
OpenAI introduce GPT-5.4 mini e GPT-5.4 nano, due modelli progettati per rispondere alle esigenze di velocità ed efficienza nei carichi di lavoro ad alto volume. Queste soluzioni portano molte delle capacità del modello principale GPT-5.4 in formati più leggeri, mantenendo prestazioni elevate e tempi di risposta ridotti.
GPT-5.4 mini rappresenta un’evoluzione significativa rispetto al precedente GPT-5 mini, con miglioramenti evidenti nella programmazione, nel ragionamento e nella comprensione multimodale. La sua velocità è oltre il doppio, rendendolo competitivo anche rispetto al modello più grande in diversi benchmark.
Indice degli argomenti:
GPT-5.4 nano: prestazioni elevate con costi ridotti
GPT-5.4 nano si posiziona come l’opzione più economica e veloce della famiglia. È pensato per attività come classificazione, estrazione dati e ranking, oltre che per supportare subagenti impegnati in compiti più semplici.
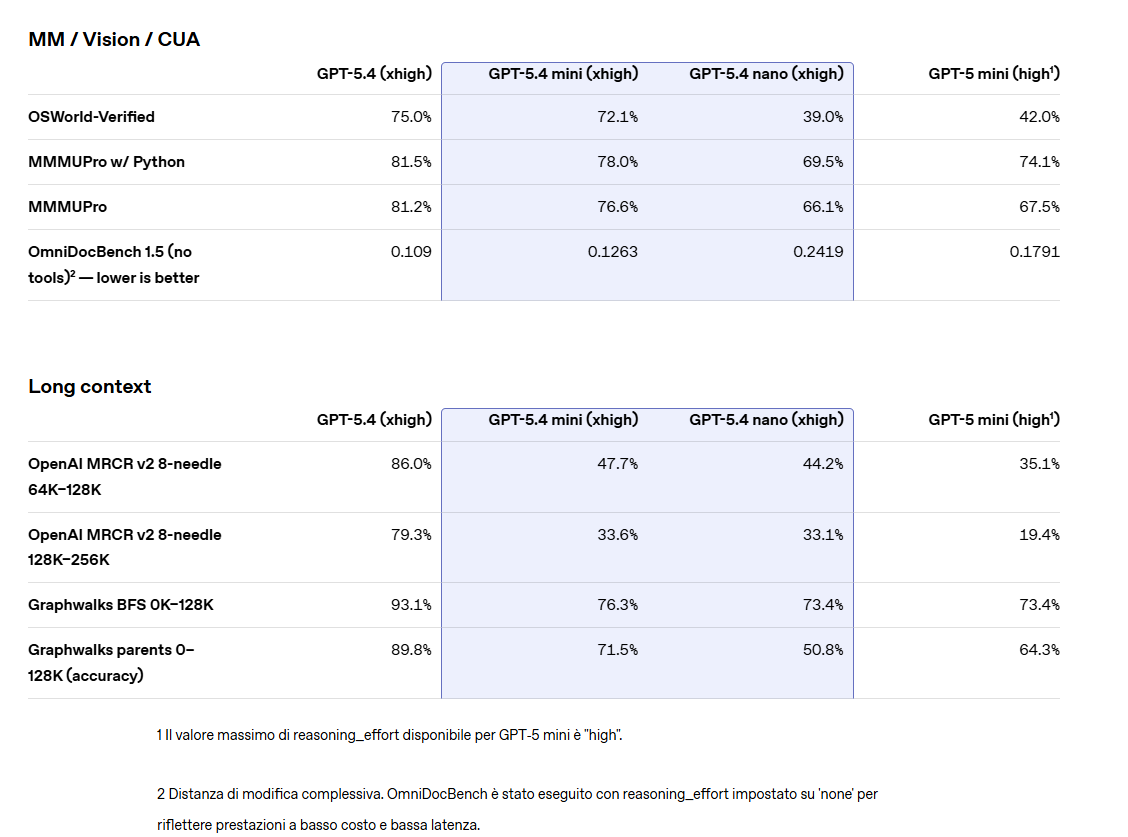
Entrambi i modelli sono stati sviluppati per contesti in cui la latenza è fondamentale: assistenti di programmazione reattivi, sistemi multimodali in tempo reale e applicazioni capaci di interpretare immagini e screenshot. In questi scenari, la rapidità di risposta diventa più importante della dimensione del modello.
