
Gran parte del potere dell’intelligenza artificiale deriva dall’uso dell’apprendimento profondo basato sui dati (data-driven deep learning) che consente di formare modelli sempre più accurati grazie a quantità crescenti di dati. Tuttavia, la forza di queste tecniche può costituire al tempo stesso una debolezza. I sistemi di intelligenza artificiale apprendono ciò che viene insegnato loro e se, come supporto, non vengono usati set di dati solidi e diversificati, fattori come accuratezza ed equità potrebbero essere a rischio.
Questa sfida di “correttezza” si manifesta profondamente nella realizzazione di sistemi di riconoscimento facciale. Il cuore del problema non deriva dalla tecnologia di intelligenza artificiale di per sé, bensì dal modo in cui i sistemi di riconoscimento facciale vengono addestrati. I dati di training devono essere diversi e offrire un’ampia copertura.
Per questo motivo, IBM, insieme agli sviluppatori di IA e alla comunità di ricerca, sta rilasciando un nuovo ampio e diversificato set di dati chiamato Diversity in Faces (DiF) per promuovere lo studio della correttezza e dell’accuratezza nella tecnologia di riconoscimento facciale. Studiare la diversità nei volti è complesso e questo set di dati fornisce un punto di partenza per la comunità di ricerca globale per promuovere la conoscenza collettiva.
Indice degli argomenti:
La diversità dei volti umani non dipende solo da età, sesso e colore della pelle
Affinché i sistemi di riconoscimento facciale si comportino come desiderato e i risultati siano sempre più accurati, i dati devono essere sufficientemente grandi e abbastanza diversi da consentire alla tecnologia di apprendere tutti i modi in cui i volti si differenziano. Questo permette di riconoscere con precisione la distribuzione delle caratteristiche dei volti in una varietà di situazioni.
Ma come si misura la diversità dei volti umani?
Età, sesso e colore della pelle sono i fattori con cui abbiamo una certa familiarità. Non a caso, gran parte delle tecnologie di riconoscimento facciale si focalizzano proprio sull’analisi della diversità di questi attributi. Tuttavia, come hanno dimostrato studi precedenti, questi attributi sono solo una parte del puzzle e non del tutto adeguati per caratterizzare la piena diversità dei volti umani. Sono rilevanti anche dimensioni come la simmetria del volto, il contrasto facciale, la posa del viso, la lunghezza o la larghezza degli attributi del viso (occhi, naso, fronte, ecc.).
Il nuovo set di dati fornito da IBM per la creazione di sistemi IA più equi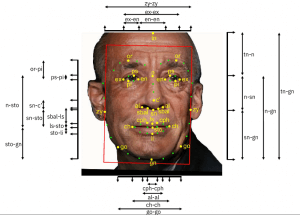
Oggi, IBM Research sta rilasciando un nuovo ampio e diversificato set di dati chiamato Diversity in Faces (DiF). L’obiettivo è migliorare correttezza e accuratezza della tecnologia di riconoscimento facciale. DiF fornisce un data set di annotazioni di 1 milione di immagini facciali umane.
Usando immagini pubblicamente disponibili ricavate dal set di dati Creative Commons YFCC-100M, hanno annotato i volti usando 10 schemi di codifica ben stabiliti e indipendenti reperiti dalla letteratura scientifica [1-10].
Gli schemi di codifica includono principalmente misure oggettive, come caratteristiche craniofacciali (ad es. lunghezza della testa, lunghezza del naso, altezza della fronte), oltre ad annotazioni più soggettive, come le previsioni dell’età e del sesso.
I risultati tangibili
L’analisi ha dimostrato che il set di dati DiF fornisce una distribuzione più equilibrata e una copertura più ampia delle immagini facciali rispetto ai set di dati precedenti. Inoltre, le intuizioni ottenute dall’analisi statistica dei 10 schemi di codifica iniziali sull’insieme di dati DiF hanno favorito la comprensione di ciò che è importante per la caratterizzazione dei volti umani e hanno permesso di lanciare ricerche importanti su come migliorare la tecnologia di riconoscimento facciale.
Per richiedere l’accesso al DiF data set visitate questo sito.


