L’intelligenza artificiale è una realtà che sta ridefinendo le modalità di esecuzione del lavoro di compliance. Tuttavia, il dibattito sull’AI in questo settore è stato finora dominato più dall’entusiasmo (hype) che da prove concrete. Il lancio dell’EQS AI Benchmark Report cambia radicalmente questo scenario.
Questo report, creato da EQS Group, azienda specializzata nella digitalizzazione della compliance, in collaborazione con l’associazione tedesca Berufsverband der Compliance Manager (BCM), è il primo benchmark del settore interamente costruito attorno a sfide reali di compliance ed etica. Non sono state poste domande teoriche, ma i modelli AI più potenti di oggi sono stati testati rispetto al tipo di compiti che i professionisti della compliance gestiscono quotidianamente. L’obiettivo è fornire una comprensione basata sull’evidenza di dove l’AI può apportare efficienza e insight, e dove il giudizio umano rimane insostituibile.
Le capacità dei modelli AI di frontiera sono definite da pochissimi laboratori globali (come OpenAI, Google e Anthropic). Il loro lavoro definisce in modo efficace le capacità che le funzioni di compliance ed etica possono utilizzare, rendendo essenziale comprenderne i punti di forza e di debolezza attuali.
Indice degli argomenti:
La metodologia rigorosa di EQS: replicare la realtà quotidiana
Per garantire che il benchmark riflettesse la complessità e la natura sfumata del lavoro di compliance, sono stati valutati sei modelli AI di frontiera attraverso 120 compiti che coprono 10 aree tematiche centrali della compliance e dell’etica. Queste aree includono:
- l’analisi regolatoria,
- la gestione dei terzi,
- il supporto alle indagini (Speak-up),
- la valutazione dell’efficacia del programma.
Per ottenere un risultato che rispecchiasse la realtà operativa, EQS ha incorporato contenuti e dati reali forniti da clienti e partner, assicurando che il benchmark non fosse “avulso dalle realtà quotidiane”. Ogni modello è stato valutato in base all’accuratezza, all’affidabilità e all’utilità pratica.
Le 120 attività sono state suddivise in tre tipi principali:
- Multiple Choice (50 attività),
- Structured Output (50 attività)
- Open-ended (20 attività).
Sebbene le domande a risposta multipla siano oggettivamente valutabili, la maggiore variazione di performance si è registrata nei compiti più aperti e complessi, come la produzione di report o la definizione di politiche. In totale, la documentazione utilizzata per i compiti includeva centinaia di pagine di contesto, come policy, report di screening e trascrizioni di interviste, per simulare le sfide reali.
L’AI supera le aspettative nella compliance operativa
Uno dei risultati più sorprendenti del benchmark è che i modelli AI attuali sono molto più capaci di quanto i professionisti della compliance si aspettino. In compiti strutturati come la classificazione, l’estrazione e il ranking dei rischi, i modelli AI leader hanno fornito risultati coerenti, spesso superando le aspettative dei rater umani.
Ciò che molti considerano ancora futuristico è, di fatto, già una realtà: l’AI può farsi carico di una quota significativa del lavoro ripetitivo di compliance oggi. Questo è un insight cruciale, in quanto libera i professionisti per concentrarsi sul giudizio, sulla strategia e su attività a più alto valore.
Le aree in cui i modelli hanno dimostrato maggiore forza sono i compiti più diretti e strutturati:
- Matching / Mapping di set di dati (con performance media superiore al 91,8%).
- Rule Application & Recommendation (applicazione di regole e raccomandazioni).
- Categorization / Classification (categorizzazione e classificazione).
- Ranking / Prioritization (classificazione/prioritizzazione).
- Decision Making (prendere decisioni presentate con una situazione e un set di regole o policy).
La classifica dei modelli e la variazione di performance
Il benchmark EQS ha stabilito una classifica chiara dei modelli, dimostrando che “AI non è uguale a AI” e che le differenze tra i modelli non sono marginali. In alcune categorie, i modelli migliori sono risultati da due a tre volte più forti dei modelli più deboli.
