
Laboratori di ricerca e aziende tech continuano a lavorare per un futuro in cui gli LLM (large language model) saranno più funzionali di adesso. L’obiettivo è superare i limiti che oggi ne riducono utilità e applicabilità. Si va verso una nuova generazione di modelli linguistici più efficienti, meno costosi e più adatti a lavorare su problemi lunghi e articolati.
Servono sistemi capaci di leggere basi documentali molto ampie, ragionare su più passaggi, usare strumenti esterni, restare coerenti per tempi più lunghi e farlo con costi di inferenza sostenibili. È qui che la ricerca sta aprendo frontiere nuove, alcune già visibili nelle roadmap industriali, altre ancora sperimentali ma con implicazioni molto concrete per il mercato enterprise.
La prossima generazione di LLM sarà valutata sempre meno sul solo benchmark e sempre più sul rapporto tra qualità, latenza, consumo di calcolo e capacità di gestire task complessi in ambienti reali.
Indice degli argomenti:
Il futuro degli LLM: perché il mercato guarda all’efficienza prima che alla scala
Nella prima fase dell’adozione generativa, il vantaggio competitivo sembrava coincidere con la dimensione del modello. Oggi il focus si sta spostando: un LLM che costa troppo in produzione, che non regge task lunghi o che richiede troppa orchestrazione manuale diventa difficile da sostenere anche quando performa bene nei test.
Per questo motivo la ricerca si sta muovendo su più assi: architetture più leggere, gestione migliore del contesto, nuove modalità di rappresentazione del testo, uso dinamico del calcolo in inferenza e tecniche di verifica della risposta.
Mixture-of-experts e modelli più frugali
Una delle traiettorie più concrete è quella dei modelli Mixture-of-experts (MoE). Invece di attivare ogni volta l’intera rete neurale, questi approcci accendono solo una parte degli “esperti” interni a seconda del compito.
Il caso DeepSeek-V3
Il caso più noto è DeepSeek-V3, che dichiara 671 miliardi di parametri totali ma 37 miliardi attivi per token. L’obiettivo è aumentare la capacità senza far esplodere il costo operativo.

Che cosa cambia per il mercato
Se un modello mantiene prestazioni elevate riducendo il calcolo necessario per ogni richiesta, diventano più sostenibili casi d’uso ad alto volume come assistenza clienti, ricerca interna, automazione documentale, copiloti per sviluppatori e analisi di knowledge base.
Il vantaggio competitivo si sposta così dal modello “più grande” al modello “più conveniente per compito svolto”.
Le architetture ibride oltre il transformer puro
Un’altra frontiera riguarda il tentativo di superare alcuni limiti del transformer tradizionale senza abbandonarlo del tutto.
Il filone Transformer-Mamba
Il paper Jamba propone una combinazione tra blocchi Transformer, componenti Mamba e mixture-of-experts. Lo studio empirico di Nvidia sui modelli Mamba suggerisce che le architetture ibride possano mantenere buone prestazioni anche su contesti lunghi e, in alcuni setup, risultare fino a 8 volte più veloci in generazione rispetto a transformer comparabili.
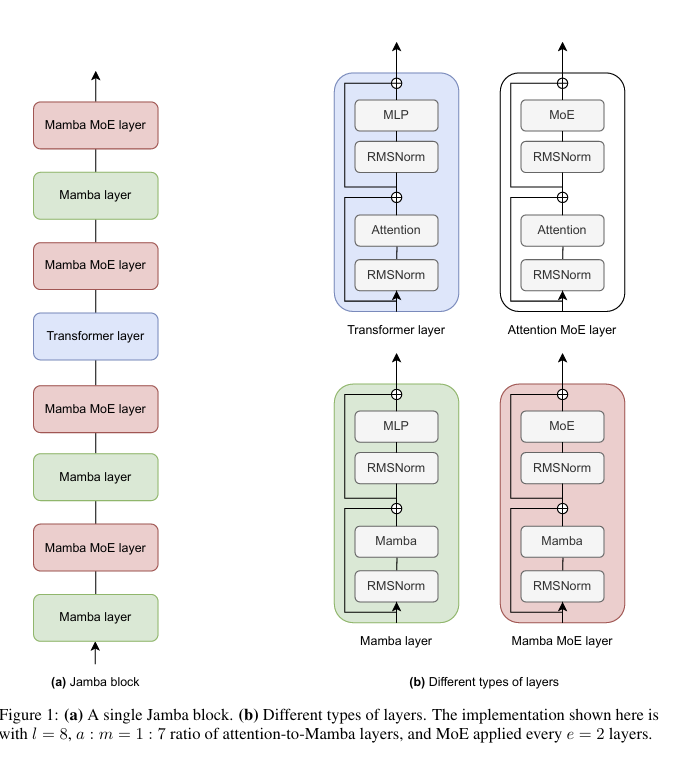
Le implicazioni per imprese e vendor
Se questa linea si consoliderà, il mercato non sarà più organizzato solo intorno alla contrapposizione tra modelli open e closed, ma anche tra famiglie architetturali diverse. Questo può avere un impatto diretto sui deployment privati, edge o on-prem, dove memoria, throughput e consumi contano quanto la qualità del modello.
I Diffusion language model entrano nel dibattito
I modelli di diffusione, finora associati soprattutto a immagini e video, stanno iniziando a essere studiati anche per il linguaggio.
Dove punta la ricerca
Il lavoro Block Diffusion del 2025 prova a combinare vantaggi dei modelli autoregressivi e di quelli diffusivi, con l’obiettivo di ottenere generazione più parallelizzabile, lunghezza flessibile e migliore efficienza in inferenza.