Focus sulla programmazione
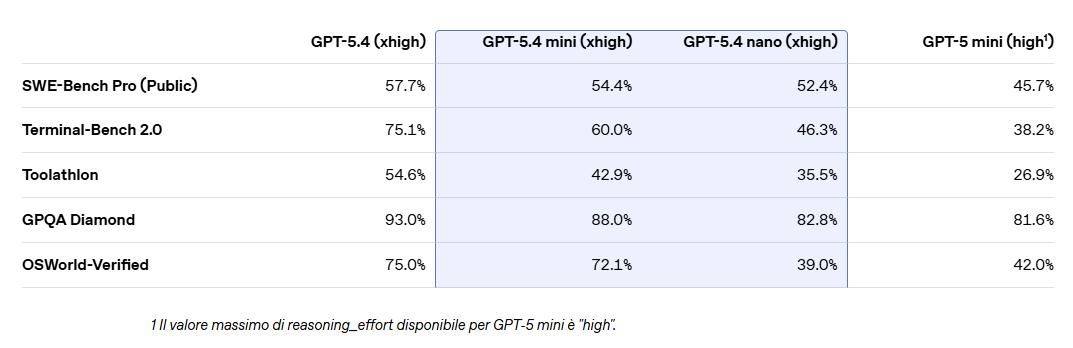
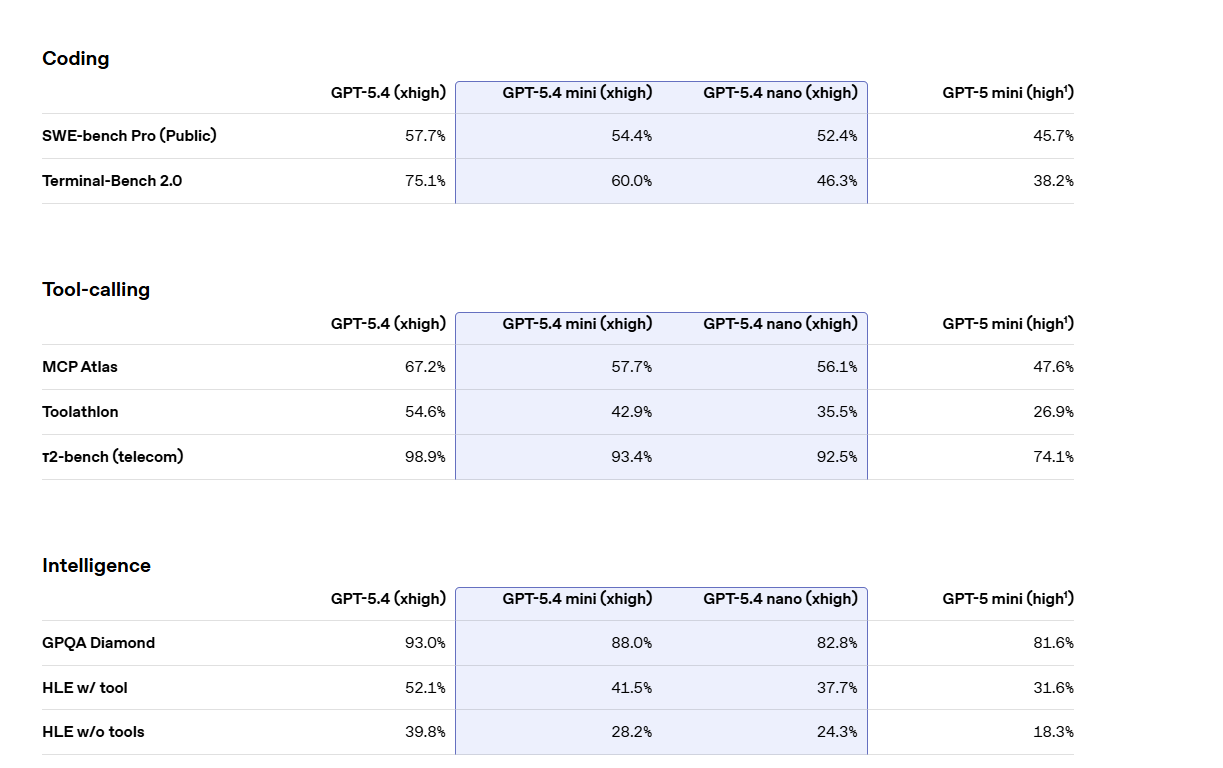
Uno degli ambiti in cui GPT-5.4 mini e nano mostrano maggiore efficacia è quello dello sviluppo software. I modelli gestiscono modifiche mirate, navigazione nel codice, generazione di interfacce e debugging rapido, favorendo cicli di lavoro più veloci.
