
La matematica è necessaria per “fare” intelligenza artificiale? Quale matematica serve? Si tratta di un argomento molto caldo in questo periodo, in cui i termini intelligenza artificiale, machine learning e deep learning sono all’ordine del giorno nelle aziende, sui social e sulle testate giornalistiche di settore; in parallelo aumentano i siti web che pubblicizzano corsi di formazione su questi argomenti.
Indice degli argomenti:
Intelligenza artificiale e matematica
I casi di maggior successo nel campo dell’intelligenza artificiale hanno alla base la conoscenza degli algoritmi e della matematica che li descrive. Non a caso, si dice che il machine learning è fatto di matematica, di algoritmi è un po’ di programmazione; quest’ultima componente è quella che all’apparenza è più visibile nell’immediato, ma attenzione a non pensare che sia l’unica o la più importante, perché non è sufficiente saper programmare per sviluppare sistemi efficaci basati sull’intelligenza artificiale.
Dunque, possiamo facilmente rispondere alla domanda se la matematica è necessaria: certamente sì e in quale misura lo sia dipende dal contesto di utilizzo.
- Se si studiano gli algoritmi per cercare di migliorarli o crearne di nuovi, indubbiamente bisogna essere in grado di formulare delle ipotesi e dimostrare tesi, serve quindi un bagaglio matematico il più vasto possibile e la capacità di astrarre e generalizzare.
- Se lo scopo è implementare un algoritmo, sicuramente bisogna conoscere il linguaggio di programmazione scelto ma anche la formulazione matematica dell’algoritmo e il significato e l’effetto di tutti i suoi parametri. A questo si aggiunge anche la conoscenza sia della matematica sia di programmazione, per un’implementazione ottimizzata in velocità, precisione, spazio di memoria occupato, scalabilità.
- Se lo scopo è utilizzare gli algoritmi esistenti e già implementati e disponibili, come moduli o library di un linguaggio di programmazione, è comunque necessario conoscerne la definizione matematica almeno per capire lo scopo dei parametri e il loro range, l’applicabilità a un contesto e l’interpretazione dei risultati.
- Se qualcuno pensa che per sviluppare software che fanno uso di machine learning o reti neurali basti sapere come chiamare un metodo o un servizio di terze parti, è opportuno sottolineare che il ciclo di sviluppo prevede delle fasi di ottimizzazione e aggiustamento parametri tale per cui in caso di contesto non ottimale potrebbe iniziare un’odissea di tentativi di miglioramento, fino probabilmente al ridimensionamento o all’abbandono del progetto per insufficiente precisione del modello.

Quale matematica serve per l’intelligenza artificiale
Fin qui abbiamo trovato più di un motivo per conoscere gli aspetti matematici degli algoritmi che costituiscono l’intelligenza artificiale; questo non vieta affatto che ci sia anche un motivo tra i più nobili quale la curiosità e il piacere di conoscere i dettagli e di un algoritmo e gli aspetti applicativi. Nonostante tutto bisogna ammettere che a livello divulgativo omettere o posticipare la formulazione matematica a volte rende più efficace la descrizione e la comprensione di un algoritmo. Quindi passiamo alla seconda domanda, più che lecita: che matematica serve per lavorare con intelligenza artificiale, machine learning, deep learning.
Si può dire che quello che serve è principalmente raggruppato in tre aree principali della matematica oltre alla capacità di generalizzazione e astrazione che è tipica di queste discipline:
- analisi matematica e in particolare calcolo integrale e differenziale
- algebra
- probabilità e statistica.
Di seguito vengono descritti alcuni aspetti utili di queste aree della matematica, insieme a qualche esempio per una migliore comprensione del contesto.
