
Usare un modello di frontiera come GPT-5.2 o Claude 3.5 Opus per estrarre una data da una fattura o classificare un ticket di supporto è un crimine economico. Si compra affidabilità percepita e si paga con latenza, consumo di token e dipendenza da un’inferenza seriale che diventa un collo di bottiglia nei processi. Quando il lavoro è ripetitivo e verificabile, l’onniscienza è solo un modo elegante per bruciare budget.
Al MIT CSAIL hanno sviluppato un’alternativa che potrebbe diventare una buona soluzione ingegneristica a questo problema. DisCIPL, nel paper, è l’acronimo di Distributional Constraints by Inference Programming with Language Models. L’idea centrale è far scrivere a un modello molto capace un programma di inferenza che descrive come cercare la soluzione e come verificarla, e poi far eseguire quel programma da una popolazione di modelli piccoli che lavorano in parallelo. Il risultato atteso è un controllo sul rispetto dei vincoli e un uso più razionale del calcolo.
Indice degli argomenti:
Come funziona DisCIPL
DisCIPL separa due attività che nelle aziende vengono spesso confuse quando si parla di AI: definire il lavoro ed eseguire il lavoro. La definizione del lavoro viene affidata a un modello grande, chiamato Planner. Il Planner non produce direttamente la risposta finale, ma scrive un set di istruzioni eseguibili che specificano cosa deve essere rispettato e come verificare che sia rispettato. Nel paper, questo set di istruzioni viene chiamato inference program.
L’esecuzione del lavoro viene affidata a modelli piccoli, chiamati Follower. I Follower generano proposte di risposta e parti di risposta seguendo le istruzioni. L’inference engine coordina più Follower in parallelo, confronta i risultati e continua a cercare fino a quando non trova un output che passa i controlli. L’idea chiave è che il calcolo viene spostato su tentativi paralleli economici, mentre il modello costoso viene usato per scrivere le regole e la procedura.
Per applicare nel pratico il framework, bisogna quindi capire se lo use case specifico ha regole verificabili e se esistono margini per sostituire un’unica chiamata costosa, che prova a fare tutto, con una procedura che guida molti tentativi economici e controllati.

DisCIPL applicato in azienda
Nel paper e nelle demo citate dal MIT, i vincoli sono requisiti oggettivi che si possono controllare con un test: lunghezza esatta di una frase, parole obbligatorie in posizioni precise, limite di spesa in una lista della spesa, numero di giorni in un itinerario, numero massimo di parole in un testo. Se una risposta non rispetta il vincolo, lo si vede subito, senza interpretazioni.
Nelle applicazioni aziendali pratiche, i vincoli sono ovunque. Una data deve essere in un formato valido e plausibile. Un importo deve quadrare con Iva e totale. Un ticket deve finire in una categoria ammessa dal catalogo, con campi obbligatori, magari in JSON, magari con un livello minimo di confidenza. Se si riesce a scrivere il controllo, si riesce anche a costruire un sistema che scarta automaticamente le risposte sbagliate.
Il vantaggio economico dell’applicazione di questo sistema sta nel modo in cui si spende l’inferenza. I modelli di reasoning di fascia alta tendono a ragionare producendo molto testo intermedio, e quel testo costa. DisCIPL sposta parte di quel lavoro in un programma breve e in tentativi paralleli su modelli piccoli.
I risultati di DisCIPL
Il laboratorio di ricerca del MIT riporta che, nei loro esperimenti, DisCIPL ha ottenuto un ragionamento più corto del 40,1% e risparmi di costo dell’80,2% rispetto a o1, modello di OpenAI usato come riferimento. Riporta anche che i modelli piccoli usati come Follower sono da 1.000 a 10.000 volte più economici per token rispetto a modelli di reasoning comparabili, e che questo consente di far girare decine di modelli in parallelo a costi contenuti. La spesa diventa anche più prevedibile, perché si paga soprattutto la definizione della procedura e molto meno l’esplorazione controllata delle alternative.
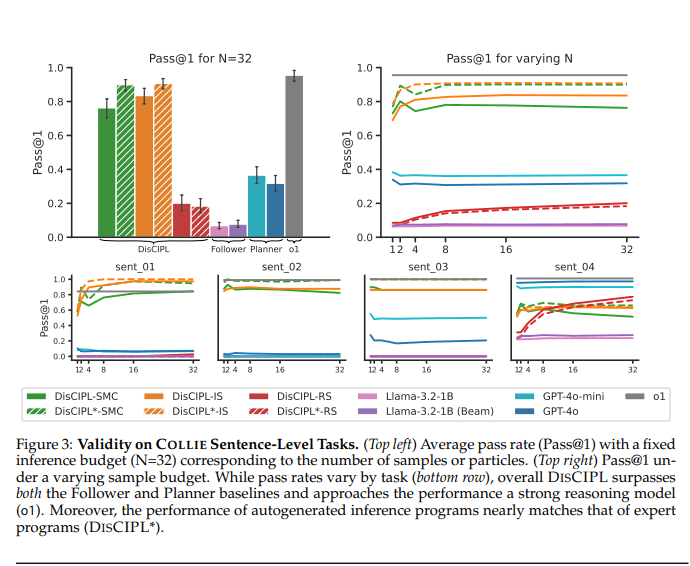
Il contesto perfetto per DisCIPL sono le pipeline che prevedono generazione vincolata di testo, come potrebbe essere una lista della spesa con budget e itinerari. MIT News cita esplicitamente compiti come ingredient list con budget, travel itinerary e grant proposals con limiti di parole, usati per confrontare l’approccio con GPT-4o e con o1.
Il passaggio da queste applicazioni da laboratorio ad applicazioni aziendali per la gestione di fatture e ticket di supporto è una conseguenza logica. Funziona quando si riesce a tradurre l’obiettivo in controlli chiari.
Una fattura, per esempio, permette controlli standard: data in formato valido, data non futura, data coerente con scadenza, importi che tornano, valuta ammessa, campi presenti. Il Planner può generare una procedura che dice dove cercare i candidati nel testo e come validarli. I Follower producono più ipotesi in parallelo. Il sistema accetta solo ciò che passa i controlli. Se nessuna ipotesi passa, il sistema segnala un’eccezione invece di inventare una data plausibile.
Anche un ticket di supporto permette controlli altrettanto standardizzati, come categorie finite, regole di routing, campi obbligatori, output strutturato. Anche qui, il vantaggio non arriva da una risposta intelligente in senso generico, ma da una classificazione verticale che rispetta standard e che passa da una fase di audit strutturata.
Come adottare DisCIPL
DisCIPL non è un prodotto già pronto e industrializzato. È un framework di ricerca e, soprattutto, un modello replicabile in contesti reali. L’adozione in azienda significa costruire una pipeline dove i vincoli vengono formalizzati, i controlli diventano parte del processo e il caso d’uso viene scelto accuratamente.
Il punto di partenza è identificare processi in cui l’errore si definisce con un test e non con un’opinione. Poi si misura quanto costa oggi l’approccio che utilizza un modello di frontiera in termini di token, tempi, rielaborazioni e casi ambigui scalati a operatore. L’ultimo step è la discussione pratica dell’architettura da implementare. Se il processo è pieno di ambiguità non verificabili, DisCIPL perde vantaggio perché i controlli non esistono o non sono affidabili.





Partecipa alla community