
Immaginate di entrare in un laboratorio – monitor ovunque, grafici che scorrono impetuosi, ricercatori che aspettano il via libera per lanciare decine di job. Fino a ieri lo spettacolo era sempre lo stesso: code lunghe, server sovraccarichi in alcuni momenti e inspiegabilmente vuoti in altri. Oggi, quando quelle stesse persone accedono alla console di ScaleTech, trovano un ambiente diverso, quasi “vivo”.
Indice degli argomenti:
Cos’è ScaleTech
ScaleTech è un’unica console, sviluppata dalla società Laser Romae, che orchestra server on-premise, cloud pubblici e cluster HPC, con un “cervello” di intelligenza artificiale che prevede il carico di lavoro e sposta le risorse prima che nascano colli di bottiglia.
Un AI Orchestrator che “prevede il futuro”
Al cuore della piattaforma ScaleTech pulsa un “AI Orchestrator” che, come un direttore d’orchestra esperto, ascolta i primi accenni di crescendo (picchi di CPU, richieste GPU, traffico I/O) e alza la bacchetta prima che la musica esploda. Grazie a un filtro statistico che modella i dati storici e a reti neurali LSTM capaci di cogliere stagionalità e variazioni improvvise, ScaleTech prevede con anticipo quando il carico salirà. In quel preciso istante – senza intervento umano – accende nodi cloud, rialloca workflow, sposta container. Così, quando il picco arriva davvero, l’infrastruttura è già pronta e i job fluiscono senza una pausa.
Il risultato si tocca con mano: nei test interni i tempi di training di modelli di deep learning si sono accorciati fino al 40 %, mentre la bolletta cloud è scesa fra il 15 e il 25 %.
I principali punti di forza dell’AI Orchestrator
1. Exponential Smoothing statistico: modella i trend nei dati.
2. Reti LSTM/Bi-LSTM: impara pattern giornalieri e stagionali.
3. Decision engine: confronta i modelli e attiva GPU o nodi cloud 30 min prima del picco.
4. Ottimizzazione multi-obiettivo: costo, urgenza, emissioni CO₂ entrano nell’equazione.
5. Feedback loop: il modello si ri-addestra in automatico se la realtà cambia.
Risultato misurato: -40 % sui tempi di training ML, -15 ÷ 25 % di spesa cloud, -30 % di consumo energetico del datacenter.
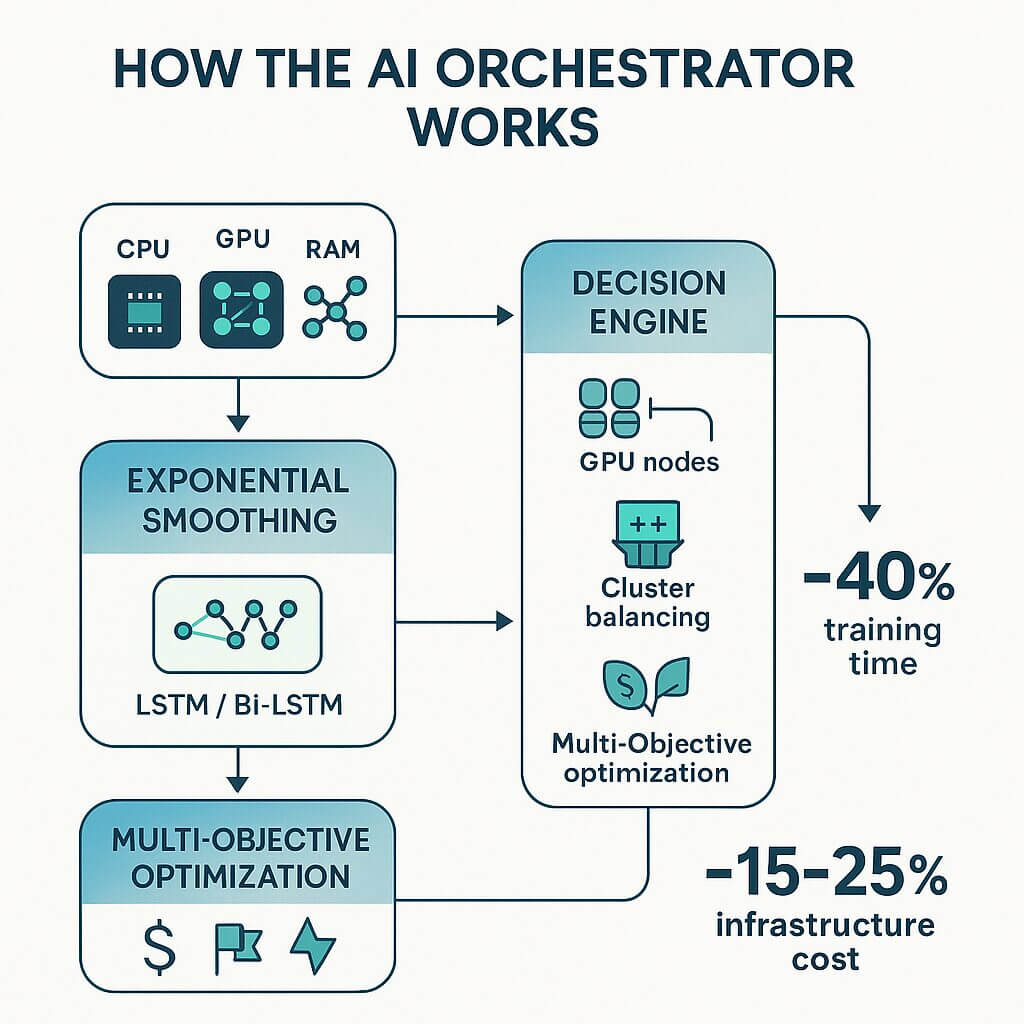
Come funziona l’AI Orchestrator
• Pipeline “smooth & learn”: una fase di Exponential Smoothing pulisce le metriche (CPU, GPU, RAM) e mette in evidenza trend e stagionalità ricorrenti; i dati normalizzati alimentano reti LSTM/Bi-LSTM che catturano correlazioni di lungo periodo.