GPT-5.4 mini, in particolare, riesce a superare costantemente il predecessore mantenendo la stessa latenza e avvicinandosi alle prestazioni del modello principale, offrendo un equilibrio ottimale tra velocità e qualità.
“GPT-5.4 mini offre solide prestazioni nei carichi di lavoro agentici – afferma Bertie Vidgen, ricerca sull’AI di Mercor”. Nelle nostre valutazioni APEX-Agents, il modello ha superato Gemini 3 Flash e Sonnet 4.6 nelle attività agentiche, mostrando miglioramenti significativi quando vengono applicati livelli più elevati di sforzo di ragionamento e budget di token.”
Il ruolo strategico dei subagenti
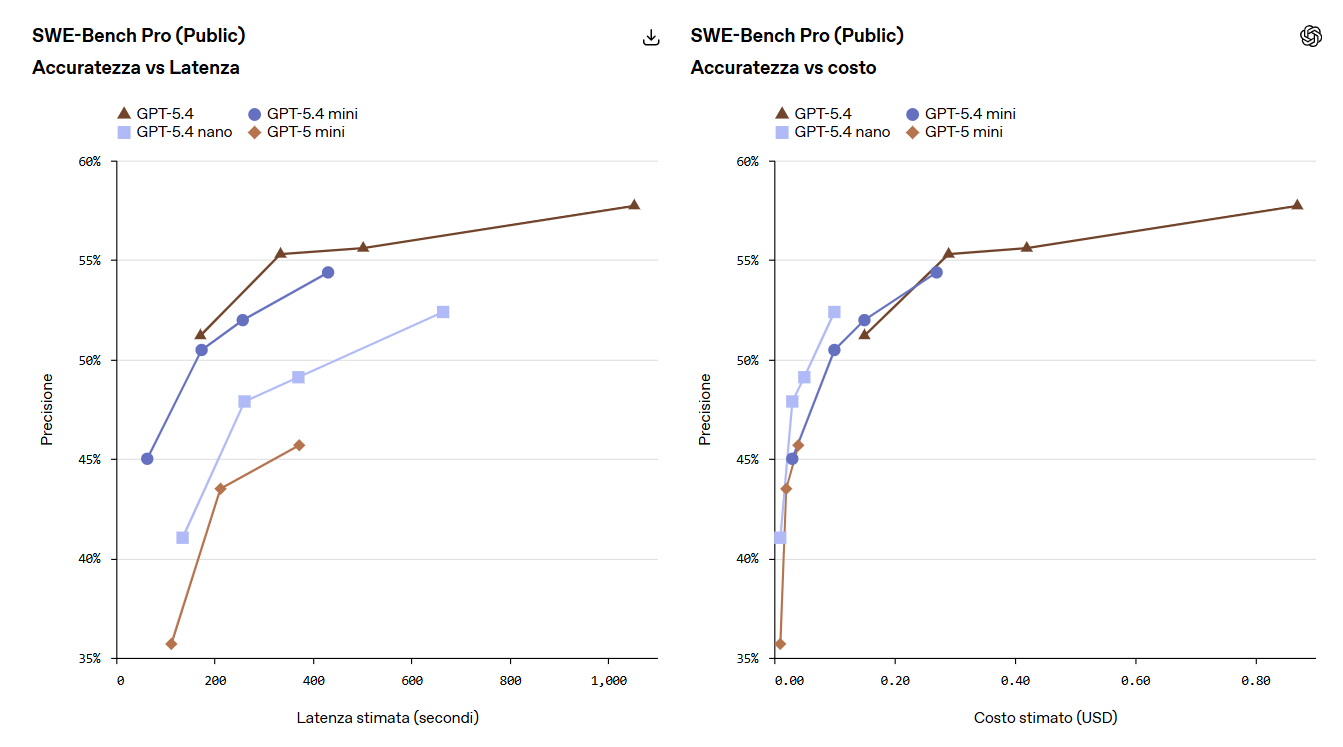
Un elemento centrale è l’utilizzo nei sistemi a più livelli. In questo approccio, un modello più grande si occupa della pianificazione e delle decisioni, mentre modelli più piccoli come GPT-5.4 mini eseguono sotto-compiti in parallelo.
Questo consente agli sviluppatori di costruire architetture più efficienti: i modelli principali coordinano, mentre quelli compatti gestiscono operazioni su larga scala in modo rapido ed economico.
“GPT-5.4 mini alza l’asticella nella velocità quotidiana per gli sviluppatori”, afferma Brittany O’Shea, senior director of Product, GitHub. “Nelle nostre valutazioni, è tra i migliori modelli mini di OpenAI per tempo al primo token, si muove con facilità nelle codebase e offre prestazioni eccellenti nei flussi di lavoro in stile grep”.