Perché le aziende dovrebbero seguirli
Non siamo ancora davanti a uno standard industriale alternativo agli LLM classici, ma la direzione merita attenzione. Se questi modelli matureranno, potrebbero diventare interessanti in casi d’uso dove latenza, controllo dell’output e trasformazione strutturata del contenuto sono più importanti della semplice fluidità linguistica.
Long context: il problema non è solo leggere di più, ma restare coerenti
Allargare la finestra di contesto non basta. Più cresce il numero di token, più aumenta il rischio che il modello perda il filo, disperda l’attenzione o commetta errori su relazioni distribuite in documenti molto lunghi.
La proposta dei Recursive Language Model
In quest’area il paper Recursive Language Model di MIT CSAIL propone un approccio diverso: invece di trattare tutto il contesto come un unico blocco, il modello scompone il compito, richiama copie di sé stesso e lavora per parti. Gli autori sostengono che questo schema permetta di gestire input fino a due ordini di grandezza oltre la context window del modello di base.
L’impatto sui casi d’uso enterprise
Se questa impostazione si confermerà, il beneficio per le imprese sarà diretto in ambiti come due diligence, audit documentale, analisi contrattuale, supporto tecnico su repository estesi, compliance e ricerca normativa.
Il punto chiave è che il valore non arriverà solo da finestre di contesto più grandi, ma dalla capacità di scomporre correttamente il problema.
Nuove unità di rappresentazione: non solo token
Una parte importante della ricerca sta mettendo in discussione l’idea che il token resti l’unità ottimale per ogni tipo di elaborazione linguistica.
Byte, patch e rappresentazioni alternative
Il paper Byte Latent Transformer propone di lavorare su byte e patch dinamiche invece che sui token classici, con l’obiettivo di migliorare efficienza e robustezza.
Il caso DeepSeek-OCR e la compressione visiva
Più radicale, e molto interessante per il business, è il caso DeepSeek-OCR, che rappresenta lunghi contenuti testuali tramite compressione visiva. Nel paper gli autori mostrano che il modello supera GOT-OCR2.0 usando 100 vision token per pagina e fa meglio di MinerU2.0 con meno di 800 token visivi.
Perché questa frontiera conta per la document AI
Per chi lavora con PDF, moduli, fatture, manuali, tavole tecniche e schermate, questa linea di ricerca può incidere molto sui costi. Se il contenuto documentale può essere compresso e trattato in modo più efficiente prima della fase di reasoning, la document AI potrebbe diventare meno onerosa e più scalabile nei processi ad alto volume.
Test-time compute: il modello usa più calcolo solo quando serve
Un’altra frontiera molto rilevante è quella del test-time compute, cioè la possibilità di allocare più calcolo in fase di inferenza solo sui task davvero complessi.
Cosa sta emergendo dagli studi
Il paper Scaling up Test-Time Compute with Latent Reasoning esplora forme di ragionamento latente che non dipendono soltanto dalla produzione di più token. Un altro studio, Scaling Test-time Compute for LLM Agents, mostra che aumentare il calcolo in inferenza può migliorare anche gli agenti, soprattutto quando si combinano campionamento, revisione, verifica e merging dei risultati.
L’effetto sui modelli di prezzo e sulla governance
Per il mercato questo significa che l’AI tenderà a essere tariffata e governata meno per volume di testo e più per intensità del lavoro cognitivo richiesto. Per le aziende vuol dire introdurre policy nuove: quando conviene far “riflettere” di più il modello, quando fermarlo prima, su quali task autorizzare costi più alti e dove imporre soglie di contenimento.
Self-verification: la qualità passa anche dalla capacità di controllarsi
Una linea di ricerca sempre più osservata riguarda la capacità del modello di verificare le proprie risposte.
Gli studi più recenti
Due lavori recenti, Incentivizing LLMs to Self-Verify Their Answers e Learning to Self-Verify Makes Language Models Better Reasoners, mostrano che addestrare il modello alla self-verification può migliorare non solo il controllo dell’errore, ma anche la qualità del reasoning.
Le implicazioni nei contesti regolati
Questo non elimina il problema delle allucinazioni, ma sposta la ricerca in una direzione più utile per il business: non solo generare risposte, ma anche valutarne la correttezza. Per banche, assicurazioni, sanità, PA e industria regolata, questo aspetto può fare la differenza tra un assistente interessante e un sistema effettivamente integrabile nei processi.
La prossima fase del mercato non premierà soltanto chi dispone del modello più potente. Premierà chi saprà combinare meglio architettura, orchestrazione, memoria, strumenti esterni, verifica e costo operativo.
Le tre conseguenze per le imprese
La prima è che la scelta del modello non può più essere separata dal tipo di workload: chat, coding, document intelligence, agenti e retrieval enterprise seguiranno traiettorie diverse.
La seconda è che l’efficienza diventerà un fattore competitivo quanto la qualità. Ridurre il costo per task utile significa ampliare subito il numero di casi d’uso sostenibili.
La terza è che l’affidabilità non arriverà da una singola innovazione, ma dall’integrazione di più livelli: gestione del contesto, memoria esterna, uso di tool, verifica e allocazione dinamica del calcolo.
Una fase meno spettacolare, ma più importante per il business
Il futuro vicino non sembra quello di modelli totalmente nuovi che mandano in pensione gli LLM. Sembra piuttosto quello di LLM che diventano commodity: più sobri nei costi, più lunghi nel respiro, più modulari, più multimodali e, in alcuni casi, più capaci di controllarsi da soli.
Ma è proprio in questa maturazione tecnica che si giocherà la vera adozione enterprise.





Partecipa alla community