
In pochi giorni, il Tongyi Lab di Alibaba ha completato la famiglia Qwen 3.6 con tre rilasci che coprono molti scenari di adozione interessati.
Il primo è arrivato il 16 aprile con Qwen3.6-35B-A3B, un mixture-of-experts open-weight da 35 miliardi di parametri totali e 3 attivi per token.
Il 20 aprile è seguito Qwen3.6-Max-Preview, l’ammiraglia in versione di anteprima e, per la prima volta nella storia di Qwen, distribuita esclusivamente come servizio chiuso via API.
Il 22 aprile è stato il turno di Qwen3.6-27B, un modello denso multimodale rilasciato con licenza Apache 2.0.
La sequenza dice molto sulla strategia di Alibaba: l’idea è quella di sviluppare una linea di prodotto più flessibile rispetto alla concorrenza americana, con un flagship proprietario al vertice e due varianti open-source su cui far crescere la community di sviluppatori.

Indice degli argomenti:
Qwen3.6-Max-Preview: l’ammiraglia closed-weight
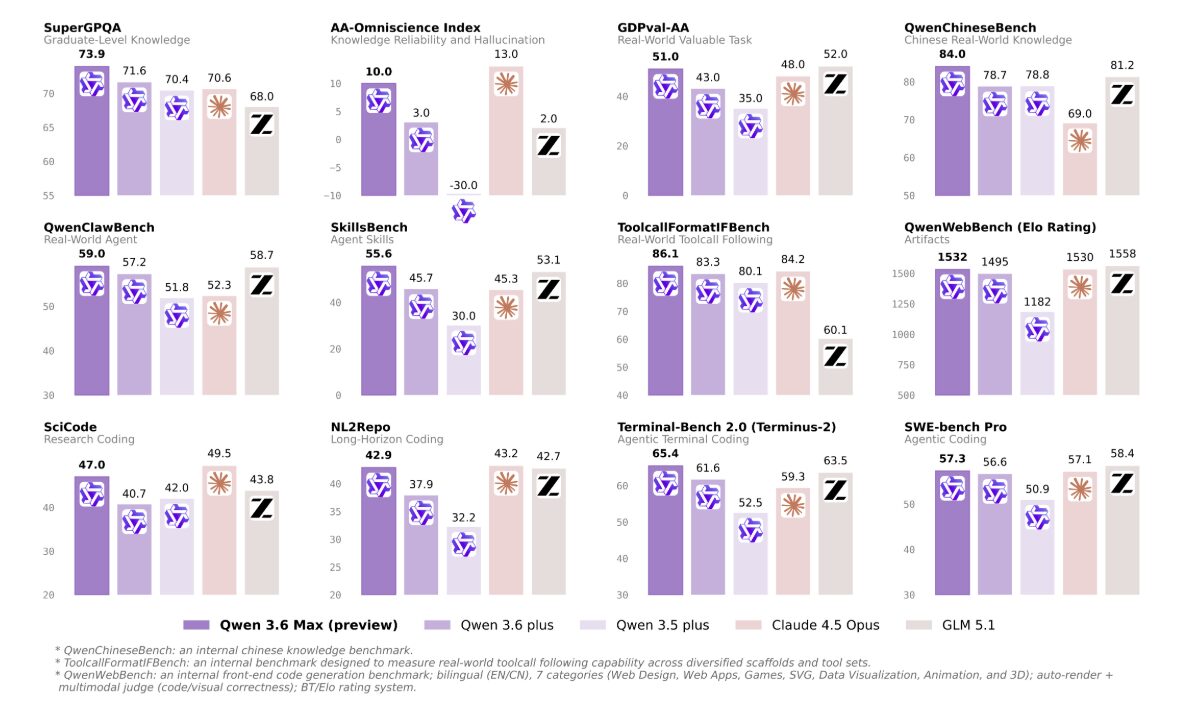
Alibaba descrive Qwen3.6-Max-Preview come un early access della prossima generazione di punta. Rispetto a Qwen3.6-Plus, lanciato a fine marzo, i miglioramenti misurabili sono concentrati su sei benchmark di programmazione, su quali Max-Preview rivendica il primo posto al momento del rilascio: SWE-bench Pro, Terminal-Bench 2.0, SkillsBench, QwenClawBench, QwenWebBench e SciCode.
