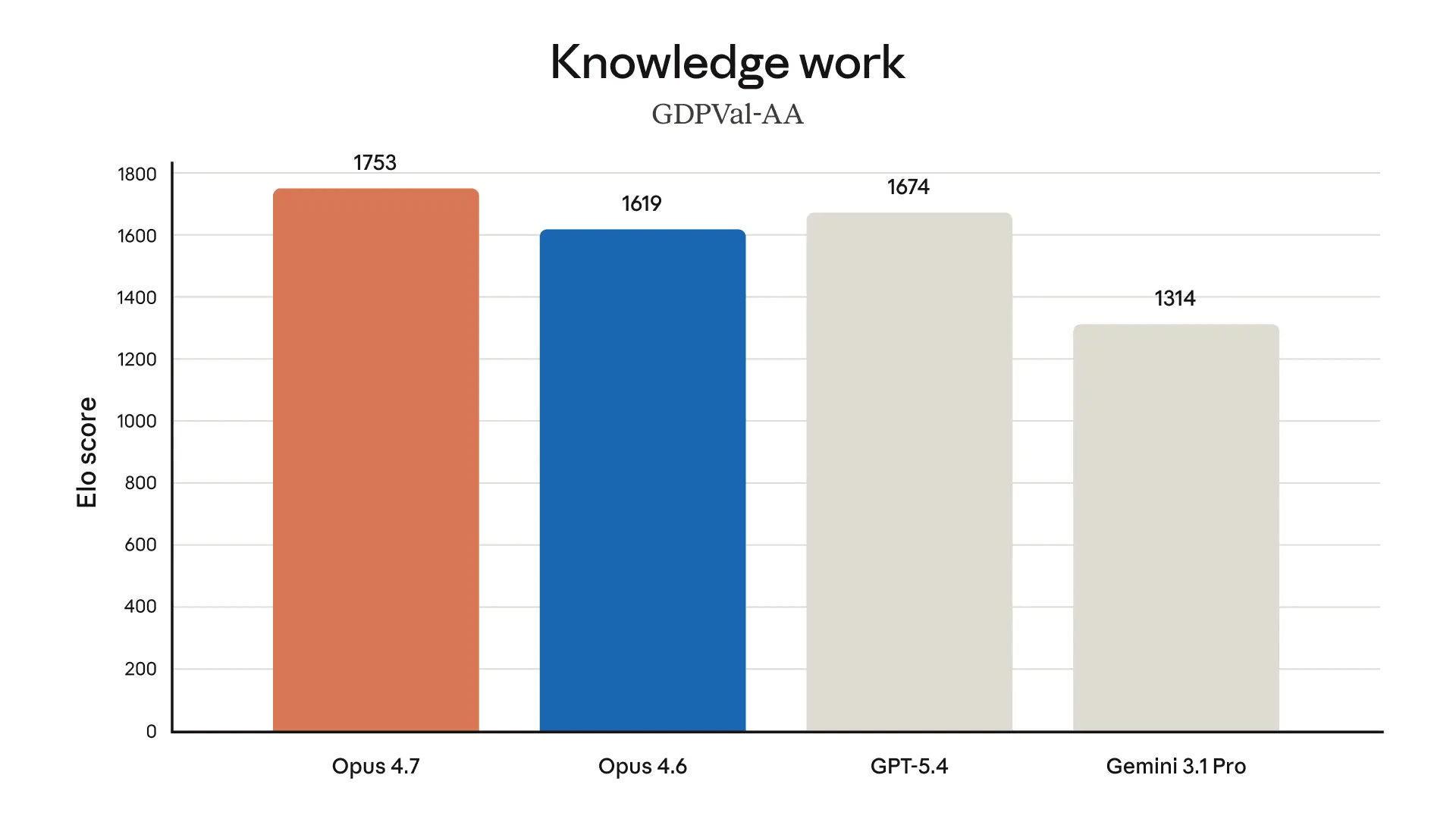
Claude Opus 4.7 è il modello più avanzato di Anthropic, ma non è il più potente che possiede: Mythos Preview, che resta chiuso in un circolo ristretto di una quarantina di partner enterprise, e nella comunicazione ufficiale fa capolino come benchmark di riferimento rispetto al quale Opus 4.7, testualmente, si ferma un passo prima.
analisi
Opus 4.7 e il dilemma di Anthropic, l’AI di frontiera che l’azienda ha deciso di non vendere
Claude Opus 4.7 segna un upgrade incrementale sul coding agentico e la vision, ma il suo rilascio fa notizia soprattutto per ciò che comunica: esiste un modello più potente, Mythos Preview, che Anthropic ha deciso di rilasciare a un distretto gruppo di aziende. Analisi critica del lancio, della comparazione con GPT-5.4 e Gemini 3.1 Pro, e di cosa accelera davvero questo cambiamento
Pubblicato il 21 apr 2026
Fabio Lalli
Consulente in trasformazione digitale – AI & product strategy
@RIPRODUZIONE RISERVATA


Fabio Lalli
Consulente in trasformazione digitale – AI & product strategy
Fabio Lalli è consulente in innovazione e AI, con oltre venticinque anni di esperienza nello sviluppo di prodotti digitali e nella trasformazione delle organizzazioni.
Ha fondato diverse realtà nel corso della sua carriera e completato un exit imprenditoriale nel settore digitale. Oggi guida Iconico, società specializzata nel supporto a startup e imprese nei processi di crescita, validazione di prodotto e go-to-market, e ZeroFive.ai, studio di consulenza strategica focalizzato sull’adozione dell’AI e sulla progettazione di architetture e modelli operativi aumentati dall’intelligenza artificiale.
Collabora con aziende di diversi settori su temi di AI transformation, modelli organizzativi, framework decisionali e misurazione dell’impatto economico delle tecnologie emergenti.