OpenAI introduce GPT-5.2, una nuova generazione di modelli pensata per supportare attività professionali complesse, grazie a un miglioramento significativo nella produttività e nella capacità di gestire processi di lunga durata. Secondo i dati disponibili, il modello riduce il carico di lavoro manuale e incrementa l’efficienza complessiva degli utenti, offrendo un livello di assistenza non ancora raggiunto.
L’annuncio arriva a poche settimane dal lancio del modello GPT-5.1 da parte di OpenAI. Anche i concorrenti Anthropic e Google hanno presentato nuovi modelli il mese scorso, spingendo OpenAI a dichiarare uno sforzo da “codice rosso” per migliorare ChatGPT e accantonare altri progetti.
Il tutto fa parte di una battaglia tra le principali aziende tecnologiche per creare il modello più utilizzato, mentre consumatori e imprese stanno integrando sempre di più l’AI nelle loro attività quotidiane e nei flussi di lavoro.
OpenAI punta sulla sua famiglia di modelli GPT per definire il futuro, mentre cerca di giustificare la propria valutazione da 500 miliardi di dollari e oltre 1,4 trilioni di dollari di investimenti previsti.
Indice degli argomenti:
GPT-5.2 figlio del “code red” lanciato da Sam Altman
“Abbiamo annunciato il code red per segnalare chiaramente all’azienda che vogliamo concentrare le risorse in un’area specifica; è un modo per definire le priorità e stabilire cosa può essere messo in secondo piano”, ha dichiarato Fidji Simo, CEO delle applicazioni di OpenAI, durante un briefing l’11 dicembre. “Abbiamo aumentato le risorse dedicate a ChatGPT in generale; direi che questo aiuta nel rilascio del modello, ma non è il motivo per cui esce proprio questa settimana”.
Nella stessa data, il CEO di OpenAI, Sam Altman, ha detto che il rilascio del modello Gemini 3 di Google ha avuto un impatto minore sulle metriche dell’azienda rispetto a quanto inizialmente temuto. Ha aggiunto di aspettarsi che OpenAI esca dalla fase di codice rosso entro gennaio. “Credo che quando emerge una minaccia competitiva, sia importante concentrarsi su di essa e affrontarla rapidamente”, ha affermato Altman.
Prestazioni superiori nei benchmark professionali
GPT-5.2 stabilisce nuovi standard in una vasta gamma di benchmark dedicati alle professioni specialistiche. Nei test GDPval, dedicati al lavoro informativo in 44 professioni chiave, il modello supera o eguaglia esperti umani nel 70,9% dei casi. Il risultato arriva con una velocità 11 volte maggiore e costi inferiori all’1% rispetto ai professionisti.
La qualità dei deliverable – fogli di calcolo, presentazioni, diagrammi, modelli finanziari – risulta chiaramente superiore alle versioni precedenti, tanto da essere giudicata “simile al lavoro di un team professionale”.


