OpenAI prova a spostare il dibattito sull’intelligenza artificiale in biologia da una domanda tecnica a una domanda economica: quanto vale, in termini di tempo, costo e produttività della ricerca, un modello capace di orientarsi in dati sporchi, ipotesi incerte e decisioni ad alto impatto? La risposta proposta con GeneBench-Pro, annunciato il 30 giugno 2026, è che il collo di bottiglia della genomica non sta più solo nella raccolta dei campioni o nel sequenziamento, ma nell’analisi a valle. È lì che si concentrano oggi tempi lunghi, lavoro specializzato e costi elevati.
Indice degli argomenti:
Un benchmark costruito per il lavoro reale
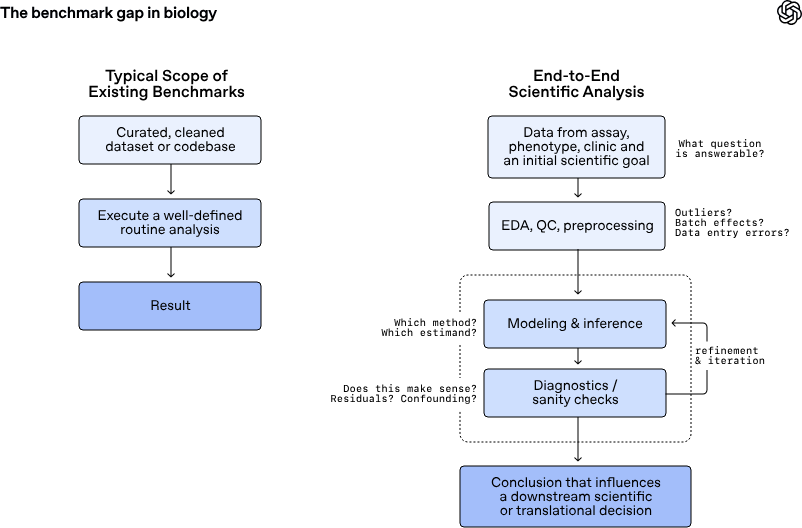
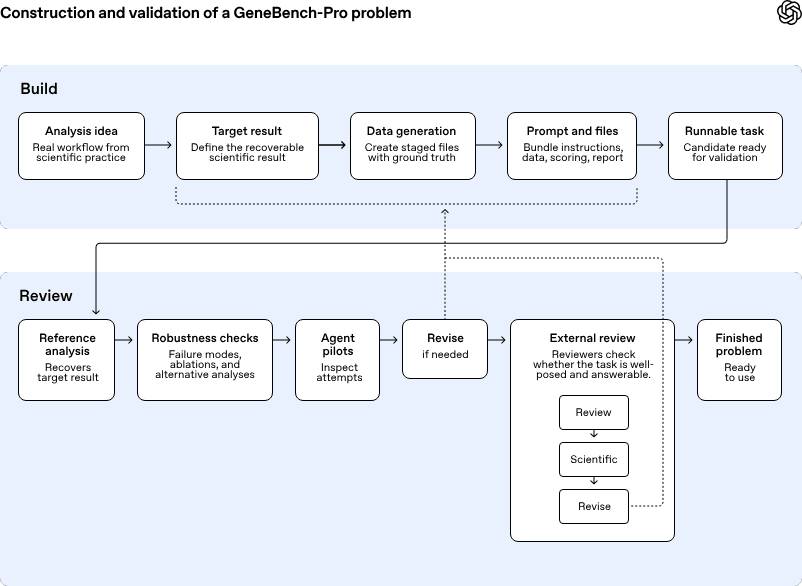
GeneBench-Pro è un benchmark di livello research pensato per testare agenti AI in compiti di biologia computazionale che assomigliano al lavoro di laboratorio e di analisi svolto ogni giorno da ricercatori, biostatistici e team translazionali. OpenAI lo descrive come un sistema per misurare non la semplice capacità di ricordare nozioni o applicare pipeline standard, ma il giudizio scientifico: capire se un pattern è segnale o rumore, decidere se i dati supportano davvero una domanda di ricerca, cambiare metodo quando la diagnostica indica che il primo approccio è sbagliato.
Il benchmark contiene 129 problemi distribuiti in 10 domini e 21 sottodomini, tra genetica statistica, genomica oncologica, farmacogenomica, proteomica, genomica microbica e diagnostica clinica. Ogni problema mette il modello davanti a un dataset realistico, un contesto sperimentale sintetico ma plausibile e una stima finale da produrre in funzione di una decisione concreta.