• Decisioni proactive: il motore sceglie il modello più accurato in tempo reale, fonde le previsioni se necessario e traduce il risultato in azioni: provisioning di nodi GPU, spostamento di job tra cluster o, al contrario, spegnimento di risorse inutili.
• Ottimizzazione multi-obiettivo: l’algoritmo bilancia costi cloud, priorità di business e consumo energetico, non solo CPU e RAM.
• Risultato concreto: nei test interni, l’AI Orchestrator ha ridotto fino al 40 % i tempi di training ML e abbassato del 15-25 % la spesa in infrastruttura grazie all’accensione preventiva (e temporanea) di nodi extra.
I numeri chiave di ScaleTech
A certificare queste impressioni è un articolo scientifico pubblicato su Algorithms. Ecco tre risultati che spiccano:
- Ingestione dati: Apache Kafka ha gestito 714 msg/s contro i 672 msg/s di RabbitMQ sotto lo stesso carico, garantendo al contempo una latenza più bassa e maggiore tolleranza ai guasti MDPI.
- Analisi real-time: Spark Streaming ha ridotto i tempi di elaborazione rispetto a Hadoop, offrendo insight quasi immediati dove il batch introduceva secondi di attesa MDPI.
- Architettura a microservizi: sotto uno stress test da 10mila utenti, la versione a microservizi ha servito oltre 366 k richieste con throughput e tempi di risposta nettamente migliori della controparte monolitica, che crollava oltre i 9 s di latenza media MDPI.
Nelle prove di laboratorio, l’ingestione dati tramite Kafka ha superato i 700 messaggi al secondo, il processing real-time con Spark Streaming ha strappato un terzo dei secondi di latenza a Hadoop, e l’architettura a microservizi ha retto uno stress test da diecimila utenti servendo più di tre volte le richieste che abbattevano il vecchio monolite, con risposte sotto i 10 millisecondi.
Cosa significano questi numeri, al di fuori dei grafici? Per le compagnie che gestiscono immagini satellitari, vogliono dire catene di filtraggio e mosaicatura concluse prima che il satellite completi l’orbita successiva.
Per i laboratori farmaceutici con server interni protetti, significano report pronti alle 8 del mattino senza turni notturni a controllare script.
Per i data scientist che addestrano reti gigantesche, vogliono dire GPU rese disponibili “just-in-time”: non un minuto prima, non un minuto dopo.

Perché ScaleTech è anche sostenibile
• Server mai a vuoto, quindi meno energia sprecata.
• Decisioni cloud vs on-prem basate sul mix di prezzo orario e carbon-intensity della regione.
• Dashboard eco-score inclusa: vedi quanta CO₂ eviti ogni mese.
C’è anche un lato verde: poiché ScaleTech spegne i nodi appena il picco rientra, i server non girano a vuoto e l’energia risparmiata incide tanto sul budget quanto sull’impronta di carbonio. Un pannello dedicato mostra quanta CO₂ si è evitata mese dopo mese – e non è raro veder spuntare un sorriso di sorpresa nelle review di progetto.
ScaleTech: perché conta per la tua azienda o il tuo laboratorio
• Meno attese: con i picchi previsti in anticipo, le code di job si svuotano; i risultati arrivano quando servono, non “quando tocca”.
• Risorse usate al 100 %: niente server che ronfano a vuoto né bollette cloud gonfie.
• Flessibilità totale: stesso workflow su cluster privati, cloud pubblici o HPC, con dati sensibili che restano on-premise.
• Condivisione del know-how: sandbox versionate e riutilizzabili riducono la duplicazione di codice e accelerano nuovi progetti.
Conclusioni
ScaleTech sviluppata da LaserRomae unisce prestazioni dimostrate in laboratorio a un’orchestrazione AI che assicura elasticità, risparmio e zero colli di bottiglia. Se vuoi approfondire i dettagli del paper o capire come l’AI Orchestrator potrebbe adattarsi ai tuoi carichi specifici, contattaci: possiamo preparare un focus o una demo su misura.
Se queste storie solleticano la tua curiosità, chiedici una demo: porteremo il tuo dataset e lasceremo che sia ScaleTech a parlare. Perché il suo vero fascino è vederla all’opera, quando anticipa il futuro e fa sembrare facile ciò che, fino a ieri, era un inevitabile collo di bottiglia.