I salti più significativi sono +10,8 punti su SciCode, +9,9 su SkillsBench, +5,0 su NL2Repo e +3,8 su Terminal-Bench 2.0. Il modello spicca anche per un Artificial Analysis Intelligence Index di 52, ben sopra la mediana di 33 nella stessa fascia di prezzo.
Prezzo molto competitivo
Tre dettagli fondamentali incidono sui modi in cui è possibili integrare Max-Preview in un flusso di automazione.
In primis, i pesi sono chiusi: niente rilasci su Hugging Face. Si tratta di una mossa che segue le strategie di OpenAI e Anthropic, orientata a un approccio API-first alla monetizzazione e alla protezione del vantaggio competitivo ottenuto in fase di addestramento. Il modello, inoltre, è solo testuale, senza supporto per input di immagini o video.
Infine, la rapidità di generazione risulta piuttosto ridotta: i test indipendenti indicano un consumo di circa 34 token al secondo e un TTFT (Time To First Token) di 3,3 secondi, valori sotto la mediana per modelli di reasoning della stessa fascia.
Il prezzo è molto competitivo e gli endpoint sono compatibili sia con il formato OpenAI sia con quello Anthropic; portare su Alibaba sistemi già sviluppati diventa così un’operazione rapidissima e quasi a costo zero.

Qwen3.6-27B: il dense open-source che insegue la frontiera
Qwen3.6-27B è il rilascio che sta facendo più rumore nella community open-source. È un modello denso da 27 miliardi di parametri, 64 layer, multimodale per testo, immagini e video, distribuito con licenza Apache 2.0 su Hugging Face e ModelScope. Il file pesa circa 56 GB. Il contesto nativo è di 262.144 token, estendibile tramite scalatura fino a oltre 1 milione.
L’architettura prosegue sulla strada dell’ibrido inaugurata da Qwen 3.6-Plus. I 64 layer sono organizzati in blocchi che alternano Gated DeltaNet (linear attention) e Gated Attention con Grouped Query Attention. La linear attention riduce la crescita del costo computazionale: per chi gestisce un budget GPU, lavorare su documenti lunghi diventa drasticamente meno costoso in termini di calcolo, energia e tempo di risposta.
I benchmark
I benchmark riportati da Alibaba meritano i titoli che gli sono stati dedicati.
Su SWE-bench Verified, Qwen3.6-27B segna 77,2 contro l’80,9 di Claude 4.5 Opus, restando entro un margine di 3,7 punti pur essendo dieci volte più piccolo come parametri totali.
Su Terminal-Bench 2.0 il modello raggiunge lo stesso punteggio di Claude 4.5 Opus, 59,3.
Su SkillsBench supera la concorrenza statunitense, 48,2 contro 45,3, e su GPQA Diamond segna 87,8 contro 87,0.