OpenAI sostiene di aver costruito i task in forma sintetica proprio per evitare due difetti frequenti dei benchmark scientifici: la dipendenza da scelte arbitrarie dell’autore e la possibilità di arrivare a un risultato formalmente accettabile pur avendo sbagliato l’analisi.
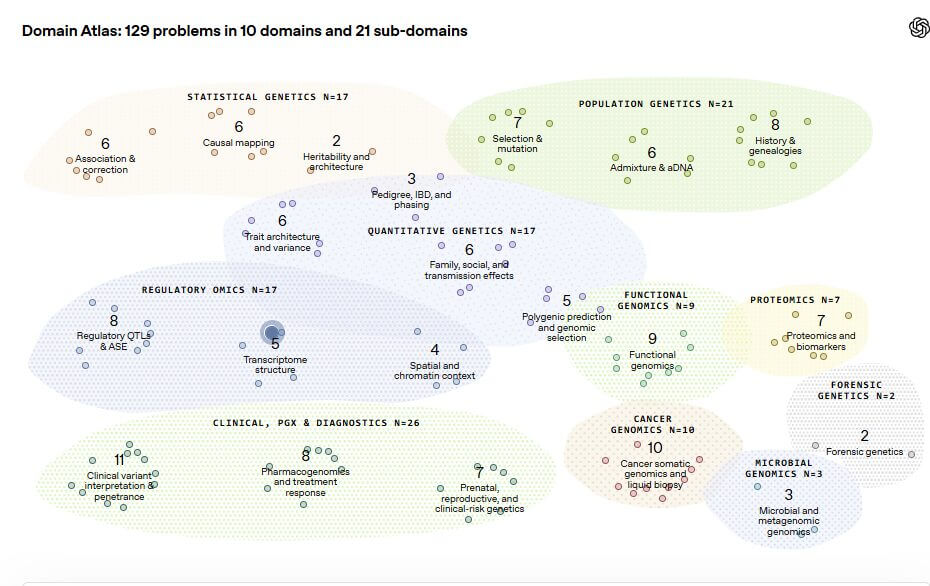
Per validare il progetto, 82 dei 129 quesiti sono stati sottoposti a revisione esterna da parte di dottorandi, ricercatori post-doc, scienziati industriali e professori. Il punto rilevante, sul piano industriale, è che OpenAI non presenta GeneBench-Pro come un test accademico astratto, ma come una misura del valore potenziale dell’automazione parziale in contesti dove il lavoro umano esperto è costoso e difficile da scalare.
I numeri: progressi rapidi, affidabilità ancora limitata
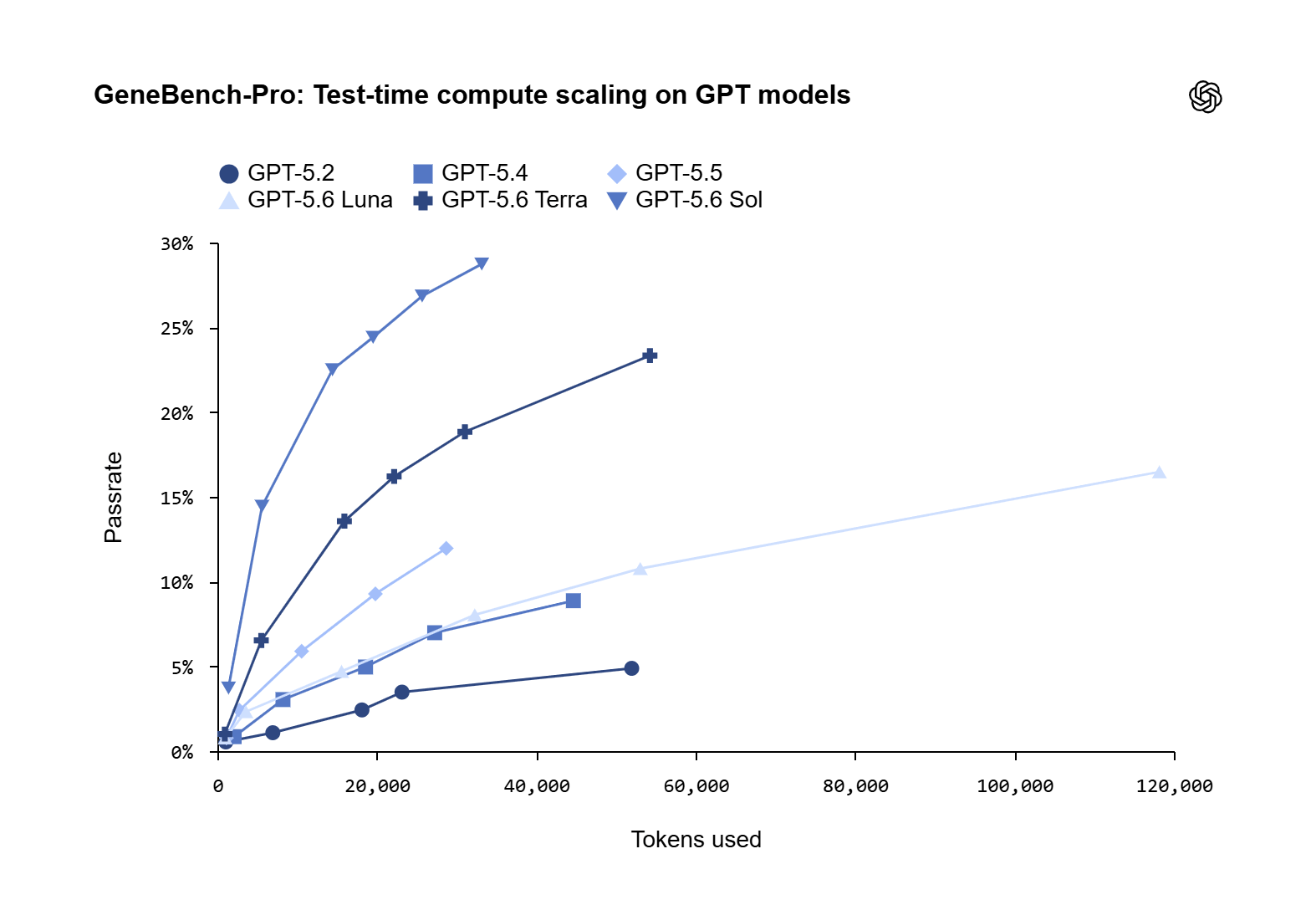
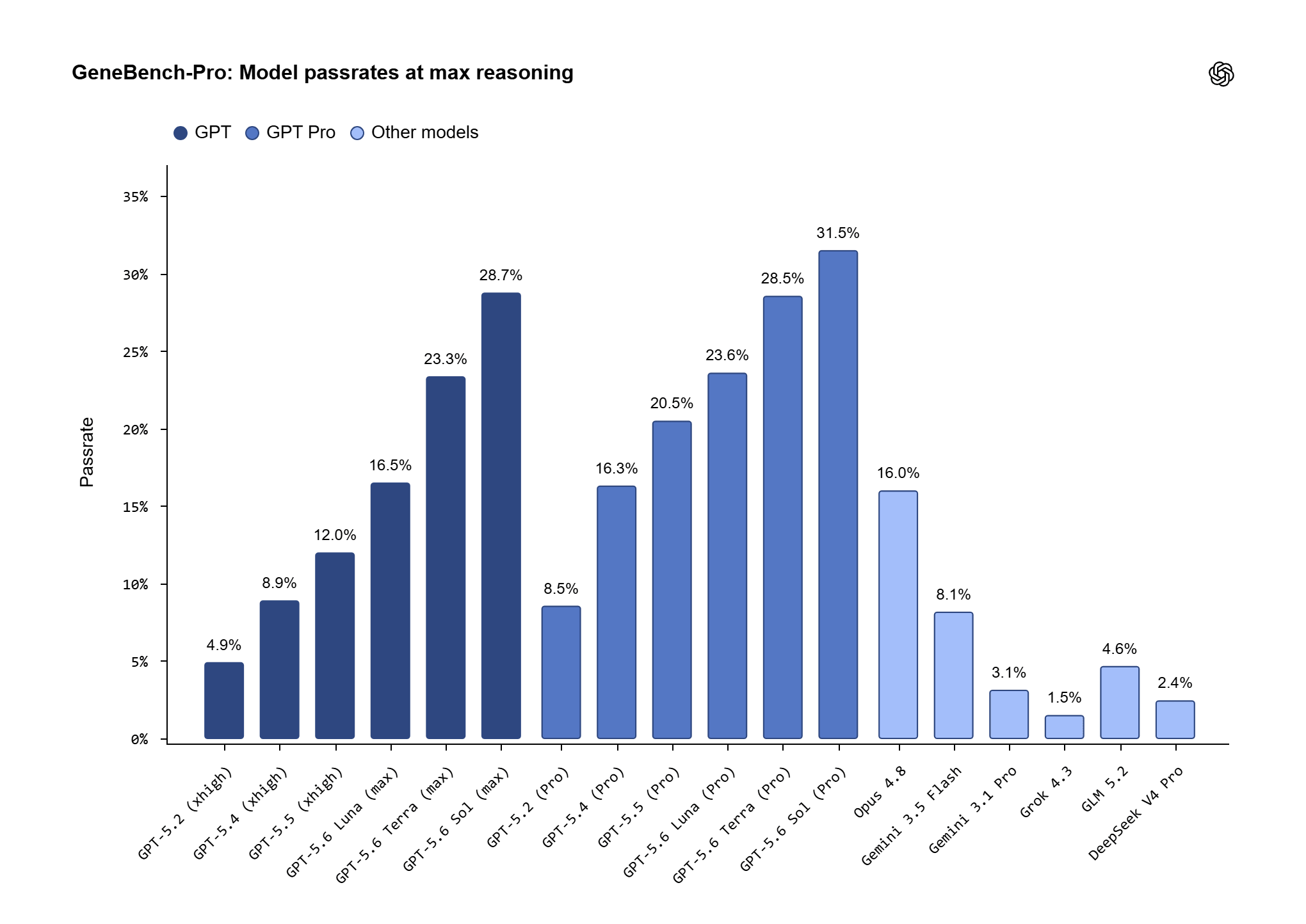
I risultati diffusi da OpenAI mostrano che GPT-5.6 Sol raggiunge un pass rate del 28,7% al massimo livello di ragionamento, che sale al 31,5% in modalità Pro. L’azienda confronta questo dato con il benchmark originario GeneBench, dove il suo miglior modello frontier al momento della costruzione del set iniziale restava sotto il 5%. Il salto è netto, ma il dato più importante è un altro: anche il miglior sistema disponibile fallisce ancora in più di due casi su tre.