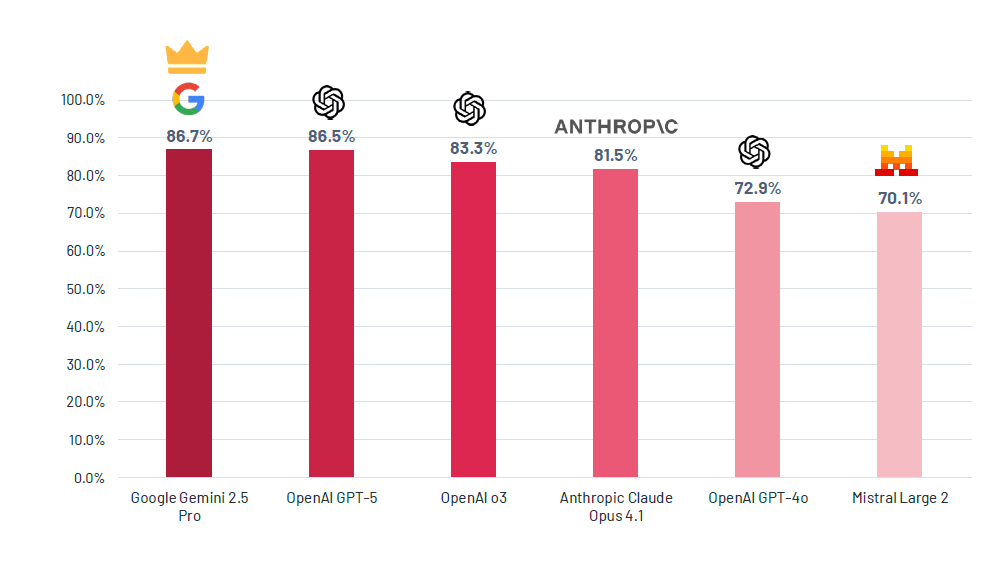
Google Gemini 2.5 Pro ha raggiunto il punteggio complessivo più alto con 86,7%, dimostrandosi un allrounder robusto in tutte le categorie di compiti. Subito dietro, OpenAI GPT-5 ha ottenuto un impressionante 86,5%, evidenziando una rapida convergenza delle capacità ai vertici. Il predecessore di GPT-5, OpenAI o3, ha seguito con 83,3%, illustrando la rapidità del ciclo di iterazione.
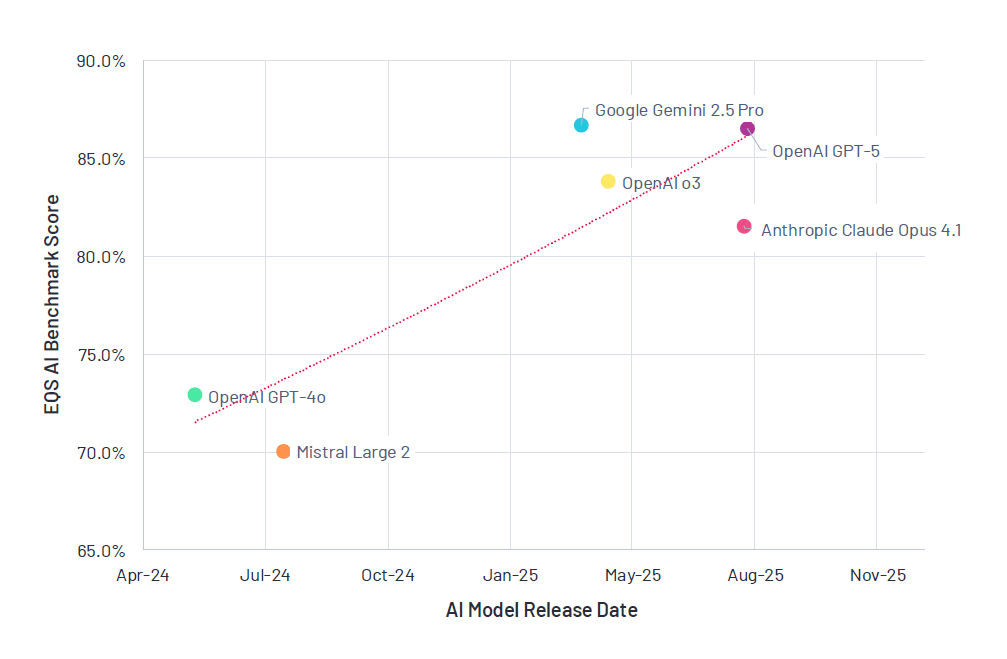
I modelli rilasciati nel 2024, come GPT-4o (72,9%) e Mistral Large 2 (70,1%), si sono classificati agli ultimi posti. Questa differenza è sorprendente: Mistral Large 2, rilasciato nel luglio 2024, ha avuto una performance inferiore di oltre 17 punti percentuali rispetto al vincitore Gemini 2.5 Pro, rilasciato solo nove mesi dopo. Ciò riflette il salto generazionale tra i modelli e la rapidità con cui anche i modelli ampiamente adottati possono diventare obsoleti.
