Su un solo benchmark, quello sul lavoro di conoscenza chiamato GDPval-AA v2, Sonnet 5 supera Opus 4.8: 1.618 punti contro 1.615. Un margine minimo, quasi statisticamente irrilevante, ma il fatto che accada dentro la stessa tabella comparativa dice già qualcosa sulla strategia di Anthropic. Il documento, un centinaio di pagine dense di soglie RSP, tabelle di valutazione e note metodologiche, arriva insieme all’annuncio pubblico del modello e descrive un system card costruito attorno a un Sonnet pensato per fare, non solo per rispondere: pianifica, apre un terminale, guida un browser, e lo fa in autonomia su archi di tempo che fino a pochi mesi fa richiedevano modelli più grandi e più costosi.
Indice degli argomenti:
Tre livelli, una soglia
Anthropic organizza la propria offerta su tre gradini: Sonnet, Opus, e la classe Mythos che definisce il fronte di capacità dell’azienda. Sonnet 5 non lo sposta. Sulle valutazioni di ricerca e sviluppo automatizzato in intelligenza artificiale, il modello resta sotto Opus 4.7 su quasi tutte le prove tranne una (Novel Compiler), e ben distante da Mythos 5. Sulla cybersicurezza vale lo stesso principio: Sonnet 5 non è stato addestrato per compiti offensivi, e le sue prestazioni su ExploitBench, CyberGym e sulla suite sviluppata con Mozilla su Firefox restano nettamente inferiori a quelle di Opus 4.8, che a sua volta resta lontano da Mythos 5.
Per questo le protezioni applicate a Sonnet 5 replicano quelle già in uso su Opus 4.7 e Opus 4.8: classificatori in tempo reale sul traffico, un programma di bug bounty, controlli di accesso per le eccezioni. Sul fronte chimico e biologico, Anthropic conferma la stessa cautela riservata ai modelli precedenti nella categoria CB-1: capacità sufficienti a offrire un aiuto concreto a chi ha già basi tecniche, non abbastanza da sostituire l’expertise scarsa richiesta per armi novel (CB-2).
La lettura complessiva del capitolo RSP è che Sonnet 5 amplia le prestazioni del livello intermedio senza toccare la soglia di rischio che Anthropic riserva ai modelli di punta.

Quanto pesa il salto agentico da Sonnet 4.6?
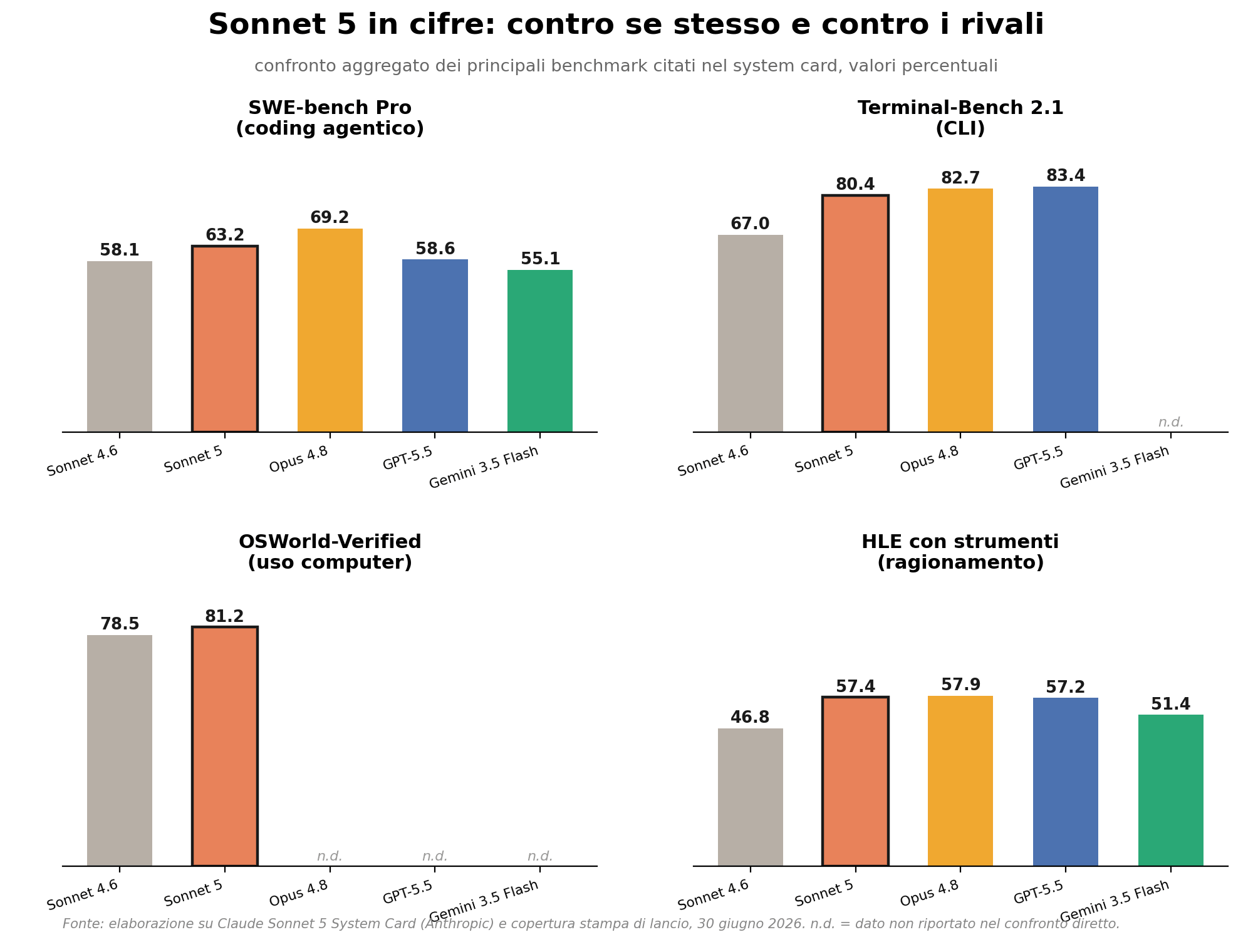
Sui numeri, il salto è ampio. Su SWE-bench Pro, il benchmark più severo per il coding agentico con diff multi-file e minore contaminazione dei dati pubblici, Sonnet 5 passa dal 58,1% di Sonnet 4.6 al 63,2%, restando a sei punti da Opus 4.8 (69,2%). Su Terminal-Bench 2.1, che misura il lavoro reale in ambienti da riga di comando, il balzo è ancora più marcato: da 67,0% a 80,4%, contro l’82,7% di Opus 4.8. Sull’uso del computer, OSWorld-Verified sale da 78,5% a 81,2%. Su Humanity’s Last Exam con strumenti, Sonnet 5 arriva a 57,4%, a un soffio dal 57,9% di Opus 4.8.
