
NVLM 1.0 è una famiglia di modelli linguistici multimodali di Nvidia, progettati per diventare testa di serie sia in compiti di visione-linguaggio che in attività puramente testuali. Questo rilascio rappresenta un epocale passo avanti nell’ambito dell’intelligenza artificiale open-source (tecnologie di AI in cui il codice sorgente è liberamente disponibile per chiunque per l’uso, la modifica e la distribuzione), offrendo prestazioni competitive rispetto ai modelli proprietari di altre aziende leader di settore.

Del resto, il Ceo di Nvidia ha lanciato un messaggio forte qualche tempo fa: “Abbiamo creato un’intelligenza artificiale che comprende il mondo reale” che traccia una linea retta e decisa su ogni singolo sviluppo dell’AI.
I modelli linguistici progettati da Nvidia “imparano nozioni che i modelli attuali non comprendono”. Questa è l’essenza della vera sfida che Nvidia porta sul mercato mondiale.

Indice degli argomenti:
Cos’è NVLM 1.0 di Nvidia
NVLM, acronimo di Nvidia Vision Language Model, è una suite di modelli linguistici multimodali (MLLM) sviluppati interamente in house da Nvidia. Questi modelli sono progettati per gestire e processare simultaneamente dati testuali e visivi, consentendo una comprensione e generazione avanzata di contenuti multimodali.
La versione 1.0 di NVLM rappresenta la prima iterazione di questa famiglia, mirata a fornire prestazioni di alto livello in compiti che richiedono una profonda comprensione sia del testo che delle immagini
Come viene addestrato NVLM 1.0: un approccio a due fasi, qualità e ragionamento
L’addestramento di NVLM 1.0 non si basa semplicemente sull’accumulare enormi quantità di dati, ma su una strategia mirata, articolata in due fasi distinte ma sinergiche, con un obiettivo chiaro: rendere il modello capace di comprendere e ragionare, non solo generare testo o descrivere immagini.
Pre-addestramento (Pre-training): “meglio la qualità che la quantità”
In questa fase, NVLM viene esposto a dataset multimodali attentamente selezionati, cioè contenenti testo e immagini combinate, progettati non per dimensione, ma per diversità semantica e profondità dei compiti. Invece di usare grandi volumi di dati generici (come immagini casuali da internet), NVIDIA ha optato per fonti che:
- Presentano relazioni complesse tra testo e immagine (es. tabelle descritte a parole, grafici commentati, diagrammi tecnici);
- Coprono ambiti diversi: dalla medicina alla matematica, dalla geografia al design industriale;
- Sono puliti, consistenti e strutturati, riducendo il rumore e migliorando l’apprendimento.
L’ultimo punto è l’essenza reale della struttura del modello poiché abbatta di gran lunga la percentuale di allucinazioni in fase di elaborazione.
L’obiettivo è quello di creare un modello che sappia costruire connessioni profonde tra linguaggio e visione, sviluppando le basi per ragionamenti complessi.
Fine-tuning supervisionato (SFT – Supervised Fine-Tuning): “il momento in cui il modello impara a pensare”
Questa seconda fase serve a rifinire e specializzare le capacità già apprese. Qui, NVLM viene addestrato con:
- Dataset testuali di alta qualità: per migliorare le sue capacità linguistiche, di comprensione semantica, coerenza logica e generazione testuale fluida;
