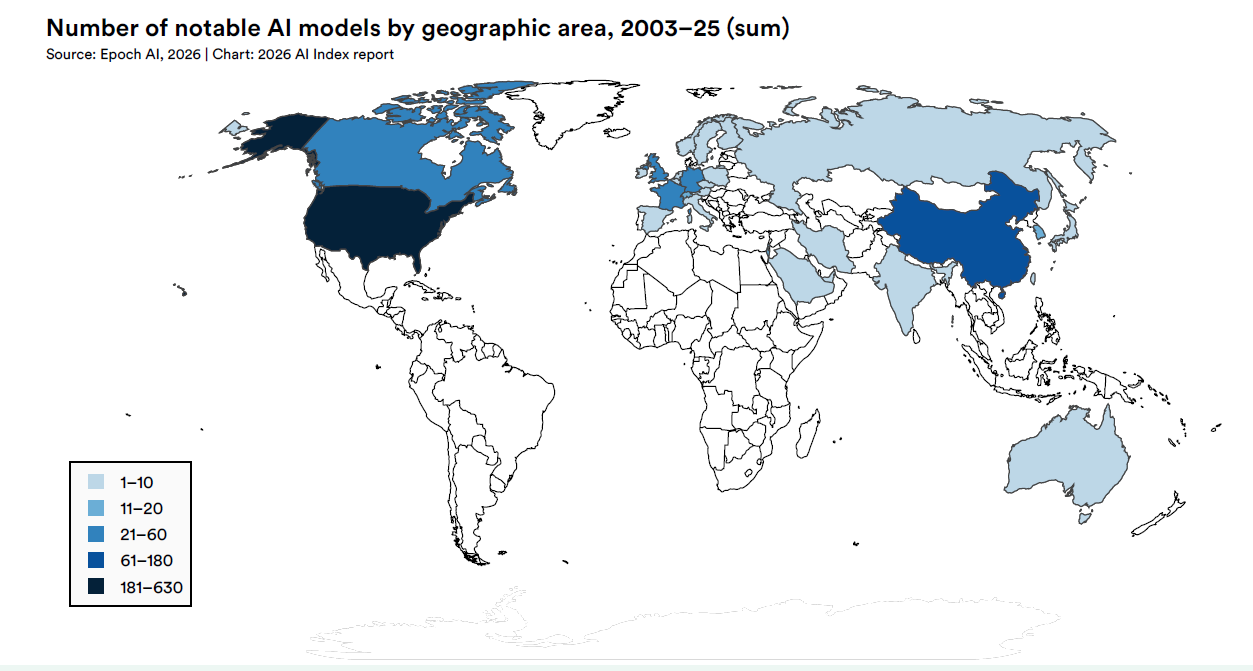
L’AI Index 2026 di Stanford, fotografando i numeri della ricerca e dello sviluppo, disegna un ecosistema che cresce e si restringe allo stesso tempo. Nel 2025 sono stati rilasciati 95 modelli “notable”, l’87 dei quali firmati da industria privata, appena 1 da laboratori accademici.
La concentrazione non si ferma al settore: OpenAI, Google e Alibaba da soli coprono 42 dei 95 modelli censiti, e il compute che li alimenta passa quasi interamente da una singola foundry taiwanese. La corsa all’intelligenza artificiale, mentre accelera sulle capacità, si sta contraendo sulle fonti.
Indice degli argomenti:
Industria al 91,6%, accademia all’1%
I numeri parlano da soli, però bisogna leggerli in sequenza. Nel 2025 Epoch AI ha identificato 87 modelli notable prodotti dall’industria, 1 dall’accademia, 5 da collaborazioni industria-accademia. La quota industriale, che nel 2010 era intorno al 50%, ha raggiunto il 91,58% in pochi anni e si è stabilizzata lì. Non è una novità assoluta, ma è la fotografia di un travaso quasi completo.
