
C’è un abbaglio ricorrente a ogni rivoluzione tecnologica: confondere il pennello con la tela, dimenticando il pittore. Oggi accade con la GenAI. Ne misuriamo la potenza, il numero di parametri, il “costo” e persino l’impatto ambientale (troppo poco, a dire il vero), ci stupiamo delle “magie” in conversazioni inaspettate. Ma una tela, senza pigmenti puri e armonizzati dall’artista, non diventa un capolavoro, per quanto il pennello sia raffinato.
In AI, i dati sono quei pigmenti: non basta che siano abbondanti, devono essere scelti, calibrati, significativi nel contesto. Senza questa cura, l’AI diventa un funambolo eloquente: spettacolare, ma poco affidabile.
La ricerca lo conferma. Studi come LIMA dimostrano che dataset relativamente piccoli ma curati possono produrre risultati migliori di insiemi enormi ma disordinati: il tuning funziona quando la qualità guida la selezione, non quando si aumenta indiscriminatamente la quantità. Allo stesso modo, il progetto DOLMA mostra che la trasparenza nella costruzione dei dataset e la tracciabilità delle trasformazioni sono essenziali per la riproducibilità e la robustezza dei modelli.
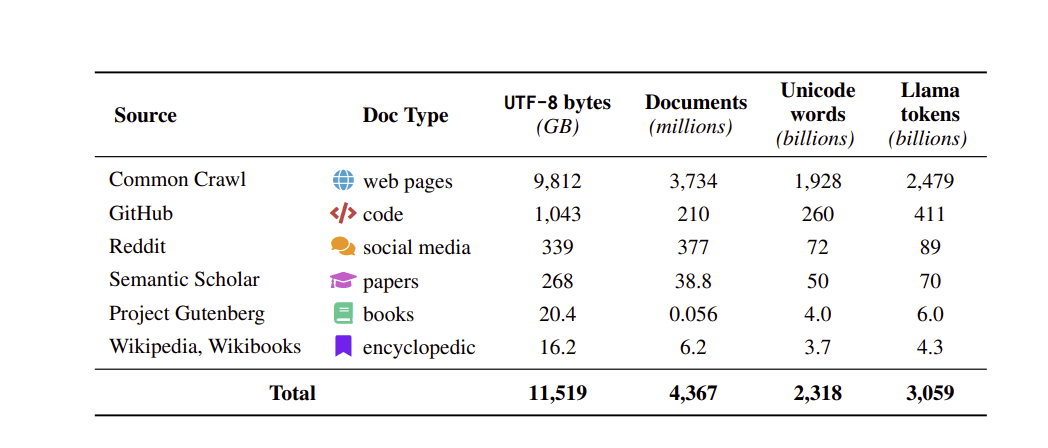
provenienti da circa 200 TB di testo grezzo prima della curatela fino a un dataset di 11 TB. È stato ampiamente
pulito per l’uso nel pre-addestramento del modello linguistico. Token calcolati utilizzando il tokenizzatore LLaMA.
È una lezione semplice e radicale: prima di tutto, curate i dati.
Questo implica conseguenze importanti: costruire dataset di qualità richiede tempo, competenze e impegno cognitivo. È costoso e non scala facilmente, ma è l’unico modo per addestrare un’AI davvero affidabile. E non si esaurisce alla prima iterazione: è un processo continuativo.
Serve impegno umano per addestrare una valida intelligenza artificiale.
Indice degli argomenti:
Nei contesti verticali la sfida raddoppia
Sanità, finanza, manifattura, moda, pubblica amministrazione: qui la differenza non la fa la tecnologia in sé, ma l’aderenza semantica tra dato e processo, la specializzazione dell’istanza. È la matematica dell’appropriatezza: non esiste accuratezza senza adeguatezza allo scopo (fitness for use: un dato è di qualità se è utile per l’uso previsto: non basta che sia corretto, deve essere completo, aggiornato, coerente e accessibile per il contesto in cui verrà applicato).
Costruire sistemi affidabili significa anche garantire tracciabilità: sapere da dove provengono i dati e i modelli, quali trasformazioni hanno subito, chi li ha modificati e dove/come vengono utilizzati (data e model lineage è il termine che descrive questo percorso: origine, trasformazioni, utilizzi. È la base per audit, compliance e riproducibilità).
Senza queste pratiche, anche il modello più sofisticato rischia l’allucinazione sistematica: non un bug, ma un difetto di fabbricazione, sistemico.
Gli interventi a valle, come le misure di sicurezza post-addestramento, possono mitigare solo in parte il problema: la vera soluzione è a monte.
La morale? Bias e buchi di rappresentatività nel dato non sono astrazioni: diventano rischi reali. Per questo la qualità dei dati – accuratezza, copertura dei casi limite, rappresentatività, licenze e consenso – è un requisito di sicurezza tanto quanto la robustezza del modello.
Oltre il mito del modello, la scelta strategica
Focalizzarsi sull’ultimo modello pubblicato – come se l’upgrade di architettura fosse la panacea – diventa un diversivo: sposta l’attenzione dal capitale informativo (dati, conoscenza, processi) a un artefatto sostituibile, dal contenuto al contenitore.
Il dato non è “buono” per definizione: lo si deve coltivare, curare. Come una vigna in montagna: attenzione quotidiana, esperienza del contesto, semantica dell’esperienza. Questo è necessario per trasformare dati in valore, attraversando le epoche tecnologiche.
In un mercato che premia la novità, scegliere la qualità dei dati è un atto competitivo. Nel nostro ecosistema, il Co‑Innovation Lab CANDI (Cooperative Ai & Next generation Data Interoperability) sviluppa e promuove una piattaforma in cui la lineage, il concetto di “genealogia” digitale, è il cuore dell’architettura.
Dati e Modelli diventano prodotti digitali che sono caratterizzati da catalogazione, versioning e monitoraggio end‑to‑end nell’intero ciclo di vita. Questo abilita una gestione più responsabile e trasparente dei dati e dei modelli.
Perché è decisivo? Perché solo con lineage verificabile e metriche di qualità possiamo:
- diagnosticare dove nasce un errore;
- spiegare perché una previsione cambia;
- dimostrare che i dati sono leciti e adeguati allo scopo;
- migliorare continuamente rappresentatività e fairness nei domini sensibili.
La domanda non è (solo) quale modello usare, ma quali dati siamo disposti a coltivare.
La potenza della GenAI non si nega: si realizza quando incontra basi informative solide, curate, pertinenti. Il resto è scenografia. O, per dirla con Borges, “un labirinto di simboli” in cui è facile perdersi.
L’uscita non è un modello più grande: è una mappa migliore, costruita con dati di qualità.
Riferimenti
Zhou et al., LIMA: Less Is More for Alignment (NeurIPS 2023) → https://arxiv.org/abs/2305.11206
Soldaini et al., Dolma: An Open Corpus of Three Trillion Tokens for Language Model Pretraining Research (ACL 2024)
Gu et al., Investigating the Impact of Data Selection Strategies on Language Model Performance (arXiv 2025) → https://arxiv.org/abs/2501.03826



