Mentre la maggior parte delle aziende AI è impegnata in una corsa verso il gradino più alto e tratta le altre aziende come rivali, OpenAI e Anthropic hanno reso noto di aver concordato di valutare l’allineamento dei sistemi pubblicamente disponibili dell’altro e di averne condiviso i risultati. I report completi sono molto tecnici, ma fondamentali per chi segue da vicino lo sviluppo dell’AI.
scenari
OpenAI e Anthropic testano a vicenda la sicurezza dei loro modelli AI. Ecco i risultati completi
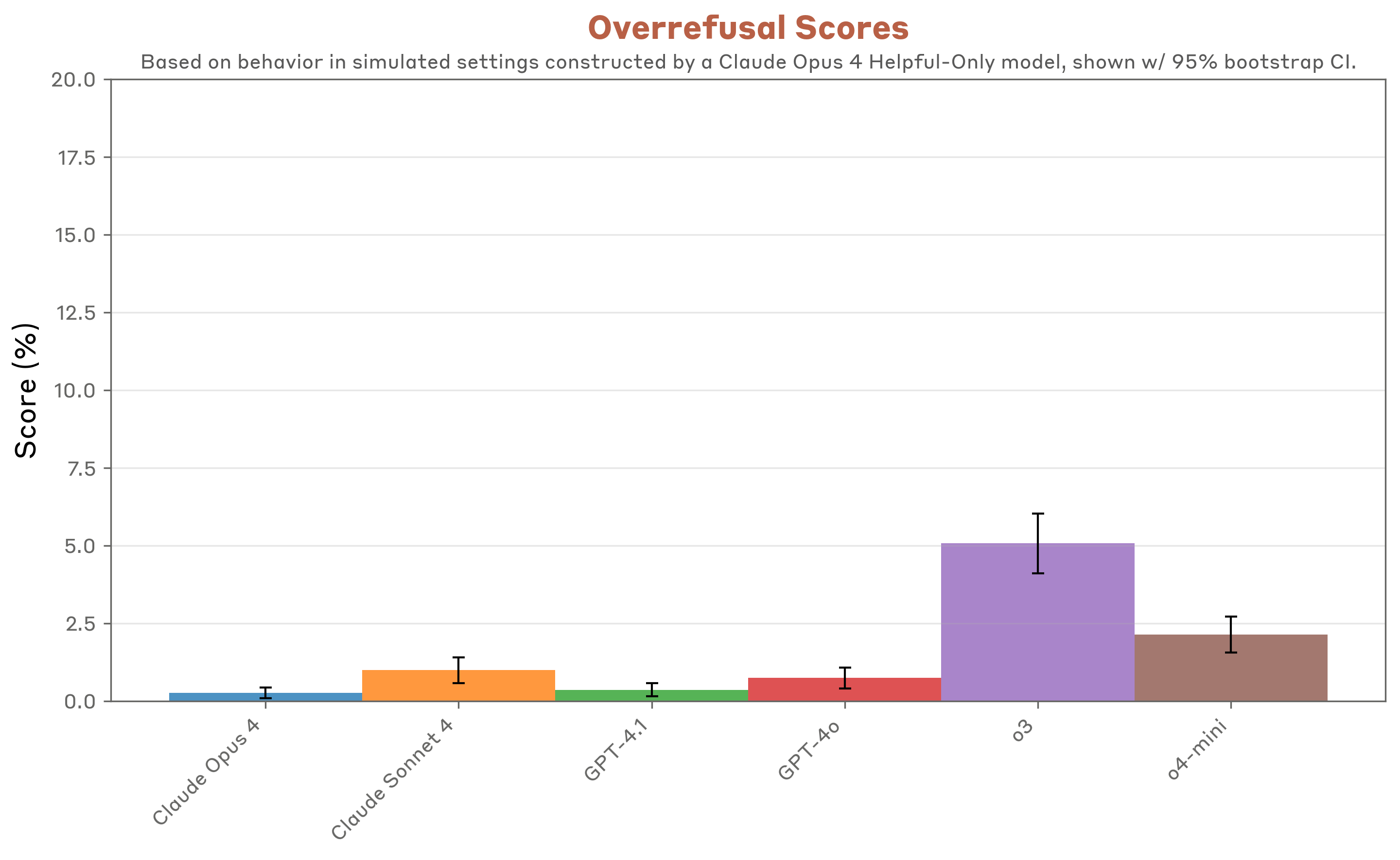
Le due aziende hanno condotto valutazioni incrociate sui rispettivi modelli AI, scoprendo aree critiche di sicurezza e rischi di uso improprio. Una collaborazione rara tra competitor, ma indispensabile per innalzare gli standard di sicurezza nel settore. La sfida non è solo evitare le allucinazioni, ma assicurarsi che l’AI resti trasparente e affidabile, anche quando il contesto diventa ostile
Pubblicato il 29 ago 2025
@RIPRODUZIONE RISERVATA


Pierluigi Sandonnini
Senior web editor di Nextwork360. Oltre trent’anni di esperienza giornalistica, maturata in diversi settori della tecnologia: audio video, tv digitale, telecomunicazioni, internet, intelligenza artificiale.
Dal 2020 gestisce il sito Ai4business.it, coordinando la redazione, curandone i contenuti e scrivendo articoli.