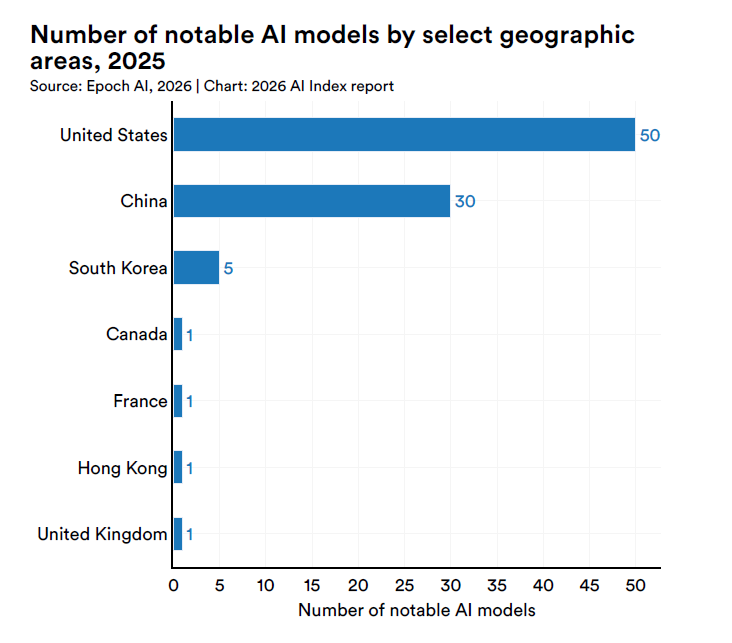
Dentro l’industria, la distribuzione è ancora più concentrata.
OpenAI con 19 modelli, Google con 12, Alibaba con 11, Anthropic e xAI con 7 ciascuno, DeepSeek a 5.
Dal 2014 Google ha prodotto 191 modelli notable, Meta 86, OpenAI 59, Microsoft e Nvidia 42 ciascuno. La piramide ha una base strettissima, e al vertice si siede un numero di soggetti che si contano su due mani.
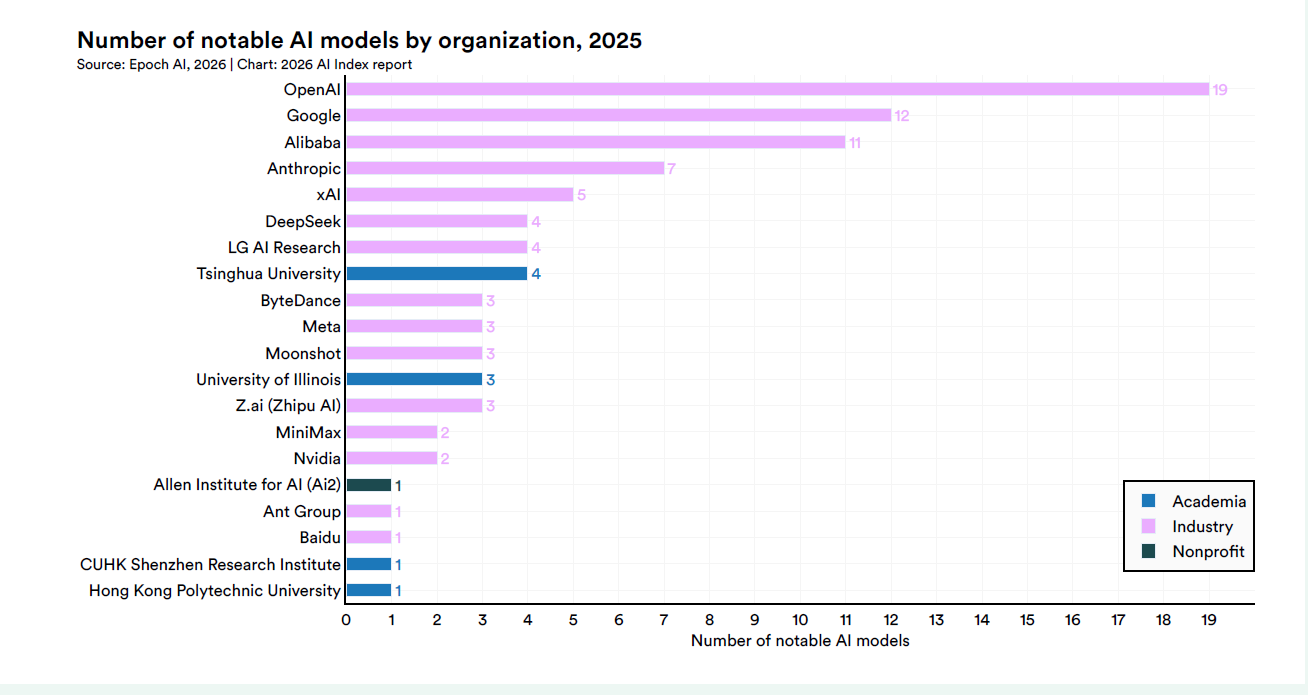
C’è una conseguenza concreta per chi disegna policy, per chi investe, per chi compra AI dentro un’organizzazione: le scelte tecniche della frontiera non sono più distribuite, sono decisioni di un gruppo ristretto.