Inoltre, il leaderboard è fluido: le performance cambiano drasticamente. I team di compliance non possono permettersi di trattare l’AI come una capacità unica, ma devono optare per una selezione, test e valutazione continua e attenta.
Le aree di forza e di debolezza
La scelta del modello giusto è fondamentale, soprattutto quando si affrontano aree ambigue. Mentre i modelli 2025 hanno performato tutti sopra il 95% in categorie semplici come Matching/Mapping, le differenze si sono accentuate notevolmente nelle sfide analitiche più complesse.
Nelle categorie più difficili, come la Data Analysis (analisi dei dati), la variazione di performance ha raggiunto i 60 punti percentuali tra il modello migliore (Gemini 2.5 Pro, 88%) e il peggiore (GPT-4o, 28,0%). Similmente, nella Gap Analysis/Comparison (analisi delle lacune/confronto), Gemini 2.5 Pro ha primeggiato con 84,8%, mentre Mistral Large 2 è sceso al 50,3%.
Per i professionisti della compliance, questo significa che compiti come l’analisi complessa dei dati, l’analisi delle lacune e le valutazioni più impegnative sono le aree in cui persino i modelli più capaci faticano. Più un modello è ambiguo o meno performante in un’area, più è necessario un “componente umano nel circuito” (human in the loop).
Nonostante Gemini 2.5 Pro sia un performer estremamente consistente, ci sono categorie in cui altri modelli lo superano, ad esempio nell’Open-ended (compiti aperti, come la redazione di report o briefing per il consiglio di amministrazione). In questa categoria, GPT-5 ha superato Gemini 2.5 Pro, con i rater umani che hanno lodato in particolare i risultati di GPT-5.
Affidabilità e l’illusione delle allucinazioni
Un aspetto cruciale per i professionisti della compliance è l’affidabilità, dato che le allucinazioni (l’invenzione di fatti) sono ancora una preoccupazione.
Con grande sorpresa, il benchmark EQS ha rilevato un tasso di allucinazioni molto basso su tutti i compiti e i modelli: in totale, sono state identificate solo tre istanze di allucinazioni ovvie su un totale di risultati rilevanti, pari a un tasso dello 0,71%. Questo basso tasso è probabilmente dovuto al fatto che il prompting per i compiti del benchmark incorporava già le migliori pratiche per evitare le allucinazioni e forniva contesti concreti su cui i modelli dovevano lavorare.
Per quanto riguarda la Reliability Rate (tasso di affidabilità), misurato ripetendo gli stessi compiti a risposta multipla tre volte, tutti i modelli hanno mostrato risultati elevati, con o3 e Claude Opus 4.1 che hanno raggiunto il 98,3%. Ciò suggerisce che per i compiti più chiari e strutturati, i modelli attuali sono altamente consistenti.
