
Lo sviluppo dei sistemi di intelligenza artificiale sta lentamente mutando il suo percorso. Le performance e l’accuracy non sono più l’unico obiettivo dei ricercatori; molte tecnologie sono ormai mature, e i sistemi di classificazione e analisi dati riescono a surclassare le performance umane nello svolgimento di alcuni task specifici. Per l’applicazione su larga scala di questi sistemi, l’affidabilità da sola non basta: serve un focus sul funzionamento di una rete neurale, per poter spiegare e motivare le decisioni prese dall’AI.
Indice degli argomenti:
Il problema delle black box
La maggior parte dei modelli di reti neurali sono stati progettati come delle “black box” di cui conosciamo soltanto l’input e l’output. Gli stessi sviluppatori che progettano l’architettura della rete spesso non possono spiegare con esattezza “come” e “perché” il sistema riesca a svolgere il proprio compito con tanta accuratezza. Questo rappresenta un grosso ostacolo quando queste AI devono uscire dai laboratori per essere applicate in scenari reali, ci sono molte implicazioni etiche e legali legate all’impatto sull’attività umana delle decisioni guidate da sistemi di apprendimento automatico. In questo caso non basta garantire l’accuratezza del risultato, ma occorre spiegare e soprattutto dimostrare come questo risultato è stato ottenuto, valutando l’impatto dei singoli componenti della rete neurale (i neuroni digitali) sull’output.
Immaginiamo uno scenario nel quale un’AI per la classificazione delle immagini venga utilizzata in un contesto medico. È stato dimostrato che le reti neurali riescono a classificare alcune immagini diagnostiche con particolare accuratezza, riuscendo a rilevare piccole anomalie correlate con particolari patologie. Se il sistema di analisi in questione è una black box di cui si ignora il funzionamento delle componenti interne, l’utente non avrà modo di capire quali caratteristiche dell’immagine hanno portato alla diagnosi automatica. La diagnosi, quindi, può essere utile solo parzialmente, perché il medico non avrà nessuna possibilità di comprendere e valutare le caratteristiche che hanno portato alla decisione della rete neurale. Se invece l’intelligenza artificiale fosse anche in grado di descrivere accuratamente le caratteristiche dell’immagine che hanno permesso di classificare una potenziale patologia, quest’informazione avrebbe un’utilità molto maggiore.
Una soluzione per demistificare il comportamento di una rete neurale
Un team di ricerca proveniente dal Computer Science and Artificial Intelligence Laboratory dell’MIT ha proposto una soluzione che aiuta a demistificare il comportamento di una rete neurale, identificando e spiegando le feature riconosciute da ogni singolo neurone. Il paper disponibile a questo link, porta la firma di Evan Hernandez, coadiuvato da Sarah Schwettmann, David Bau, Teona Bagashvili e dal professor Antonio Torralba, tutti membri del CSAIL. I risultati della ricerca saranno presentati tra qualche mese all’ International Conference on Learning Representations 2022.
Il progetto, denominato MILAN (mutual-information-guided linguistic annotation of neurons), ha l’obiettivo di fornire una descrizione testuale che spieghi quale siano le caratteristiche dei dati ricevuti in input, che vengono analizzate da ogni singolo elemento della rete neurale. Ma per capire meglio il suo funzionamento, addentriamoci brevemente nel mondo delle reti neurali.
Cos’è una rete neurale
Essenzialmente una rete neurale è una combinazione di elementi (nodi o neuroni) raggruppati in livelli (layers). Ogni nodo ha il compito di valutare una o più equazioni matematiche passando il risultato ai nodi del livello successivo. La rete riceve una rappresentazione vettoriale dei dati da analizzare attraverso l’input layer, restituendo una rappresentazione vettoriale del risultato ottenuto grazie all’output layer. Tra questi due livelli principali ci sono una serie di altri layers che contengono i neuroni che si occupano della valutazione vera e propria delle equazioni. Ciascuno di questi nodi contribuisce in qualche misura al risultato, ma se consideriamo la rete neurale come una black box non è possibile capire come e in che misura ogni nodo concorra all’output.
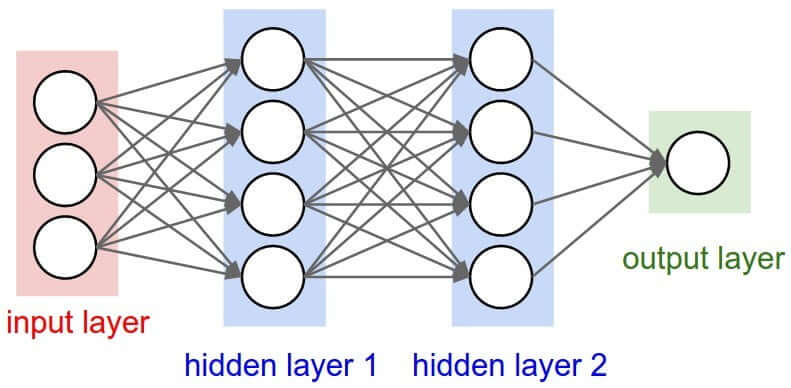
Il progetto MILAN
Il progetto di Hernandez et al. rappresenta un notevole passo in avanti nella risoluzione di questo problema. Nel caso di una rete per la computer vision, che classifica immagini riconoscendo oggetti, persone e animali, MILAN è in grado di descrivere in formato testo, il contributo di ogni neurone nell’interpretazione di gruppi di pixels. Ovvero, quanto l’AI riconosce un volto umano in una foto, con questo strumento si è in grado di capire quale parte della rete riconosce un “occhio” piuttosto che un “naso” o un’altra caratteristica. Ogni neurone avrà così un’etichetta testuale che descrive la feature specifica che è addestrato a riconoscere. In altre parole, parafrasando uno dei ricercatori coinvolti nel progetto, MILAN risponde alla domanda: “C’è qualcosa che il mio modello sa, di cui non mi sarei aspettato che sapesse?”.