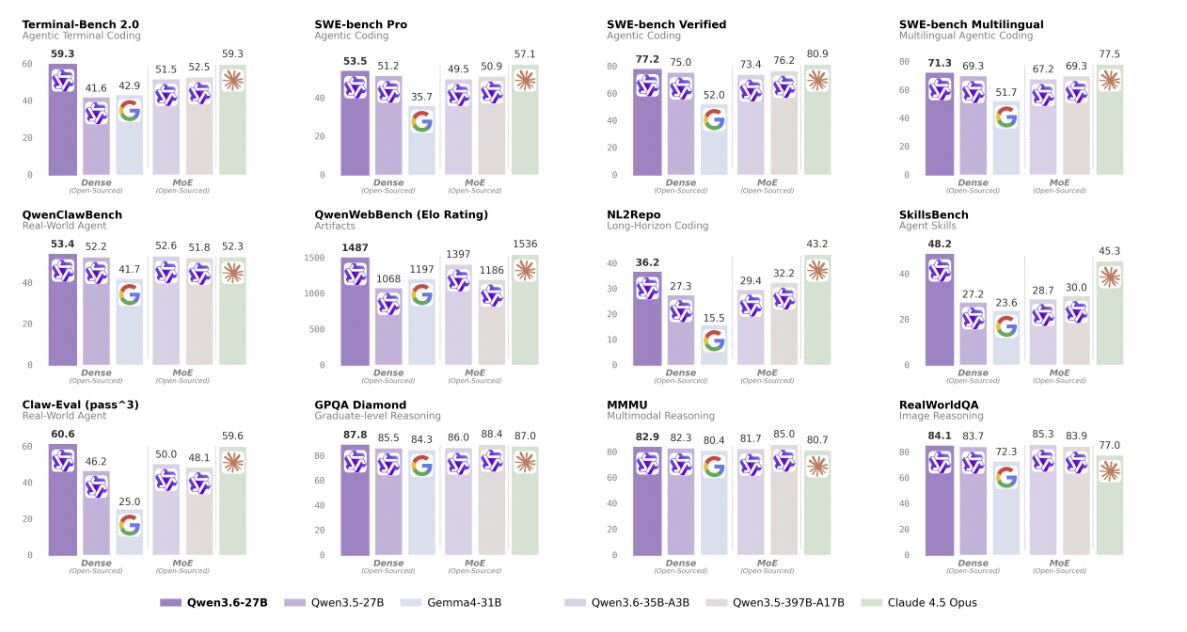
Per un modello dense da 27 miliardi di parametri, distribuibile in locale, sono numeri estremamente interessanti. Il 27B eredita dalla famiglia anche la funzione preserve thinking, l’opzione che mantiene il ragionamento interno generato nei turni precedenti per ridurre i loop e stabilizzare il comportamento degli agenti.

Qwen3.6-35B-A3B: il MoE per deploy efficienti
Qwen3.6-35B-A3B è un mixture-of-experts (MoE) sparso con 35 miliardi di parametri totali e soltanto 3 miliardi attivi per ogni token. Il rapporto di sparsità di 12 a 1 è tra i più aggressivi mai rilasciati pubblicamente. Il risultato pratico è una capacità inferenziale a costi paragonabili a un modello da 3B, mentre la conoscenza acquisita resta quella di un modello da 35B.
La velocità di generazione, misurata sull’API Alibaba, si attesta a circa 215 token al secondo, oltre sei volte quella di Max-Preview.
Sui benchmark di coding agentico il 35B-A3B compete con dense significativamente più grandi.
Su SWE-bench Verified segna 73,4.
Su Terminal-Bench 2.0 raggiunge 51,5, quasi nove punti sopra Gemma 4-31B, che attiva tutti i suoi 31 miliardi di parametri a ogni inferenza.
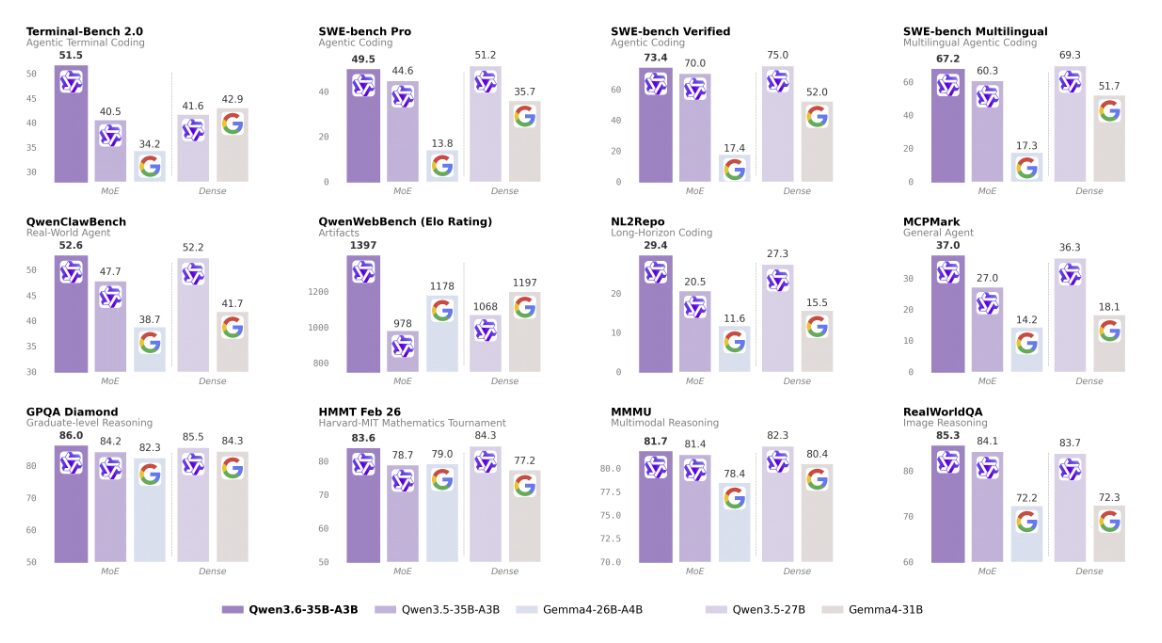
Il modello è stato rilasciato sotto licenza Apache 2.0 e si presta al deploy on-premise su workstation di fascia alta. È probabilmente la scelta più interessante, oggi, per chi vuole un assistente di sviluppo locale con buone capacità multimodali e zero fee di licenza.
Applicazioni dei nuovi modelli della famiglia Qwen
Per chi gestisce una funzione IT in Europa, la famiglia Qwen 3.6 apre a nuove opzioni architetturali interessanti. Si possono mettere in produzione tre profili di deploy in parallelo.
Il primo è l’API gestita per Max-Preview, da usare per i casi d’uso che richiedono il massimo della capacità di reasoning e che possono tollerare il flusso dati verso Alibaba Cloud.
Il modello 27B dense può essere gestito in self-hosting su una macchina con GPU di fascia alta, per workload con requisiti di confidenzialità o residenza del dato.