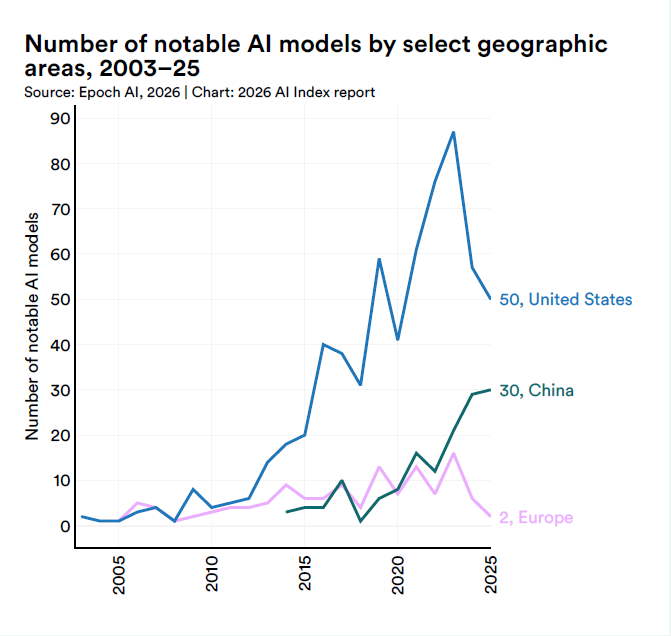
Quando OpenAI decide di non rilasciare il training code, quando Anthropic smette di dichiarare i parametri, quando Google non pubblica più la durata dell’addestramento, quelle decisioni non restano interne al laboratorio, ridisegnano l’epistemologia di tutto il settore.
Opacità come default: 80 modelli su 95 senza codice di training
Sul fronte della trasparenza, i dati dell’AI Index mostrano una inversione di rotta non ancora abbastanza discussa. Nel 2025, su 95 modelli notable, 80 sono stati rilasciati senza il training code corrispondente, contro 4 che hanno pubblicato il codice completo come open source. Nel 2020 le due categorie erano quasi equivalenti, oggi il rapporto è di 20 a 1. Il modello di accesso dominante è diventato l’API, che nel 2025 ha raccolto 45 dei 95 rilasci.
Parametri, dataset, durata del training sono sempre più spesso non dichiarati dai laboratori di frontiera. Il conteggio dei parametri è rimasto vicino al trilione per tre anni consecutivi, perché i frontier lab hanno smesso di riportarli e l’ultima misura stabile risale a prima del 2023.
Il training compute si può stimare indirettamente, e lì l’Index conferma che la crescita non si è fermata. Ma la capacità di chi fa ricerca esterna, audit, valutazioni di sicurezza è strutturalmente limitata, perché i tre pilastri della riproducibilità scientifica (codice, dati, procedura) non sono più disponibili.
Qui si apre un paradosso che vale la pena guardare in faccia: i modelli più capaci sono i meno trasparenti, e il settore in cui si chiede con più forza “sapere come funziona” è quello in cui si dichiara sempre meno.
Una singola foundry per quasi tutti i chip AI del mondo
Il capitolo compute dell’AI Index 2026 contiene uno dei dati più significativi di tutto il report, ed è un dato geopolitico. La capacità di calcolo globale per AI è cresciuta di 3,3 volte all’anno dal 2022, arrivando a circa 17,1 milioni di H100-equivalenti. Nvidia copre oltre il 60% di questa capacità, Google e Amazon buona parte del resto, Huawei una quota piccola ma in crescita.