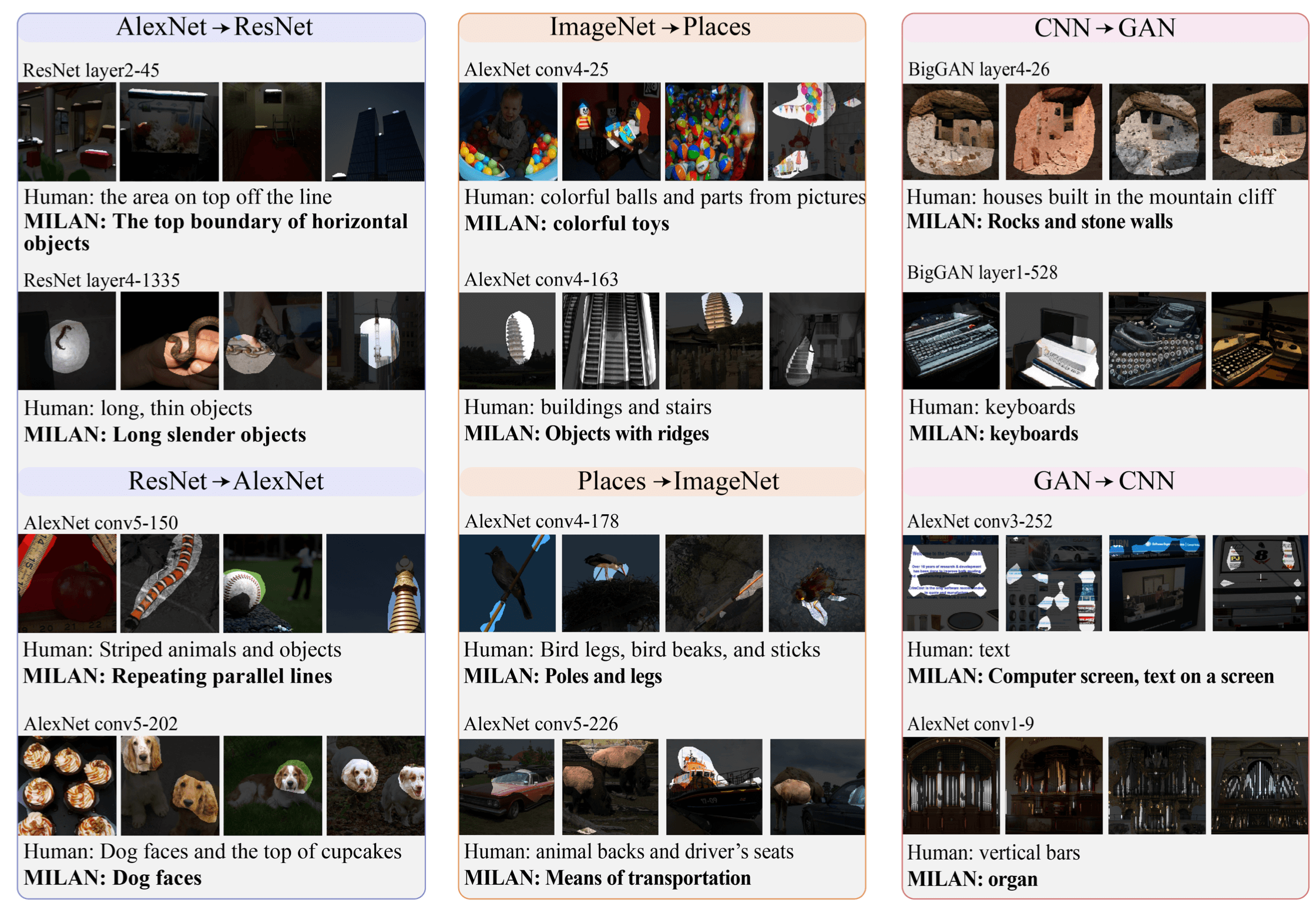
La strategia elaborata dai ricercatori del MIT non richiede un intervento umano per stilare liste di features da usare nelle descrizioni. Questo è un notevole vantaggio pratico perché le reti neurali possono contenere centinaia di migliaia di singoli neuroni con feature altrimenti impossibili da individuare per un operatore umano. Il risultato ottenuto in laboratorio, non solo aiuta a rendere “spiegabili” i processi decisionali legati a una rete neurale, ma può anche aiutare gli sviluppatori anche in fase di design, per migliorare l’architettura standard adattandola al problema specifico che deve risolvere. Grazie alle descrizioni automatiche, è possibile individuare i neuroni che sono meno importanti per la rete così da ridurne la complessità senza intaccare in alcun modo l’accuracy del risultato.
Conclusioni
Il paper evidenzia comunque anche i limiti attuali del modello, che registra ottime performance in alcuni contesti ma risulta ancora poco preciso in altri. MILAN in alcuni contesti fornisce solo descrizioni vaghe o addirittura errate, che non sono ancora sufficienti a garantire la descrizione affidabile di una rete neurale. I ricercatori sono a lavoro per migliorare l’affidabilità del sistema nel generare descrizioni valide indipendentemente dal contesto, e per ampliare la schiera di architetture compatibili con questa tecnologia. Un passo in avanti verso l’AI explainability, con l’obiettivo di migliorare l’integrazione tra i sistemi di apprendimento automatico e le attività umane che lo richiedono.