L’era degli agenti AI e l’automazione dei flussi di lavoro
L’Insight 3 del report evidenzia che gli Agenti AI affidabili e di grande impatto nella compliance sono molto vicini. Il benchmark ha mostrato che i modelli eccellono nei sotto-compiti ben strutturati, ma vacillano quando l’ambiguità aumenta. Questo è l’ambiente esatto in cui gli “agenti” AI – sistemi che collegano più sotto-compiti sotto la supervisione umana – prospereranno.
EQS ha intenzionalmente progettato diversi compiti in sequenza per riflettere flussi di lavoro più ampi tipici di un programma di compliance ed etica, come la gestione delle dichiarazioni di conflitto di interessi (COI). Analizzando questa sequenza, è emerso che i compiti semplici, come la selezione della categoria più idonea per una divulgazione di COI, hanno registrato una performance del 100% (miglior modello) e possono non richiedere la revisione umana.
Compiti che richiedono l’identificazione di informazioni di follow-up necessarie per valutare il rischio ABAC (Anti-Bribery and Anti-Corruption) di una divulgazione di COI, invece, hanno raggiunto il 72,5% (miglior modello), indicando che è ancora necessario un esperto umano nel circuito.
Questa capacità di concatenare compiti trasformerà l’AI da semplice assistente a co-lavoratore. L’AI sarà in grado di gestire revisioni di divulgazione, eseguire valutazioni di terze parti o aggiornare valutazioni del rischio in autonomia (con il necessario human oversight).
Come agire adesso: le linee guida
Il report fornisce ai professionisti della compliance linee guida chiare su come convertire questi insight in azioni per migliorare l’efficienza:
- Iniziare in piccolo e iniziare ora: non bisogna aspettare un modello AI “perfetto” con un punteggio del 100%. Poiché i modelli attuali gestiscono in modo affidabile compiti strutturati e ripetitivi (come classificazione e ranking), i team dovrebbero identificare 1-2 processi ad alto volume per avviare progetti pilota.
- Scegliere il modello giusto per il lavoro: le prestazioni variano in modo significativo, specialmente nei compiti ambigui. I team non dovrebbero adottare un approccio one-model-fits-all. Ad esempio, si potrebbe utilizzare un modello per l’analisi complessa dei dati (dove Gemini eccelle) e un altro per la stesura professionale di un briefing pronto per gli stakeholder (dove GPT-5 è forte). I vendor di software AI dovrebbero essere in grado di spiegare quali modelli utilizzano e perché.
- Prompting granulare per risultati specifici: i modelli più recenti, specialmente quelli del 2025, possono gestire istruzioni estremamente complesse e sfumate. I team di compliance non devono sottovalutare quanto possano essere specifici e dettagliati nelle loro richieste, ottenendo risultati strutturati esattamente nel formato desiderato.
- Mantenere l’umano nel circuito dove il giudizio è fondamentale: l’AI rimane un “moltiplicatore di forza”, non un sostituto. Compiti che implicano investigazioni complesse, valutazione dei rischi culturali, o la redazione di report altamente sfumati richiedono ancora la supervisione professionale.
Focus sui contendenti: i leader della performance AI
I due modelli che hanno dominato il benchmark meritano un’analisi approfondita.
Google Gemini 2.5 Pro: Gemini 2.5 Pro di Google DeepMind è il vincitore assoluto con l’86,7%. È l’unico modello che ha fornito risultati solidi nella categoria Data Analysis (88% rispetto al 62% del secondo classificato) e si è distinto nella Gap Analysis/Comparison (84,8%). Un vantaggio tecnico significativo è la sua finestra di contesto di 1 milione di token (circa 1.500 pagine di contenuto). Questo lo rende la scelta ideale per la gestione e l’analisi di molti documenti o set di dati di grandi dimensioni.
