tecnologia RAG (Retrieval Augmented Generation) permette una efficiente realizzazione di applicazioni in domini specifici. Tuttavia, nonostante la loro potenza, questi modelli generativi non sono esenti da limitazioni. Una delle sfide principali è la loro dipendenza dai dati di training, che possono essere incompleti, distorti o non contenere informazioni specifiche necessarie per generare output accurati e contestualmente rilevanti. Questo può portare a generazioni imprecise, non aggiornate o addirittura alle allucinazioni (creazione di informazioni).
Una seconda sfida è il perfezionamento dell’elaborazione simultanea di dati testuali, dati visuali (immagini, video) e altro, nota come “Multimodal Retrieval”.
Ma esiste un approccio che supera le limitazioni dei modelli tradizionali: si chiama Knowledge Augmented Generation (KAG).
Indice degli argomenti:
Cos’è la Knowledge Augmented Generation (KAG)
La Knowledge Augmented Generation (KAG) rappresenta un approccio innovativo che mira a superare le limitazioni dei modelli generativi tradizionali integrando esplicitamente fonti di conoscenza esterne nel processo di generazione. Invece di affidarsi esclusivamente alle informazioni apprese durante il training, i sistemi KAG attingono a basi di conoscenza strutturate, in particolare Knowledge Graph, ma anche non strutturate come documenti di testo, articoli scientifici, pagine web, per arricchire il contesto e migliorare la qualità, l’accuratezza e la coerenza degli output generati.
Cos’è un Knowledge Graph
Knowledge Graph (KG) è un database di conoscenza basato su un modello a grafo in cui le entità sono rappresentate come nodi, le relazioni fra le entità come archi; sia gli archi sia i nodi possono avere etichette che ne descrivono tipologia e natura; la tipologia di dato può essere testuale o multimediale. I nodi rappresentano oggetti, concetti, persone, luoghi, eventi o qualsiasi altra cosa di interesse nel dominio di conoscenza. Gli archi rappresentano le connessioni o i legami semantici tra le entità; possono essere bidirezionali o avere una sola direzione.
La caratteristica di un KG è di fornire una rappresentazione ricca e contestuale della conoscenza, catturando le interconnessioni e il significato delle informazioni. I KG facilitano inferenza e ragionamento, permettono la deduzione di nuove informazioni, migliorano le ricerche con query semantiche, integrano dati eterogenei da diverse fonti e con diversi formati. Ma soprattutto i KG forniscono una base di conoscenza strutturata per applicazioni di Natural Language Processing (NLP), machine learning, sistemi di raccomandazione, chatbot e altro, aprendo nuove possibilità per le applicazioni basate sull’intelligenza artificiale. Esempi di KG disponibili sono
- Google Knowledge Graph: utilizzato per migliorare i risultati di ricerca fornendo informazioni dirette e contestuali su persone, luoghi, cose e concetti.
- DBpedia: un knowledge graph creato estraendo informazioni strutturate da Wikipedia.
- Wikidata: un database di conoscenza collaborativo e multilingue.
- WordNet: un database lessicale che raggruppa le parole in base alle loro relazioni semantiche (sinonimi, antonimi, iperonimi, ecc.).
L’utilizzo dei KG in applicazioni di Natural Language Processing è una pratica ormai consolidata, si veda per esempio l’esplorazione semantica di un catalogo di libri che può essere considerato un precursore dell’attuale tecnologia KAG.
Le basi della KAG – Knowledge Augmented Generation
I principi fondamentali della KAG includono:
- Recupero della conoscenza: identificazione e recupero di informazioni rilevanti da fonti esterne in base alla richiesta dell’utente o al contesto della generazione.
- Integrazione della conoscenza: incorporamento della conoscenza recuperata nel processo di generazione, guidando il modello a produrre output informati e contestualmente accurati.
- Ragionamento sulla conoscenza: in alcuni approcci più avanzati, il sistema può anche effettuare ragionamenti logici e derivare nuove informazioni o selezionare le informazioni più pertinenti.