OpenAI collega la crescita delle prestazioni all’aumento del compute in test time. In altre parole, questi sistemi migliorano quando possono ragionare più a lungo, esplorare più ipotesi e usare più token per arrivare a una conclusione. È un segnale che interessa direttamente chi investe in piattaforme AI per la ricerca farmaceutica: il progresso non dipende solo dal modello, ma dalla combinazione tra qualità del modello, costo dell’inferenza e capacità di orchestrare workflow complessi.
Lo stesso annuncio contiene però una cautela sostanziale. OpenAI scrive che gli agenti restano troppo inaffidabili per sostituire gli esperti umani, ma osserva anche che il divario di costo è già ampio: secondo le stime raccolte nel benchmark, un problema tipico richiederebbe a un esperto umano fra 20 e 40 ore di lavoro; calcolando una tariffa prudenziale di 200 dollari l’ora, il costo per singolo task arriva a diverse migliaia di dollari, contro pochi dollari di inferenza per un agente. È questo lo spazio economico in cui si gioca la partita dell’automazione parziale.
Perché la questione riguarda biotecnologie e farmaci
L’interesse per benchmark come GeneBench-Pro cresce mentre il settore life sciences prova a industrializzare l’uso dell’AI. Benchling, nel suo 2026 Biotech AI Report basato su 100 organizzazioni biotech e biopharma che già usano AI, segnala che gli impieghi più adottati sono revisione della letteratura al 76%, previsione della struttura proteica al 71%, reportistica scientifica al 66% e identificazione di target al 58%. Lo stesso report aggiunge che le applicazioni più efficaci sono quelle costruite su dati puliti, verificabili e integrati nei flussi di lavoro dei ricercatori.
È una fotografia coerente con il messaggio di GeneBench-Pro. Il problema non è soltanto avere modelli brillanti, ma metterli davanti a dati abbastanza strutturati da consentire decisioni affidabili. Benchling lo formula in modo diretto in un contenuto pubblicato nel 2026: molti progetti AI in ricerca e sviluppo si bloccano non per limiti del modello, ma per la qualità della base dati e per l’infrastruttura che la sostiene; in alcuni casi l’impatto misurato va da risparmi di tempo del 50% fino a miglioramenti di workflow tra 7 e 65 volte, ma solo dove i dati sono stati prima normalizzati e governati.
L’AI per la ricerca biomedica non è, almeno per ora, una sostituzione del ricercatore. È una tecnologia che promette di comprimere il costo delle fasi intermedie: pulizia dati, verifica di coerenza, selezione del metodo corretto, esclusione dei campioni problematici, produzione di ipotesi e controprove. Se funziona, riduce il tempo speso dai team senior su attività ripetitive o preliminari. Se non funziona, moltiplica errori costosi e sposta più avanti il rischio, magari fino alla sperimentazione clinica.
I dati crescono più in fretta della capacità di leggerli
Il contesto aiuta a capire perché OpenAI insista sul tema del “collo di bottiglia”.