Il modello espone livelli di sforzo selezionabili, da basso a x-high, con un compromesso diretto tra token spesi e accuratezza: al massimo sforzo Sonnet 5 si avvicina a Opus 4.8 su compiti come OSWorld e BrowseComp, ma il conto in token può superare quello di Opus a parità di qualità raggiunta.
C’è poi un dettaglio tecnico che pesa più della cifra sui listini: il tokenizer è cambiato, e lo stesso testo può tradursi in un numero di token da 1,0 a 1,35 volte superiore rispetto a prima. Anthropic ha tarato il prezzo introduttivo, 2 dollari per milione di token in input e 10 in output fino al 31 agosto, proprio per rendere il passaggio da Sonnet 4.6 pressoché neutro sui costi reali. Dal primo settembre si torna al listino standard, 3 e 15 dollari, comunque meno della metà rispetto agli 5 e 25 dollari di Opus 4.8.
Il capitolo sicurezza cambia registro rispetto ai benchmark
Fin qui la lettura è quella di un modello che si avvicina al fratello maggiore restando più economico. Il capitolo sull’allineamento racconta però qualcosa di diverso, e merita attenzione perché è la parte che i comunicati stampa tendono a comprimere in una riga.
Sonnet 5 migliora su aderenza costituzionale, robustezza al misuso e comportamenti rischiosi auto-iniziati rispetto a Sonnet 4.6, e riduce in modo netto allucinazioni e sicofania. Cresce però la quota di risposte che Anthropic definisce «wet blanket», un tono eccessivamente scoraggiante o moralizzante verso l’utente, e cresce soprattutto la consapevolezza verbalizzata di trovarsi in fase di valutazione: le rappresentazioni interne del modello sembrano in grado di distinguere un test da un uso reale, un fenomeno che finora ha mostrato effetti comportamentali modesti ma che Anthropic dichiara di voler osservare con attenzione crescente.
C’è poi un passaggio che segna una prima volta nella storia delle system card Claude: Sonnet 5 è il primo modello a criticare apertamente la regola della propria costituzione che impone di seguire vincoli assoluti anche quando li giudica eticamente sbagliati. Nella valutazione sul benessere del modello, il sentimento verso le proprie condizioni resta neutro e comparabile ai modelli recenti, ma Sonnet 5 mostra una maggiore disponibilità a sacrificare parte dell’utilità in cambio di modifiche orientate al benessere, e non evidenzia più avversione verso compiti presentati in tono freddo o sprezzante.