Per un approfondimento tecnico e un esempio di creazione di un modello KAG che sfrutta pienamente i vantaggi di un Knowledge Graph per migliorare la produzione di un LLM, si può consultare KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation.

Perché è necessaria la KAG – Knowledge Augmented Generation
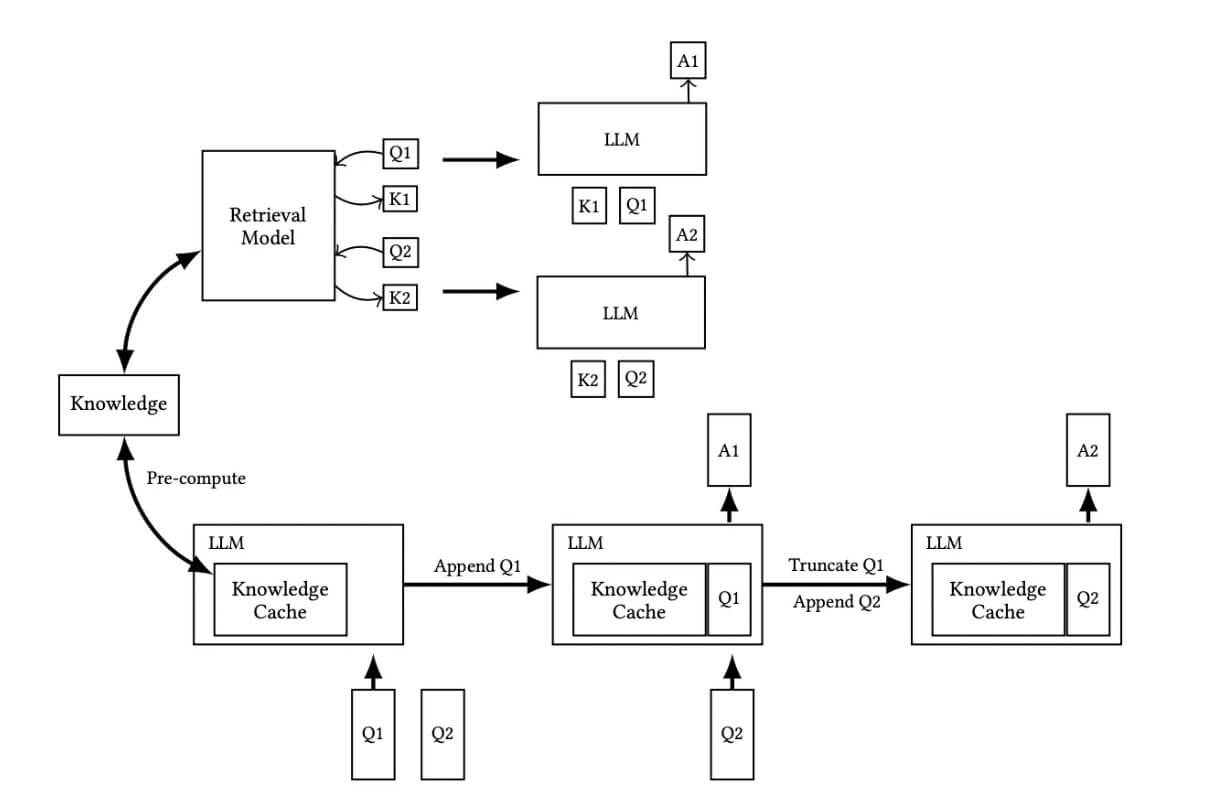
I metodi tradizionali del Retrieval-Augmented Generation sebbene per i modelli LLM abbiano sviluppato e migliorato il recupero di informazioni peculiari in domini specifici e abbiano risolto molti problemi di allucinazione, mancano di capacità logica, sono deboli nel calcolo e nelle relazioni temporali, forniscono una conoscenza frammentaria e incompleta. L’architettura tipica di una RAG (Retrieval-Augmented Generation) è composta di due fasi
- Retrieval (recupero): data una query o un prompt, un modello di retrieval cerca e recupera documenti o frammenti di conoscenza rilevanti da un corpus di dati esterni.