- Dataset multimodali focalizzati su compiti complessi, in particolare:
- Matematica visuale (es. problemi con immagini, geometria, equazioni inserite in diagrammi);
- Ragionamento multimodale (es. spiegare un grafico in base a una legenda o analizzare una scena per rispondere a una domanda).
In pratica, il modello non solo apprende a vedere e leggere, ma a dedurre, spiegare, confrontare e ragionare.
Ci avviciniamo sempre più a un’AI che ha gli stessi comportamenti di pensiero di un umano.
NVLM 1.0: cosa può fare, capacità e applicazioni
NVLM 1.0 è progettato per affrontare una vasta gamma di compiti multimodali e testuali, tra cui:
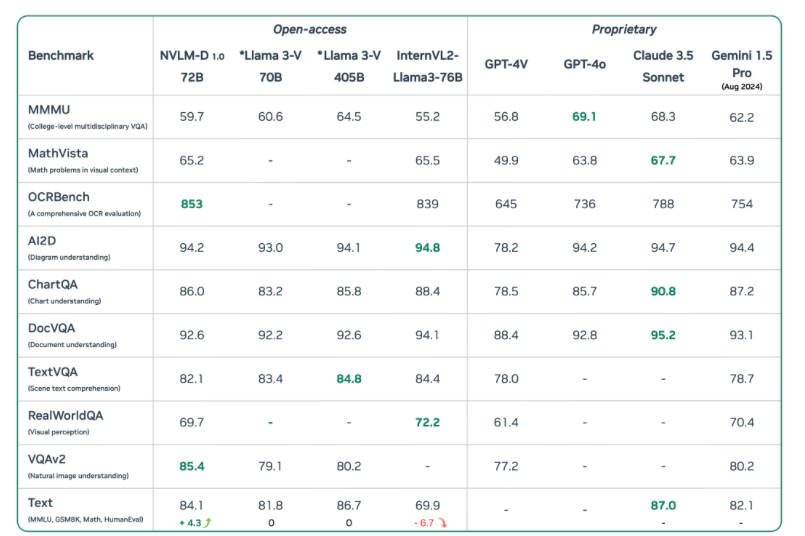
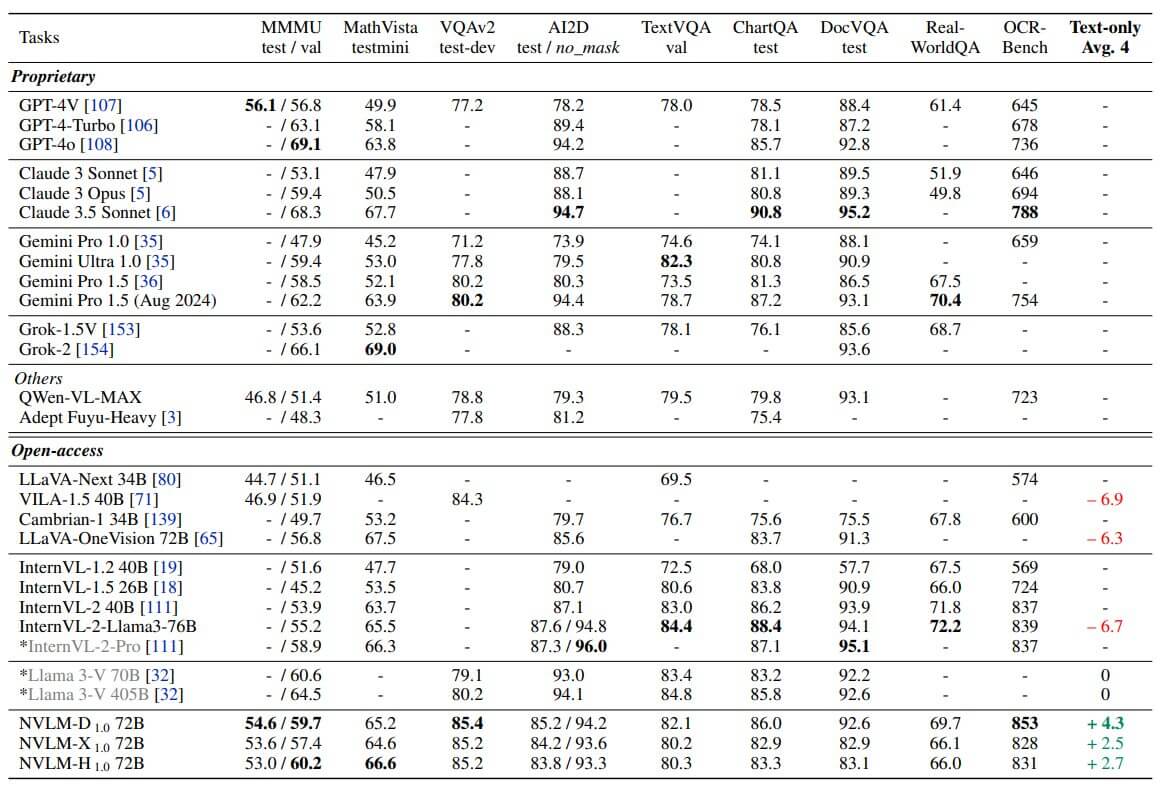
- OCR (Riconoscimento Ottico dei Caratteri): eccelle nel riconoscimento di testo in immagini, superando modelli concorrenti su benchmark come OCR Bench.
- Ragionamento multimodale: capacità avanzate di interpretare e ragionare su dati visivi e testuali combinati, come l’analisi di grafici e tabelle.
- Localizzazione e comprensione visiva: identificazione precisa di oggetti e interpretazione di scenari visivi complessi.
- Ragionamento logico e conoscenza del mondo: efficace nell’applicazione di conoscenze generali e nel ragionamento logico su informazioni testuali e visive.
NVLM 1.0, alcuni esempi di utilizzo
1. Esempio
Un’azienda riceve quotidianamente centinaia di documenti scannerizzati: fatture, contratti, ricevute fiscali e rapporti tecnici. Questi documenti spesso includono testi in piccoli font, tabelle, loghi, timbri e firme, rendendo difficile l’estrazione accurata delle informazioni con soluzioni OCR tradizionali.
Soluzione con NVLM 1.0
Grazie alla capacità multimodale avanzata di NVLM 1.0 e al suo sistema di “tile-tagging 1D” per immagini ad alta risoluzione, è possibile:
- Caricare il documento come immagine (ad esempio un PDF scannerizzato).
- NVLM analizza l’immagine, riconosce il testo anche se è ruotato, offuscato o distribuito su più colonne.
- L’output è un testo strutturato, pronto per essere:
- inserito in un gestionale ERP;
- utilizzato per il monitoraggio dei costi o per il data entry automatico;
- archiviato digitalmente con tag semantici (es. “Fattura fornitore Q3 2025”).
Plus rispetto ai modelli precedenti:
- Riconosce meglio i caratteri speciali (es. simboli matematici, formule, valute).
- Integra anche un primo livello di comprensione semantica: ad esempio, può etichettare automaticamente “importo da pagare”, “data di scadenza”, “numero fattura”, ecc
2. Esempio
- Un CFO di una piccola azienda vuole un’analisi automatica dei KPI mensili, generati in PDF da un software gestionale con grafici e tabelle.
Con NVLM 1.0:
- Il CFO carica il documento PDF.
- Fa una domanda del tipo:
“Perché il profitto netto è sceso rispetto a febbraio?” - NVLM confronta i grafici delle vendite, le voci di spesa e il testo esplicativo nel documento.
- Risponde in linguaggio naturale, evidenziando la correlazione tra spese marketing aumentate e ricavi stabili.
Vantaggi distintivi rispetto ai modelli precedenti
NVLM 1.0 risponde con spiegazioni ragionate, non solo riassunti.
Non si limita a leggere i dati: li collega e li interpreta.
Riconosce pattern visivi e semantici (es. crescita lenta, fluttuazioni, outlier).