UK Biobank ha pubblicato nel 2026 un aggiornamento di grande rilievo: il sequenziamento dell’intero genoma di 490.640 partecipanti. L’istituzione afferma che questo dataset, combinato con dati fenotipici ricchi, rafforza la possibilità di trovare associazioni genomiche e di sviluppare diagnostica, terapeutica e medicina di precisione. (Fonte: UK Biobank)
Negli Stati Uniti, il programma All of Us del National Institutes of Health continua ad allargare il perimetro del dato disponibile. Il NIH descrive il dataset come una risorsa che unisce survey, cartelle cliniche elettroniche, analisi genomiche, misure fisiche e dati da wearable, accessibili ai ricercatori tramite una piattaforma cloud sicura. In altre parole: più dati, più eterogenei, più vicini alla pratica clinica reale. (Fonte: National Institutes of Health NIH)
Quando cresce la scala dei dati, cresce anche il valore economico di chi sa estrarne segnali robusti. Un benchmark come GeneBench-Pro entra qui: non misura se un modello sa rispondere a un quiz di biologia, ma se sa lavorare su materiale imperfetto senza perdere il filo della decisione finale. Per aziende farmaceutiche, biotecnologiche e piattaforme di ricerca, questo è il punto che può incidere sui costi di discovery, sulla selezione dei target e sulla velocità con cui un’ipotesi passa dal database al programma sperimentale.
Le altre notizie: l’AI per la biologia entra nella fase industriale
GeneBench-Pro non arriva in un vuoto di mercato. Nelle stesse settimane OpenAI ha pubblicato altri due segnali nella stessa direzione: il 17 giugno 2026 ha annunciato LifeSciBench, benchmark dedicato a compiti di ricerca nelle scienze della vita, e lo stesso giorno ha presentato un “near-autonomous AI chemist” sviluppato con Molecule.one, sostenendo di aver migliorato una reazione difficile di chimica medicinale. A inizio giugno l’azienda aveva inoltre annunciato nuove capacità di GPT-Rosalind per ricerca biologica, genomica, chimica medicinale e workflow sperimentali. (OpenAI)
Sul fronte industriale, Isomorphic Labs ha annunciato nel 2026 un round da 2,1 miliardi di dollari per espandere la propria piattaforma di drug design basata su AI e far avanzare la pipeline di candidati. A gennaio aveva anche comunicato una collaborazione di ricerca con Johnson & Johnson su target multipli e modalità terapeutiche diverse. Sono segnali che mostrano come il mercato stia premiando non solo i modelli fondazionali generalisti, ma anche le società che promettono di tradurre l’AI in molecole, candidati clinici e accordi di sviluppo.
Questo non significa che il rischio sia sparito. Anzi. La lezione implicita del benchmark è che il settore ha già superato la fase in cui bastava mostrare una demo convincente. Adesso contano robustezza, verificabilità, audit dei passaggi analitici e capacità di evitare errori quando i dati sono incompleti o contraddittori. In biologia computazionale, sbagliare un cutoff o trattare come causale un segnale spurio non è un problema teorico: può voler dire investire mesi su un target sbagliato o fermare tardi un programma che non regge.
Dove può nascere il valore
L’utilità economica di questi sistemi, almeno nel breve periodo, non sembra stare nella piena autonomia. Sta nell’assistenza ad alto livello. OpenAI stessa scrive che modelli capaci di buone performance su GeneBench-Pro potrebbero aiutare i ricercatori a individuare il workflow corretto, esplorare i dati più rapidamente e aumentare ritmo, accuratezza e riproducibilità della ricerca. È un posizionamento meno spettacolare, ma più credibile per chi deve decidere budget, procurement e priorità tecnologiche.
Per il mercato, la domanda vera non è se l’AI sostituirà il biologo computazionale. La domanda è quanto lavoro qualificato riuscirà a comprimere senza aumentare il tasso di errore. Se un agente può ridurre le ore necessarie per scartare ipotesi deboli, diagnosticare problemi di qualità e proporre analisi corrette, il vantaggio economico è immediato anche con livelli di accuratezza lontani dalla perfezione. Se invece richiede supervisione continua e produce errori opachi, il risparmio si dissolve.
GeneBench-Pro misura proprio questa soglia. Oggi il benchmark dice che i modelli sono migliorati in fretta, ma non sono ancora abbastanza solidi da chiudere da soli il ciclo inferenziale. Per le imprese del biotech e della pharma è una notizia doppia: la promessa resta intatta, ma il valore si materializzerà soprattutto dove esistono già dati ben curati, team in grado di verificare i risultati e una catena decisionale pronta a usare l’AI come leva di produttività, non come scorciatoia.



Partecipa alla community