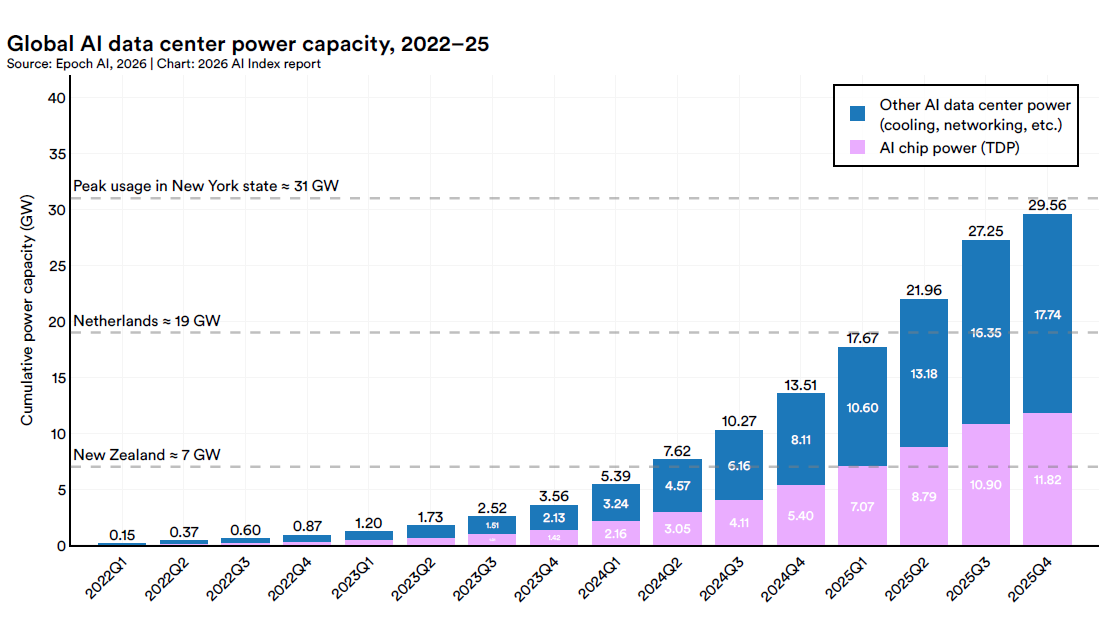
Il punto vero, però, è a monte. La quasi totalità dei chip AI di fascia alta viene fabbricata da TSMC, la Taiwan Semiconductor Manufacturing Company. Una singola azienda, in una singola isola, è il nodo su cui passa l’intera filiera globale dell’intelligenza artificiale. L’espansione TSMC negli Stati Uniti ha iniziato a operare nel 2025, ma l’ordine di grandezza è ancora periferico rispetto al cuore taiwanese della produzione.
Chiamarla dipendenza è riduttivo, è una monocoltura industriale. E come tutte le monocolture, è efficiente finché il contesto regge. Il conflitto commerciale tra Stati Uniti e Cina, le tensioni sullo Stretto, l’eventuale interruzione logistica per ragioni climatiche o geopolitiche, tutto passa attraverso quello stesso collo di bottiglia. L’AI Index non fa proiezioni di scenario, si limita a registrare il dato. Il lettore può e deve completare il ragionamento.
Data center a 29,6 GW: un’infrastruttura invisibile che consuma come uno Stato
Mentre si discute di modelli e benchmark, l’infrastruttura fisica che li sostiene ha assunto dimensioni paragonabili a sistemi statali. Gli Stati Uniti ospitano 5.427 data center, più di dieci volte qualunque altro paese al mondo.
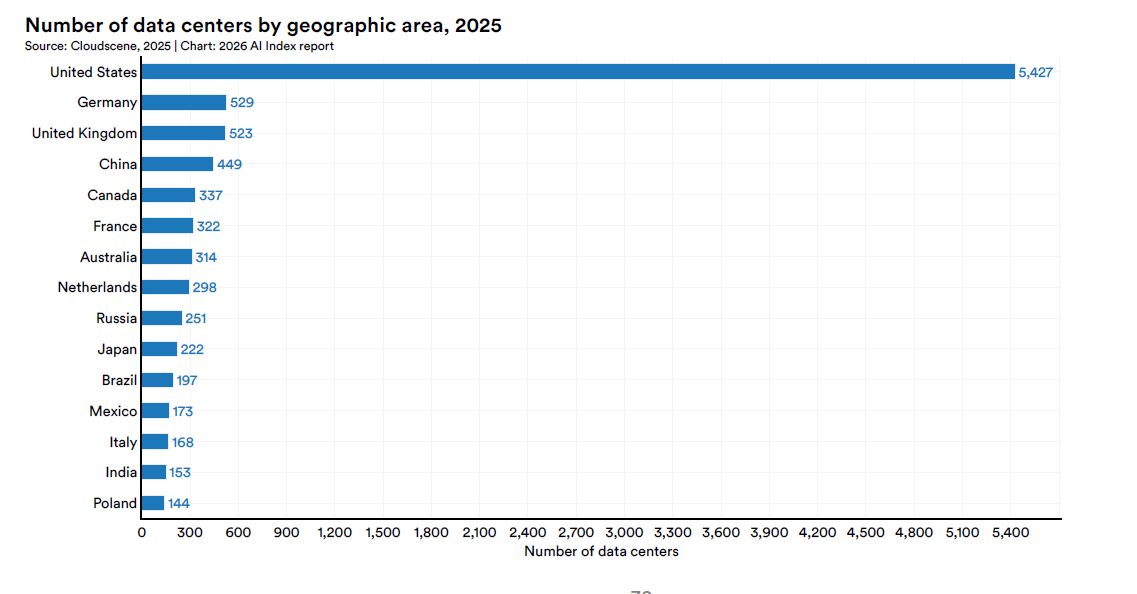
La capacità di potenza dei data center AI ha raggiunto i 29,6 GW nel quarto trimestre 2025, un valore comparabile al consumo dello Stato di New York nelle ore di picco, superiore al fabbisogno dei Paesi Bassi.