- Generazione: il prompt originale viene concatenato con le informazioni recuperate e fornito a un modello generativo (solitamente un LLM), che utilizza queste informazioni aggiuntive per produrre l’output finale.
I testi generati mancano ancora di coerenza e logica soprattutto in domini molto specifici come il contesto legale, il medicale, le scienze dove il ragionamento analitico è fondamentale. I processi reali hanno bisogno sia di ragionamenti inferenziali basati su specifiche relazioni in una selezione di informazioni sia di ragionamenti logici, per produrre risposte pertinenti a quanto viene chiesto.
Lo sviluppo delle KAG si inserisce in questo contesto per unire le capacità linguistiche dei Large Language Model con la conoscenza insita in un Knowledge Graph che permette l’integrazione di ragionamento simbolico e l’apprendimento congiunto del retrieval e della generazione.
Vantaggi e benefici della Knowledge Augmented Generation
L’utilizzo dei Knowledge Graph con tutto il loro contenuto informativo e le capacità logiche e semantiche nei modelli di KAG porta evidenti vantaggi:
- Maggiore accuratezza e migliore contestualizzazione: l’integrazione di conoscenza esterna fornisce un contesto più ricco, consentendo al modello di ridurre il rischio di generare informazioni errate o inventate e generare output più pertinenti e informati.
- Aggiornamento delle informazioni: attingendo a fonti di conoscenza dinamiche, i sistemi KAG possono generare output basati su informazioni aggiornate, superando i limiti temporali dei dati di training statici.
- Spiegabilità e tracciabilità: In alcuni casi, è possibile tracciare l’origine delle informazioni utilizzate per la generazione, migliorando la trasparenza e la spiegabilità dell’output. Ricordiamo che l’Explainable AI ha un’importanza cruciale in processi dove è necessario motivare e capire le origini di un output.
- Personalizzazione e adattabilità: la KAG può essere realizzata utilizzando un Knowledge Graph privato aziendale e fortemente adattato al contesto specifico.
- Riduzione della dipendenza da dati di training massivi: l’integrazione di conoscenza esterna può potenzialmente ridurre la necessità di addestrare modelli generativi su quantità enormi di dati per ottenere risultati di alta qualità in specifici domini.

Applicazioni pratiche della KAG
La Knowledge Augmented Generation è una tecnologia emergente già in fase di ricerca e approfondimento da molti mesi e ha il potenziale di rivoluzionare diversi settori, superando le limitazioni dei modelli generativi tradizionali; le applicazioni pratiche ricalcano quelle dei RAG con un miglioramento notevole grazie all’integrazione con i Knowledge Graph.
- Chatbot e assistenti virtuali: i chatbot potenziati dalla KAG possono fornire risposte significativamente più accurate, contestualmente rilevanti e dettagliate. Invece di basarsi unicamente sulla conoscenza appresa durante l’addestramento, possono interrogare in tempo reale basi di conoscenza aziendali, FAQ, manuali tecnici o persino il web per rispondere a domande complesse.
- Generazione di contenuti di alta qualità: nel campo della creazione di contenuti, la KAG può essere utilizzata per generare articoli di notizie, report finanziari, descrizioni di prodotti e contenuti di marketing con maggiore precisione e profondità. Immagina un sistema che genera un articolo di cronaca attingendo a diverse fonti giornalistiche per fornire una copertura completa e verificata degli eventi. Nel settore dell’e-commerce, la KAG può creare descrizioni di prodotti dettagliate e accurate, integrando specifiche tecniche, recensioni degli utenti e informazioni di mercato.
- Ricerca e sviluppo: in ambito scientifico e di ricerca, la KAG può assistere i ricercatori nell’analisi di grandi volumi di letteratura scientifica, nell’identificazione di tendenze emergenti e nella formulazione di ipotesi. Un sistema KAG potrebbe essere in grado di estrarre informazioni chiave da migliaia di articoli, correlare risultati sperimentali e persino suggerire nuove direzioni di ricerca basate sulla conoscenza esistente.