Capacità multimodali e uso del computer
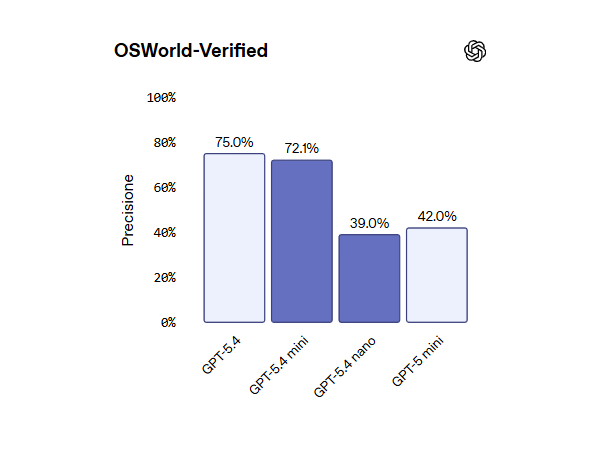
GPT-5.4 mini si distingue anche nelle attività multimodali, in particolare nell’interazione con interfacce software. Il modello è in grado di interpretare screenshot complessi e completare operazioni legate all’uso del computer con maggiore rapidità.
Nei test, le sue prestazioni si avvicinano a quelle del modello GPT-5.4, superando nettamente le versioni precedenti in scenari reali.
“GPT-5.4 rappresenta un passo avanti per i modelli mini e nano nelle nostre valutazioni interne”, commenta Jerry Ma, vice CTO di Perplexity. “Mini offre solide capacità di ragionamento, mentre nano è reattivo ed efficiente nei flussi di lavoro conversazionali in tempo reale”.
Disponibilità e integrazione
GPT-5.4 mini è disponibile tramite API, Codex e ChatGPT, con supporto per testo, immagini, strumenti e funzionalità avanzate. Offre una finestra di contesto ampia e costi contenuti, rendendolo adatto a un’ampia gamma di applicazioni.
GPT-5.4 nano è invece disponibile esclusivamente via API, con tariffe ancora più basse, pensate per utilizzi su larga scala dove il costo è un fattore determinante.





Partecipa alla community