Algebra
La matematica permette una rappresentazione formale della realtà che va oltre l’esperienza quotidiana; se normalmente siamo abituati a pensare in due o tre dimensioni, ovvero il piano e lo spazio intorno a noi, con la matematica si possono fare generalizzazioni a N dimensioni. Oltre le tre dimensioni non siamo capaci di rappresentare tali entità ma il formalismo matematico permette di trattarle indipendentemente dalla capacità di visualizzazione. Questo è un argomento fondamentale perché normalmente l’input di un algoritmo non è uno scalare ma è un vettore x di N componenti
ognuna delle quali è una caratteristica del dataset che si sta analizzando; se il dataset è una tabella ogni caratteristica rappresenta una delle N colonne e ogni vettore contiene i valori di un’intera riga di questa tabella. Questo vettore può essere visto come un punto in uno spazio vettoriale di N dimensioni. Per fare un esempio molto attuale supponiamo di voler studiare la probabilità di sopravvivenza degli individui che si ammalano di COVID. Si può prendere in considerazione una sola variabile come l’età degli individui e in questo caso avremmo un modello a una dimensione; ma se volessimo prendere in considerazione più variabili insieme, come età, sesso, presenza di altre patologie, gruppo sanguigno, saremmo già a 4 variabili quindi il vettore di input sarebbe di 4 componenti x = (x1, x2, x3, x4) e non potremmo rappresentarlo graficamente.
Un altro argomento fondamentale da conoscere è rappresentato dalle matrici, le operazioni tra matrici e alcuni “trucchi” utili quando molti elementi hanno valore zero oppure gli elementi significativi sono raggruppati a blocchi. La “semplice” regressione lineare, dati N punti Xj di p componenti in input, fornisce in output Y secondo il modello così descritto
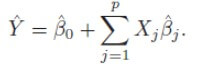
che si può anche scrivere nella forma più compatta
dove X è una matrice di N righe e p colonne (N x p), ogni riga è un vettore di input e le p colonne sono le caratteristiche note in base a cui si predice l’output Y. La soluzione del problema consiste nel trovare i migliori coefficienti βj che minimizzino la somma degli scarti quadratici. La soluzione si scrive in modo compatto nel seguente modo:
Senza aggiungere altro è evidente che per capire anche il più semplice tra gli algoritmi, che normalmente è uno dei primi a essere presentato nella relativa letteratura, richiede la conoscenza delle matrici, la matrice trasposta, l’inversa, il prodotto tra matrici e a questo sono da aggiungere tutte le considerazioni statistiche sull’applicabilità del modello, sulla validità e sull’interpretazione dei risultati. Algoritmi di classificazione e regressione più potenti come per esempio SVM (Support Vector Machine) richiedono analoghe conoscenze matematiche.
Calcolo differenziale
Gli algoritmi lavorano sull’ottimizzazione di una funzione che rappresenta l’obiettivo del modello. Nel caso di metodi statistici di apprendimento, come ML e DL, l’ottimizzazione equivale a minimizzare una funzione di costo che esprime l’errore con cui l’algoritmo predice l’output sulla base dei dati di input. La ricerca dei minimi di funzione richiama subito le derivate e vari metodi di ricerca dei punti di minimo. Diversi algoritmi sono basati sulla cosiddetta “discesa del gradiente” che consiste in termini pratici nell’avvicinarsi a un punto di minimo seguendo la pendenza della curva nella direzione in cui si trova il minimo. La definizione di gradiente di una funzione f(x) in N variabili è:
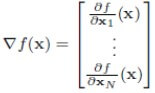
ovvero il vettore delle derivate parziali della funzione rispetto a ogni variabile. In altre parole il gradiente è un vettore che punta nella direzione in cui una funzione cresce, quindi l’algoritmo consiste nel calcolare il gradiente in un punto e spostarsi al punto successivo nella direzione opposta, ovvero quella in cui la funzione decresce, avvicinandosi così al minimo. La ricerca dei punti di minimo può essere effettuata anche con algoritmi genetici o altri metodi dell’analisi matematica che richiedono buona dimestichezza nella materia.
Un altro caso la cui soluzione viene tradotta nella ricerca di un minimo e il problema del commesso viaggiatore (Travelling Salesman Problem): trovare il tragitto di minima percorrenza che passi per tutte le città una sola volta e tornare a quella di partenza. In questo caso il problema viene modellato con un grafo, ovvero un insieme di nodi connessi da archi; lo studio di questo modello richiede una buona conoscenza della teoria dei grafi. Ad ogni arco viene associato un costo e il costo totale è la somma dei costi dei singoli archi percorsi nel cammino. La soluzione richiede che tra tutti i possibili cammini si trovi quello con il costo minimo. Notiamo che così senza saperlo si è aggiunta un’altra branca della matematica al bagaglio scientifico per l’intelligenza artificiale. I grafi sono utilizzati anche in altri contesti come per esempio lo studio dei social e in generale in quella che viene chiamata “network analysis”, in tutti quei contesti ove è conveniente modellare il sistema come un insieme di entità connesse da archi.