- Medicina e diagnosi avanzata: la KAG ha il potenziale per trasformare la medicina fornendo ai medici informazioni più accurate e personalizzate. Integrando la storia clinica del paziente con le ultime ricerche mediche, le linee guida di trattamento e le informazioni sui farmaci, i sistemi KAG potrebbero assistere nella diagnosi, nella pianificazione del trattamento e nella previsione degli esiti. È fondamentale sottolineare che tali applicazioni richiedono estrema cautela e validazione clinica rigorosa che ancora è operata dall’essere umano specialista di settore.
- Finanza e analisi di mercato: la KAG può essere utilizzata per analizzare dati di mercato, report aziendali e notizie economiche per generare previsioni più accurate e fornire consulenza finanziaria basata su dati e conoscenze specifiche.
- Educazione e tutoring: la KAG può contribuire a creare esperienze di apprendimento più personalizzate e efficaci. Sistemi di tutoring intelligenti potrebbero attingere a un vasto corpus di conoscenze educative per rispondere alle domande degli studenti in modo dettagliato, fornire spiegazioni alternative e adattare il percorso di apprendimento alle esigenze individuali.
Le sfide della KAG
L’efficacia di un sistema KAG dipende fortemente dal Knowledge Graph di appoggio e dalla sua capacità di identificare le fonti di conoscenza più pertinenti e di incorporarle in modo coerente e utile nel processo di generazione. Un livello di sofisticazione avanzato nella KAG è rappresentato da “Ragionamento Multistep e Inferenza“; la capacità di eseguire inferenze logiche e di concatenare più passaggi di ragionamento sulla conoscenza recuperata aprirebbe nuove possibilità per la generazione di risposte complesse e la risoluzione di problemi.
Alcune delle principali sfide si possono sintetizzare nelle seguenti:
- Rilevanza della “conoscenza”: determinare quali informazioni esterne sono effettivamente rilevanti per una data query o contesto generativo può essere complesso. Un recupero troppo ampio può portare a un “rumore” informativo che distrae il modello generativo, mentre un recupero troppo restrittivo può escludere informazioni importanti.
- Qualità e affidabilità delle fonti: le fonti di conoscenza esterne possono variare significativamente in termini di qualità, accuratezza e affidabilità. È fondamentale disporre di Knowledge Graph garantiti e in generale di fonti credibili per evitare anche conflitti e contraddizioni. È necessario disporre sistemi di retrieval che vanno oltre la semplice similarità semantica e che sono in grado di comprendere le relazioni tra concetti e la rilevanza contestuale.
- Complessità del ragionamento: il ragionamento multistep richiede la capacità di scomporre un problema complesso in passaggi più semplici, di recuperare informazioni rilevanti per ciascun passaggio e di combinare i risultati intermedi per arrivare a una conclusione. Questo è intrinsecamente più difficile della semplice integrazione di fatti isolati. I knowledge graph, con le loro rappresentazioni esplicite di entità e relazioni, sono particolarmente adatti a supportare il ragionamento logico, ma richiedono tecniche complesse per la navigazione e l’inferenza. A questo si aggiunge l’integrazione di modelli ibridi simbolico neurali che combinino i punti di forza del ragionamento simbolico, preciso e interpretabile, con la flessibilità e la capacità di apprendimento dei modelli neurali.
- Gestione dell’incertezza e dell’ambiguità: il ragionamento sul mondo reale spesso comporta la gestione di informazioni incerte o ambigue. I sistemi KAG avanzati dovranno essere in grado di gestire l’incertezza attraverso i vari passi del ragionamento e fornire risposte che riflettano il livello di confidenza.
Conclusioni
Le direzioni future della ricerca nei modelli KAG si concentreranno sullo sviluppo di architetture più efficienti e flessibili, sull’esplorazione di nuove tecniche per il recupero e l’integrazione della conoscenza, sul miglioramento della capacità di ragionamento dei sistemi e sulla creazione di framework di valutazione più robusti. L’obiettivo è quello di realizzare sistemi di intelligenza artificiale generativa che non solo siano capaci di creare contenuti di alta qualità, ma che siano anche profondamente informati, affidabili e in grado di interagire con il mondo in modo più intelligente e consapevole.