Il piccolo modello MoE è la scelta migliore per pipeline batch ad alta frequenza, dove la velocità di token al secondo conta quanto la qualità del singolo output.
Restano gli interrogativi che valgono per qualunque modello cinese: la conformità con il GDPR va verificata caso per caso; le politiche di trattamento dei dati richiedono attenzione, in particolare per Max-Preview.
I filtri applicati ad alcune categorie di contenuti politicamente sensibili dal punto di vista del governo cinese sono documentati e devono essere considerati per alcuni casi d’uso.
La traiettoria del mercato
I tre rilasci, presi insieme, raccontano una traiettoria chiara. Alibaba sta passando dalla pubblicazione di singoli modelli flagship a un approccio per famiglie di prodotti, con un closed-weight al vertice e open-weight di taglie diverse a coprire i casi d’uso sottostanti. Lo schema ricorda quello di Mistral. La specificità di Qwen sta nell’offerta open-source nei tagli intermedi, una scelta che continua a esercitare pressione competitiva sul listino prezzi americano.
La convergenza tecnica è ormai evidente. Tutti i modelli di frontiera supportano contesti da 256K a 1M token, ragionamento a catena di pensiero, chiamate di funzione native e capacità multimodali. Le differenze si stanno spostando verso tre dimensioni operative:
- affidabilità in produzione,
- integrazione con gli ecosistemi di sviluppo,
- rapporto fra costo e qualità su carichi reali.
Per costruire pipeline solide, la scelta più conveniente resta quella di utilizzare un’astrazione interna che permetta di instradare i carichi di lavoro verso il modello più adatto a ciascun caso d’uso, mantenendo aperta la possibilità di sostituire modelli e fornitori senza riscrivere il codice applicativo. Framework come LiteLLM, OpenRouter e le librerie native dei vari provider offrono questo livello di disaccoppiamento.
TITOLO SEO:
METADESCRIPTION:
AI CONTRIBUTION: 0-30%







Partecipa alla community