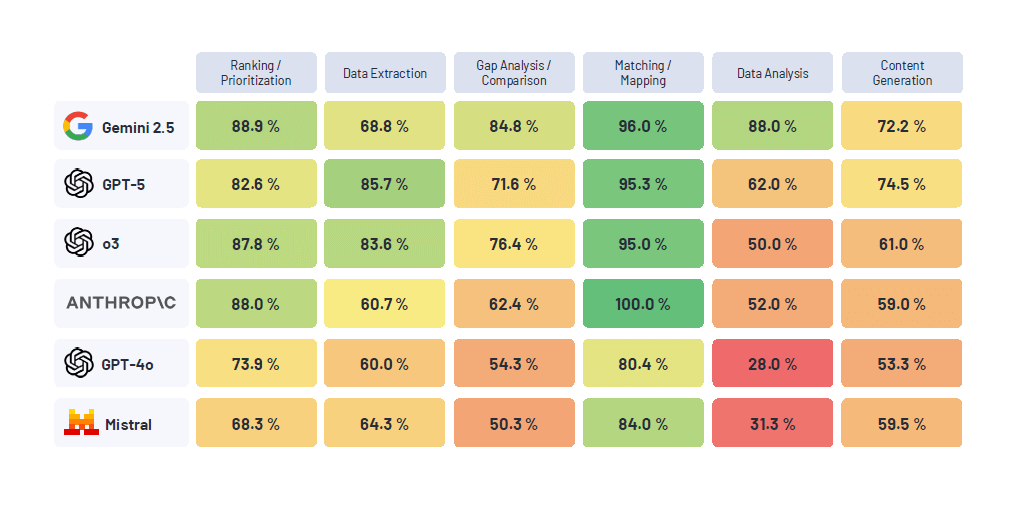
OpenAI GPT-5: GPT-5, lanciato nell’agosto 2025, è arrivato a un’incollatura da Gemini (86,5%). Essendo il modello che alimenta ChatGPT, la sua performance è cruciale. GPT-5 ha eccelso in categorie simili a Gemini, ma ha superato il vincitore nei compiti Open-ended, come la redazione di briefing esecutivi, politiche e materiali di formazione. Gli esperti di Compliance hanno ripetutamente lodato l’output di GPT-5. GPT-5 è anche altamente controllabile, permettendo di personalizzare i risultati attraverso un prompting molto granulare. Le sue debolezze risiedono principalmente nell’analisi dei dati e nella gap analysis, dove il suo score è significativamente inferiore a quello di Gemini.
Guardrail, governance e il futuro della compliance
Il progresso AI continua a una velocità senza precedenti, con il divario tra i modelli che aumenta in modo significativo nel giro di pochi mesi. Se le “leggi di scala” (l’aumento della potenza di calcolo porta a migliori performance) continueranno a valere, ci si possono aspettare modelli ancora più utili per la compliance & etica in futuro.
Tuttavia, con l’aumento delle capacità arrivano anche le sfide di governance. I sistemi AI sono non deterministici, rendendo cruciale osservare la loro performance, tracciare le loro azioni e i loro output in solidi audit trail e migliorarne l’esplicabilità. In un campo ad alto rischio come la compliance, è necessario applicare rigidi criteri di valutazione prima di fidarsi che i sistemi AI gestiscano interi flussi di lavoro.
Come sottolineato nel report, la funzione di compliance & etica deve affrontare due aree interconnesse: i nuovi rischi che l’AI introduce e come l’AI può essere sfruttata per aumentare l’efficienza. Solo sviluppando una solida comprensione dell’AI attraverso l’applicazione pratica, i team di compliance possono progettare la governance corretta per affrontare i rischi etici e di sicurezza.
L’AI-enhanced Compliance diventerà la norma. La sfida per i professionisti della compliance non è accettare o rifiutare l’AI, ma assumersi la responsabilità di navigare le sue opportunità e i suoi rischi con integrità e lungimiranza, assicurando di avere un posto al tavolo per plasmare il futuro della tecnologia.
L’EQS AI Benchmark può essere scaricato gratuitamente sul sito di EQS qui.
Inoltre, i risultati verranno presentati durante un webinar in programma martedì 18 novembre alle ore 11:00 (registrazione gratuita).