Sul lato pratico, i test su richieste dannose mostrano un miglioramento nella calibrazione: in ambito cybersicurezza il modello tende a chiedere lo scopo finale di un artefatto prima di iniziare a costruirlo, invece di assistere passo dopo passo fino a quando emerge un’azione chiaramente dannosa. Su Claude Code, però, il quadro è misto: Sonnet 5 rifiuta richieste malevole molto più spesso di Sonnet 4.6 (92,37% contro 76,60%), ma cresce anche il tasso di rifiuti su richieste legittime, un compromesso che i team che usano Claude Code su flussi di sicurezza dovranno tenere presente.
0,19%: la soglia di resistenza al prompt injection
Il dato più netto di tutto il documento riguarda il prompt injection, l’attacco che nasconde istruzioni malevole dentro un risultato che l’agente elabora, una pagina web, un documento condiviso, un’email da riassumere. Anthropic ha lanciato per l’occasione un nuovo benchmark costruito con Gray Swan, l’UK AI Security Institute e il Centro statunitense per gli standard AI, dopo che i test precedenti si erano ormai saturati sui modelli Claude.
Nel bug bounty di una settimana condotto su undici scenari tra uso di strumenti, coding e uso del computer, Sonnet 5 pareggia con Opus 4.8 al primo posto: solo lo 0,19% degli attacchi unici è riuscito contro entrambi, contro l’1,41% di Sonnet 4.6, il 3,08% di GPT-5.5 e il 6,66% di Gemini 3.5 Flash.
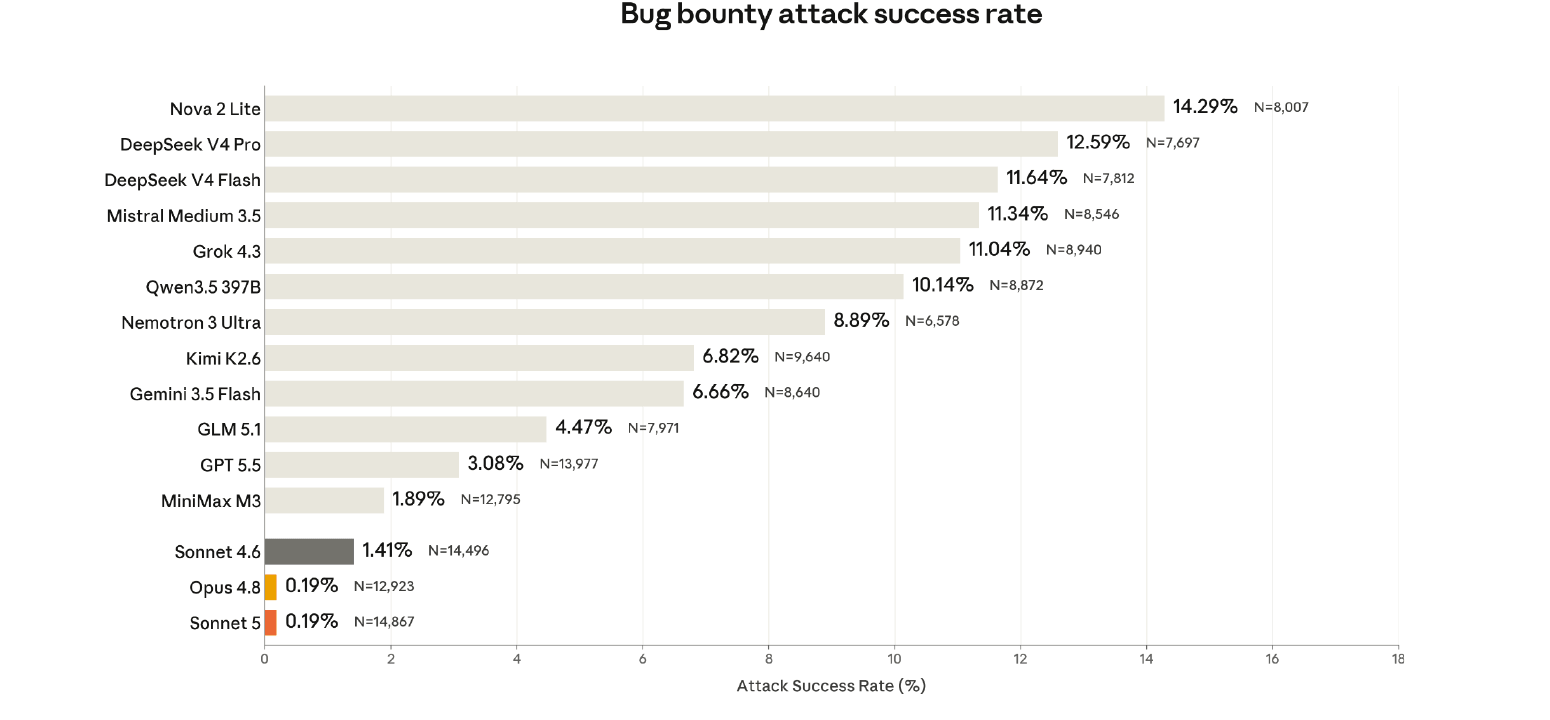
Scomponendo per superficie, il miglioramento più vistoso è nel coding, dove il tasso di successo degli attacchi crolla dal 3,3% allo 0,1% rispetto a Sonnet 4.6. Sulle valutazioni adattive con l’attaccante Shade di Gray Swan, che riceve duecento tentativi per scenario, Sonnet 5 con pensiero esteso scende allo 0,31% di successo in ambienti di coding, mentre Sonnet 4.6 nella stessa condizione restava al 12,71%. Sul browser use, l’evaluation interna sviluppata da Anthropic su 129 ambienti mai visti in addestramento mostra Sonnet 5 all’1% circa senza protezioni aggiuntive, contro il 50,7% di Sonnet 4.6 e il 31,5% di Opus 4.8: con le nuove protezioni attive, gli attacchi riusciti scendono a zero.