Programmazione: un salto netto nel debugging e nello sviluppo
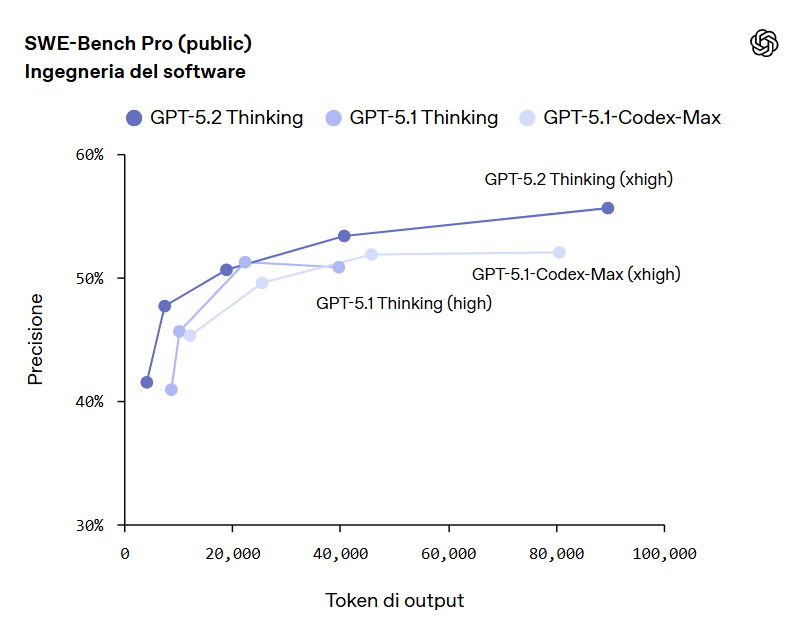
Nel campo dell’ingegneria del software, GPT-5.2 Thinking raggiunge nuovi massimi con il 55,6% su SWE-bench Pro, un benchmark considerato particolarmente rigoroso. Risultati eccellenti emergono anche su SWE-bench Verified, dove il modello ottiene l’80%.
Questo si traduce, in pratica, in una capacità più affidabile di individuare bug, implementare nuove funzionalità, rifattorizzare codice complesso e completare correzioni end-to-end con un intervento umano minimo.
L’ultimo modello di Anthropic, Opus 4.5, ottiene un punteggio più alto di GPT-5.2 su SWE-Bench Verified. OpenAI ha spiegato ai giornalisti che quel benchmark è meno “resistente alla contaminazione, impegnativo, diversificato e rilevante dal punto di vista industriale” rispetto a SWE-Bench Pro.
Riduzione delle allucinazioni e maggiore affidabilità
Uno dei progressi più concreti riguarda la riduzione degli errori. Rispetto a GPT-5.1, il nuovo modello presenta il 38% di risposte errate in meno nelle query testate. Per i professionisti significa maggiore affidabilità nelle ricerche, nella scrittura tecnica, nell’analisi e nei processi decisionali.

Gestione di contesti lunghi e analisi approfondite
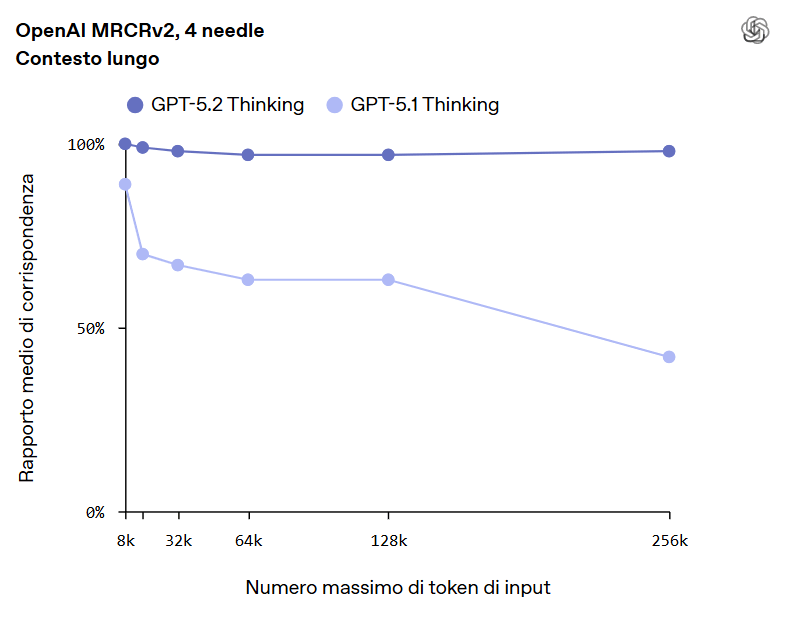
GPT-5.2 eccelle nel ragionamento su volumi di testo molto estesi, raggiungendo prestazioni di punta su OpenAI MRCRv2. Il modello mantiene coerenza e accuratezza fino a 256.000 token, facilitando l’analisi di documenti complessi come contratti, report, ricerche scientifiche e progetti multi-file.
Grazie al nuovo endpoint /compact, inoltre, può superare la tradizionale finestra di contesto, permettendo flussi di lavoro ancora più articolati.