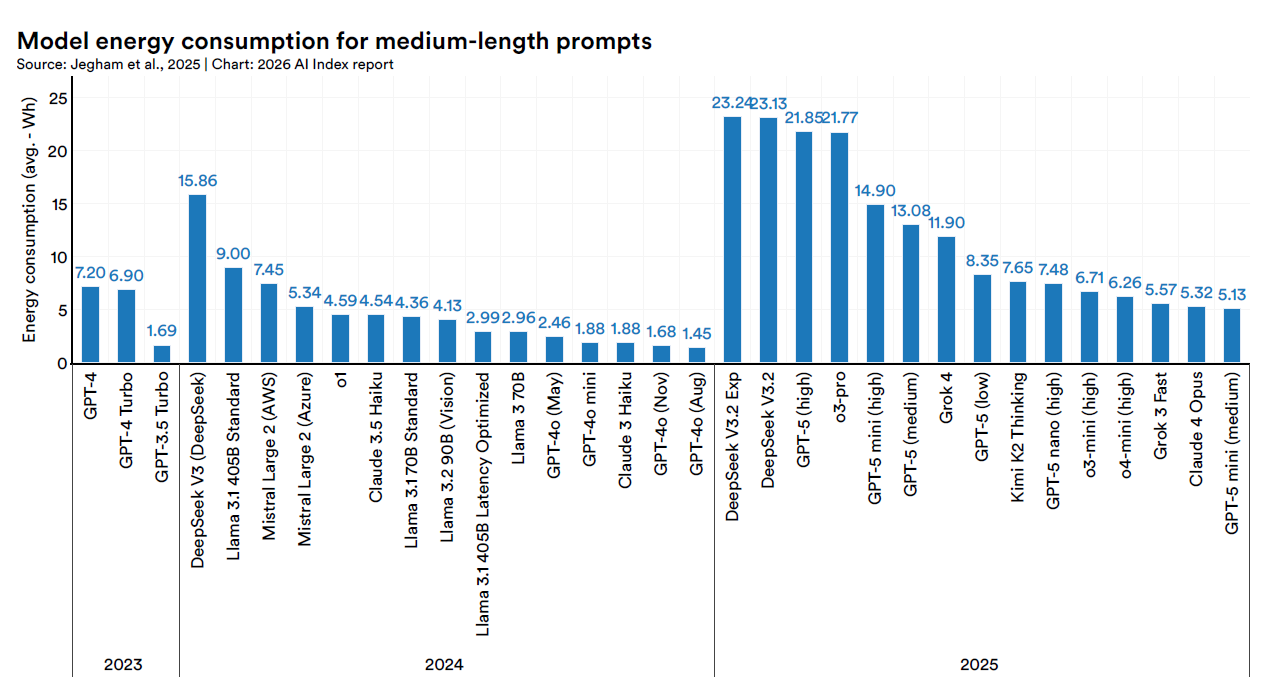
Il dato sulle emissioni è il corollario inevitabile. L’addestramento di Grok 4, rilasciato da xAI nel 2025, ha prodotto circa 72.816 tonnellate di CO2 equivalente. Per dare una scala: sono oltre 13mila anni di vita umana media, più della somma delle emissioni lifetime di mille auto. Nel 2012, l’addestramento di AlexNet ne produceva 0,01. In tredici anni l’ordine di grandezza si è spostato di sette zeri.