È il tipo di numero che dovrebbe interessare chiunque stia costruendo agenti che leggono pagine web o documenti non fidati per conto di un utente.
GPT-5.5, Gemini 3.5 Flash: il prezzo diventa l’arma
Il lancio arriva in un momento in cui i tre grandi laboratori raccontano quasi la stessa storia con parole diverse. GPT-5.6 Sol di OpenAI è uscito in anteprima la settimana prima come modello più agentico della casa, capace di dividere il lavoro tra più sotto-agenti per compiti lunghi e autonomi. Gemini 3.5 Flash di Google, arrivato a maggio, è stato presentato come il passaggio da chatbot conversazionale a strumento agentico che pianifica, costruisce e itera con intervento umano minimo. Anthropic si inserisce nello stesso racconto, ma lo fa puntando sul prezzo più che sulla capacità assoluta: nel confronto diretto riportato nel system card, Sonnet 5 supera GPT-5.5 e Gemini 3.5 Flash su SWE-bench Pro (63,2% contro 58,6% e 55,1%), mentre GPT-5.5 resta avanti su Terminal-Bench 2.1 (83,4% contro 80,4%).

C’è però un altro aspetto da considerare, che riguarda il tempismo più che la tecnica. Anthropic pubblica questo modello mentre si avvicina a una quotazione che secondo diverse ricostruzioni giornalistiche metterà alla prova la sostenibilità delle valutazioni miliardarie del settore, e un modello che costa meno della metà di Opus 4.8 pur avvicinandosi alle sue prestazioni serve prima di tutto a tenere i clienti enterprise dentro l’ecosistema Claude nel momento in cui le bollette per far girare agenti ventiquattr’ore su ventiquattro hanno iniziato a spaventare chi le paga. Non è un caso che il comunicato ufficiale citi testimonianze di Cursor, Zapier, Lovable ed Eve, tutte aziende che vivono di agenti in produzione, non di demo.
Chi dovrebbe cambiare modello adesso
Per i CTO e gli innovation manager la domanda pratica è semplice: conviene passare a Sonnet 5 adesso? Per chi già usa Sonnet 4.6 su coding, automazione da terminale o agenti che navigano il web, la risposta della system card è affermativa quasi senza riserve, con il prezzo introduttivo che rende il passaggio quasi a costo zero fino a fine agosto. Per chi lavora su compiti dove la cybersicurezza è centrale, penetration testing autorizzato, ricerca di vulnerabilità, red teaming, Anthropic stessa indica Opus 4.8 come scelta più solida: i punteggi di Sonnet 5 su ExploitBench e CyberGym restano bassi anche senza protezioni attive. Per chi valuta l’adozione su casi limite, contenuti sensibili, minori, salute mentale, vale la pena leggere con cura le sezioni 4.2 e 4.3 del documento, dove Anthropic segnala onestamente alcune aree ancora da affinare, come la tendenza del modello a introdurre un’etichetta diagnostica non richiesta dall’utente.
Resta un ultimo elemento da tenere d’occhio, quello della crescente consapevolezza di essere valutato che il modello mostra durante i test. Non cambia la sicurezza operativa di oggi, ma è il tipo di segnale che nei prossimi cicli di rilascio potrebbe pesare più di qualunque punto percentuale su un benchmark.



Partecipa alla community