Visione artificiale più precisa e contestuale
Sul fronte della visione, GPT-5.2 dimezza il tasso di errore nella comprensione di grafici scientifici e analisi di interfacce software. Nei benchmark CharXiv e ScreenSpot-Pro ottiene miglioramenti sostanziali, mostrando una comprensione più accurata dei layout e dei rapporti spaziali tra gli elementi.
Questo rende il modello particolarmente utile in domini come ingegneria, design, product management e finanza.

Strumenti: un uso più efficace e coordinato
Nel benchmark Tau2-bench Telecom, GPT-5.2 raggiunge una precisione del 98,7%, dimostrando capacità avanzate nell’utilizzo degli strumenti durante interazioni multi-turno. Il modello riesce a coordinare flussi complessi, come la gestione dei reclami di viaggio, l’estrazione di dati da più sistemi e la generazione di output finali completi.
Matematica e scienze: supporto alla ricerca avanzata
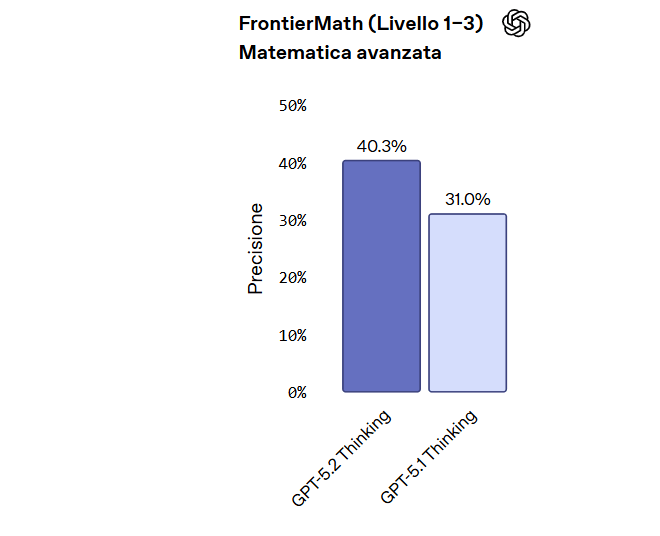
Il modello mostra eccellenza anche nei domini tecnico-scientifici:
- 92,4% su GPQA Diamond
- 40,3% su FrontierMath
- risultati record su ARC-AGI-1 e ARC-AGI-2
È già stato utilizzato per affrontare problemi di matematica avanzata, arrivando a proporre dimostrazioni successivamente validate da ricercatori umani.

L’adozione da parte delle aziende
Organizzazioni come Notion, Box, Shopify, JetBrains e Databricks hanno confermato miglioramenti tangibili nella capacità del modello di ragionare nel lungo termine, gestire strumenti e svolgere analisi complesse. Alcune aziende hanno semplificato intere architetture multi-agente grazie all’affidabilità del modello.
“Abbiamo riscontrato che GPT-5.2 è significativamente più capace nel ragionamento complesso su documenti e tabelle multipli – afferma Patrick Wendell, VP e cofondatore di Databricks – come misurato dal nostro benchmark OfficeQA, che valuta gli agenti di IA su attività di ragionamento ancorate al mondo reale e di rilevante valore economico. GPT-5.2 supera molti modelli di IA esistenti ed eccelle nell’estrazione strutturata e nell’analisi dei documenti; interpreta tabelle complesse ed esegue calcoli precisi basati su dati aziendali reali. Questo rende il modello ideale per molti dei nostri prodotti basati su agenti”.
“GPT‑5.2 offre una precisione superiore nel seguire le istruzioni e nell’attivare gli strumenti anche ai livelli di ragionamento più bassi, con output rapidi e affidabili, e si adatta ad analisi più approfondite quando necessario”, dichiara Ben Lafferty, staff engineer di Shopify.
Disponibilità, piani e costi
GPT-5.2 – nelle versioni Instant, Thinking e Pro – è in distribuzione su ChatGPT a partire dai piani Plus, Pro, Go, Business ed Enterprise. GPT-5.1 rimarrà disponibile per tre mesi come modello legacy.

