
L’inarrestabile OpenAI annuncia il rilascio in anteprima di ricerca di GPT-5.3-Codex-Spark, una versione più compatta di GPT-5.3-Codex e primo modello progettato specificamente per la programmazione in tempo reale all’interno di Codex.
Codex-Spark rappresenta il primo traguardo della collaborazione con Cerebras Systems, annunciata a gennaio. Il modello è ottimizzato per funzionare su hardware a latenza ultra-ridotta, raggiungendo oltre 1000 token al secondo pur mantenendo elevate capacità operative nei compiti di sviluppo software reali.
Indice degli argomenti:
Anteprima per sviluppatori
Codex-Spark è disponibile come anteprima di ricerca per gli utenti ChatGPT Pro tramite app Codex, CLI ed estensione VS Code.
Durante questa fase iniziale:
- Dispone di una finestra di contesto da 128k token
- È solo testuale
- Ha limiti di utilizzo separati dagli standard
- Potrebbe prevedere code temporanee in caso di alta domanda
L’obiettivo è consentire agli sviluppatori di sperimentare fin da subito, mentre OpenAI amplia la capacità dei datacenter e perfeziona l’esperienza utente.
Velocità e intelligenza: collaborazione istantanea
Codex-Spark è progettato per il lavoro interattivo, dove la latenza conta tanto quanto l’intelligenza del modello. Gli sviluppatori possono:
- Interrompere o reindirizzare il modello in tempo reale
- Iterare rapidamente con risposte quasi istantanee
- Apportare modifiche mirate e leggere al codice
A differenza dei modelli più grandi, non esegue automaticamente test se non richiesto, mantenendo uno stile operativo snello e focalizzato.
Prestazioni nei benchmark
Nonostante le dimensioni ridotte, Codex-Spark mostra prestazioni solide nei benchmark di ingegneria software agentica come SWE-Bench Pro e Terminal-Bench 2.0, completando le attività in una frazione del tempo rispetto a GPT-5.3-Codex.
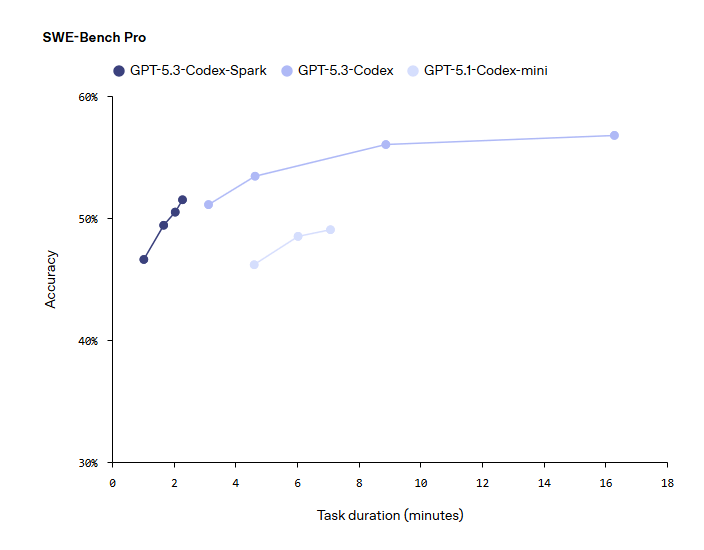
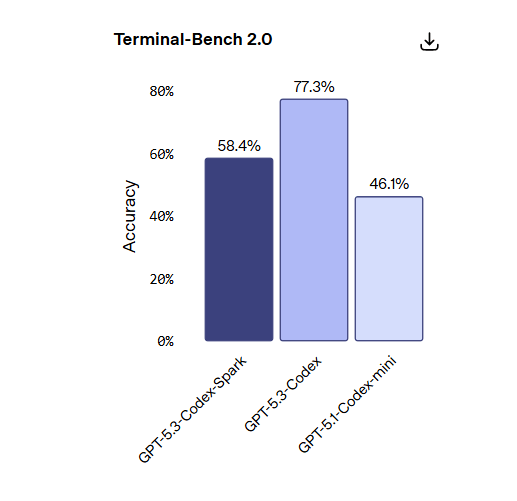
Riduzione drastica della latenza
Durante lo sviluppo, OpenAI ha migliorato l’intera pipeline richiesta-risposta, introducendo ottimizzazioni che beneficeranno tutti i modelli.
Grazie a:
- Connessione WebSocket persistente
- Ottimizzazioni nella Responses API
- Riscrittura di parti chiave dello stack di inferenza
Sono stati ottenuti risultati significativi:
- –80% overhead per roundtrip client/server
- –30% overhead per token
- –50% tempo al primo token visibile
Il percorso WebSocket è attivo di default per Codex-Spark e presto diventerà standard per tutti i modelli.
Powered by Cerebras
Codex-Spark gira sul Wafer Scale Engine 3 di Cerebras Systems, un acceleratore AI progettato per inferenza ad altissima velocità.
Le GPU restano fondamentali per l’addestramento e l’inferenza su larga scala, ma l’architettura Cerebras eccelle nei flussi di lavoro che richiedono latenza estremamente bassa. Le due tecnologie possono essere combinate per massimizzare le prestazioni.

Come ha dichiarato Sean Lie, CTO e co-fondatore di Cerebras, questa collaborazione apre la strada a nuovi modelli di interazione e casi d’uso finora impossibili.
Sicurezza e valutazioni
Codex-Spark include lo stesso addestramento in materia di sicurezza dei modelli principali, comprese valutazioni in ambito cyber.
Secondo il processo standard di distribuzione di OpenAI, il modello non raggiunge le soglie critiche previste dal Preparedness Framework per capacità elevate in cybersecurity o biologia.
Il futuro di Codex
Codex-Spark è il primo passo verso un Codex con due modalità complementari:
- Ragionamento a lungo termine e task autonomi
- Collaborazione in tempo reale per iterazioni rapide
In prospettiva, le modalità si fonderanno: l’utente potrà lavorare in un loop interattivo mentre sub-agenti gestiscono compiti più lunghi in background o distribuiscono attività su più modelli in parallelo.
Con modelli sempre più potenti, la velocità di interazione diventa il vero collo di bottiglia. L’inferenza ultra-rapida di Codex-Spark riduce drasticamente questo limite, rendendo lo sviluppo software più naturale, fluido e immediato.






Partecipa alla community
Secondo lei, in prospettiva, questa modalità in tempo reale potrà sostituire del tutto i modelli più “riflessivi”, oppure le due modalità resteranno complementari per casi d’uso diversi? <a href=”https://bse.telkomuniversity.ac.id/extreme-programming-xp-pendekatan-agile-dalam-pengembangan-software/”>software engineering</a>