C’è un’eccezione che merita attenzione, seppur isolata. DeepSeek v3, modello cinese comparabile per dimensioni ad altri frontier, ha prodotto circa 597 tonnellate, un valore molto inferiore a modelli di taglia simile. La ragione è nel mix energetico, nell’efficienza hardware, nella durata e nell’architettura del training. Non tutta la scala produce lo stesso impatto, e questa è una delle leve su cui il settore può ancora intervenire prima di normalizzare numeri da prefisso geologico.
Sul fronte idrico, il quadro è analogo. L’inferenza annuale di GPT-4o, stimata in circa 1,3-1,6 milioni di kilolitri, potrebbe coprire il fabbisogno di acqua potabile di 12 milioni di persone. Quando si parla di “AI sostenibile”, raramente ci si ferma a quantificare i denominatori.
Il gender gap che non si muove da quindici anni
In mezzo a tante curve esponenziali, l’AI Index segnala un dato che è rimasto piatto dal 2010 al 2025: la distribuzione di genere tra ricercatori e inventori AI.
In Brasile, Corea del Sud e Giappone oltre l’80% dei talenti identificati è maschile. L’Italia, con il 29,5% di donne tra i suoi ricercatori AI top, si colloca tra i Paesi con rappresentanza femminile relativamente più alta, insieme ad Arabia Saudita (32,3%), Australia (30,1%) e Canada (29,6%). Nessun Paese si avvicina alla parità.
Il dato che pesa di più non è la percentuale in sé, ma la sua stabilità temporale. Dal 2010 al 2025, il rapporto maschi/femmine nella ricerca AI è rimasto sostanzialmente invariato in quasi ogni Paese misurato. Mentre tutto il resto del settore è cresciuto in modo esponenziale, questa dimensione non si è mossa.
La crescita del talento complessivo non ha prodotto nessun riequilibrio, ha solo ingrandito in modo proporzionale lo stesso squilibrio che c’era quindici anni fa.
OLMo contro Grok: quando meno è anche più
Un segnale controtendenza arriva dal lato dell’efficienza. OLMo 3.1 Think 32B, rilasciato dall’Allen Institute for AI, ha circa 32 miliardi di parametri, quasi 90 volte meno del trilione dichiarato di Grok 4. Eppure su diversi benchmark di riferimento i due raggiungono risultati comparabili. L’Index attribuisce la performance a tecniche di pruning, deduplicazione e curazione dei dati, più che a scala bruta.
È un dato che parla a chi progetta strategie enterprise, non solo a chi fa ricerca. La traiettoria dominante del settore, fatta di più parametri, più compute, più energia, non è l’unica strada praticabile verso la capacità. La qualità del dato, la metodologia di post-training, le tecniche di ottimizzazione architetturale hanno già dimostrato di poter comprimere di due ordini di grandezza il costo computazionale senza un collasso proporzionale delle prestazioni.
Per le imprese che valutano investimenti in AI, questa è la domanda operativa che conta: serve davvero il modello più grande, o serve il modello più adatto al problema?
Una supply chain globale che va ripensata
L’AI Index 2026, nel capitolo sulla ricerca e sviluppo, consegna una mappa che vale la pena leggere per intero prima di tornare ai titoli su modelli e benchmark.
I protagonisti si stanno riducendo di numero, le informazioni disponibili si stanno riducendo in quantità e qualità, l’infrastruttura fisica si sta concentrando in un punto solo del mondo, l’impronta ambientale si sta espandendo a velocità superiore a quella dell’efficienza hardware.
Ogni organizzazione che sta pianificando un’adozione AI significativa dovrebbe guardare questi quattro assi insieme, non separatamente. La scelta del fornitore, il livello di dipendenza da API proprietarie, la resilienza della supply chain hardware a cui ci si lega, il costo ambientale che si sta implicitamente firmando nei propri scope emissioni. Sono decisioni di governance, non solo di procurement. E la finestra per farle con consapevolezza si sta restringendo proprio mentre si allarga quella degli investimenti.
La domanda che l’AI Index lascia aperta, senza formularla esplicitamente, è se un ecosistema così concentrato possa mantenere nel lungo periodo le sue stesse promesse di progresso. Finora, la concentrazione ha prodotto velocità. Il prossimo test sarà se saprà anche produrre affidabilità.







Partecipa alla community