Calcolo integrale
Sebbene non sia necessario calcolare integrali la conoscenza del significato e dell’uso dell’integrale fa parte delle competenze consigliate. Il concetto principale è quello di misura e nel caso particolare di funzioni a una variabile di area sottesa da una curva. È importante per le applicazioni nel campo della probabilità e della statistica. Più precisamente dovremmo distinguere il caso di variabili casuali nel discreto e il caso di variabili casuali nel continuo: nel discreto si trova la sommatoria mentre nel continuo l’integrale. Per esempio, il calcolo del valore atteso (Expected) di una variabile nel discreto data la sua funzione di probabilità P(X=x)
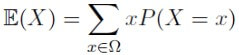
e nel caso continuo data la sua densità di probabilità p(x)
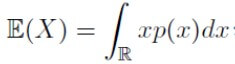
Quasi sempre non sarà necessario calcolare integrali, perché data una distribuzione di probabilità, gli stimatori sono già stati calcolati analiticamente, tuttavia è importante conoscere la teoria sottostante per capire meglio il contesto di applicabilità e il perimetro di validità di un modello.
Probabilità e statistica
Probabilità e statistica sono costruite su quanto detto precedentemente, in particolare la probabilità trova la sua definizione naturale nella teoria della misura e integrazione. Troviamo qui tutte le distribuzioni di probabilità e i loro contesti applicativi; inoltre è importante sottolineare che sebbene sia la più nominata, la “gaussiana” o “normale” non è l’unica e giusto per dare l’idea della quantità se ne possono citare alcune: Bernoulli, uniforme, binomiale, binomiale negativa, Poisson, Fischer, Beta, Gamma.
Le reti Bayesiane sono basate sul teorema di Bayes che nella forma più semplice e divulgativa è come segue:
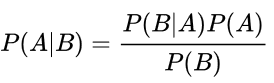
Questa formula fornisce la possibilità di calcolare la probabilità che si verifichi un evento A condizionato al fatto che si è verificato l’evento B, altrimenti detta probabilità di A condizionata a B. Le applicazioni sono molte e in particolare alle suddette reti Bayesiane; queste reti sono rappresentabili con un grafo “aciclico” “diretto”, ed ecco che anche qui ritorna la necessità di conoscere un pochino la teoria dei grafi.
Nel ML e nel DL, che sono metodi statistici di apprendimento, la statistica gioca un ruolo fondamentale in diversi ruoli: il campionamento da una popolazione di elementi, la stima degli errori, i test di ipotesi. Il campionamento non è una semplice scelta a caso bensì esiste il disegno di campionamento e diverse modalità con cui campionare una popolazione per avere un dataset in cui siano equamente rappresentate tutte le caratteristiche, che non sia sbilanciato, che le variabili scelte siano indipendenti e identicamente distribuite. La stima degli errori è alla base dei metodi predittivi e qui ricordiamo che la costruzione di un modello di apprendimento è sempre accompagnata dal controllo di grandezze quali la precisione e l’accuratezza sulle previsioni; l’errore, seppur piccolo è intrinseco nell’approccio statistico dei modelli di apprendimento.
Conclusioni
Si potrebbe andare avanti percorrendo tutti gli algoritmi noti e scoprendo un angolo di matematica che servirebbe conoscere; ci si può fermare qui con la convinzione di aver dato non tanto degli esempi rigorosi ma delle motivazioni concrete per imparare più matematica e per essere coscienti che questa ci aiuterà ad apprendere meglio gli algoritmi che costituiscono l’intelligenza artificiale e le discipline in essa contenute. Possiamo fermarci alla necessità di capire cosa stiamo usando e come lo applichiamo, ma possiamo anche andare oltre per arrivare a perfezionare il modello in base al contesto applicativo. Certamente non possiamo trascurare il fatto che anche affidandoci a sistemi automatici abbiamo bisogno di capire quello che succede; il risultato dell’applicazione degli algoritmi può essere diverso dal desiderato, pertanto la ricerca del miglior risultato richiede elaborazioni che non possono essere casuali ma devono essere determinate su una base teorica. Partendo da tre macro-aree della matematica ci siamo trovati ad aggiungerne altre, quindi il messaggio concreto è che non basta focalizzarsi su piccole aree della conoscenza e che per trarre beneficio dall’intelligenza artificiale in tutte le sue forme bisogna studiarla.