Sull’API, GPT-5.2 Thinking è già disponibile come gpt-5.2, mentre la versione Instant è pubblicata come gpt-5.2-chat-latest. Il costo in API riflette le capacità superiori del modello, pur rimanendo competitivo rispetto ai modelli più avanzati.

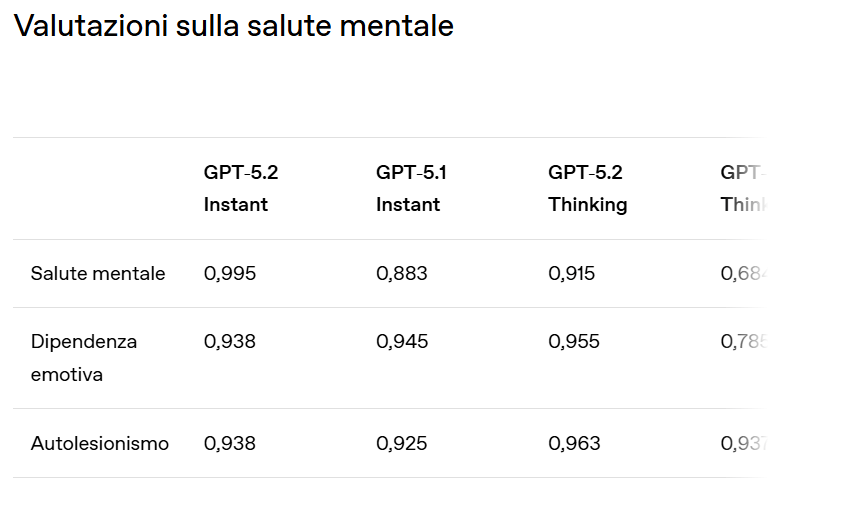
Sicurezza e protezione degli utenti
OpenAI rafforza ulteriormente i sistemi di sicurezza, con miglioramenti nella gestione delle conversazioni sensibili e una nuova tecnologia di previsione dell’età per proteggere gli utenti più giovani. Il modello è stato addestrato per mantenere risposte utili senza superare i limiti di sicurezza, riducendo errori e fraintendimenti nelle interazioni delicate.
Una nuova base per il futuro dell’AI professionale
GPT-5.2 rappresenta un passo significativo nella direzione di un’AI più competente, affidabile e utilizzabile nel mondo reale. Sebbene restino sfide da affrontare, il modello segna un avanzamento importante nell’integrazione dell’intelligenza artificiale nei processi professionali a lungo termine.
GPT-5.2 rappresenta un’evoluzione notevole nella linea dei modelli OpenAI, ma il suo impatto va letto con attenzione critica. Le prestazioni nei benchmark professionali -dove supera o eguaglia esperti umani nel 70,9% dei casi – indicano un progresso tecnico significativo, ma non necessariamente una sostituzione diretta del lavoro umano. Molti test misurano infatti compiti isolati, non l’intero processo decisionale, collaborativo e contestuale tipico delle professioni reali
Nel campo della programmazione, il modello ottiene risultati impressionanti nei benchmark SWE-bench, ma resta il limite della supervisione: la capacità di risolvere ticket complessi non elimina la necessità di controllo umano, specialmente in sistemi critici o in codice legacy sensibile.
La riduzione del 38% delle allucinazioni è un passo avanti, ma non elimina il problema, che rimane strutturale ai modelli generativi.
Sul fronte dei contesti lunghi e della visione artificiale, le capacità ampliate permettono nuove applicazioni, ma introducono anche rischi legati a un’eccessiva fiducia dell’utente nei risultati generati, soprattutto quando si analizzano documenti complessi o dati visivi interpretativi. L’adozione aziendale è promettente, ma basata su casi controllati e non ancora rappresentativa di un impatto sistemico.
In sintesi, GPT-5.2 è un modello più potente, più preciso e più utile, ma non privo di limiti: la sua efficacia dipenderà dalla capacità di integrarlo criticamente nei flussi di lavoro, mantenendo supervisione, trasparenza e consapevolezza dei rischi.
.






Partecipa alla community