Contrariamente all’idea diffusa, secondo cui l’intelligenza artificiale potenzierebbe le performance degli sviluppatori, una nuova ricerca mostra un risultato inaspettato: l’AI rallenta i programmatori esperti quando lavorano su codice che conoscono già. Lo studio, condotto da METR – un’organizzazione no-profit che si occupa di ricerca sull’intelligenza artificiale – ha osservato un gruppo di sviluppatori esperti mentre utilizzavano Cursor, un noto assistente AI per la programmazione, su progetti open-source familiari.
Indice degli argomenti:
Le aspettative disattese: dai -24% ai +19%
Prima di iniziare lo studio, i partecipanti – tutti sviluppatori con esperienza – si aspettavano che l’utilizzo di Cursor avrebbe velocizzato il completamento dei task del 24%. Dopo averli eseguiti, continuavano a credere che l’AI li avesse aiutati a ridurre i tempi del 20%. Tuttavia, i dati dimostrano il contrario: i tempi di completamento sono aumentati del 19%. I due autori principali della ricerca, Joel Becker e Nate Rush, hanno dichiarato di essere rimasti sorpresi. Rush, addirittura, aveva previsto un raddoppio della velocità.
Correggere l’AI: il vero collo di bottiglia
La causa del rallentamento risiederebbe nel tempo necessario per correggere i suggerimenti dell’intelligenza artificiale. “Quando abbiamo rivisto i video, abbiamo visto che l’AI proponeva soluzioni spesso corrette nella direzione generale, ma raramente esatte rispetto a quanto richiesto,” ha spiegato Becker. In sostanza, gli sviluppatori hanno dovuto spendere tempo a rivedere, aggiustare o riscrivere codice generato automaticamente.
AI e sviluppatori: esperienza e conoscenza pregressa, una zavorra?
Lo studio evidenzia che questo effetto negativo riguarda in particolare gli sviluppatori già esperti e profondi conoscitori delle specificità di un progetto. In contesti diversi – come per sviluppatori junior o per chi lavora su un nuovo codicebase – gli strumenti AI potrebbero invece rivelarsi più utili. Questo dato entra in contraddizione con numerose ricerche precedenti, che evidenziano miglioramenti di produttività, come un’accelerazione del 56% in un caso, o il completamento del 26% di task in più in un altro.
L’impatto sul futuro del lavoro
I risultati di METR mettono in discussione una delle narrative chiave dell’adozione dell’AI: quella secondo cui l’intelligenza artificiale renderà gli ingegneri software più produttivi, giustificando così gli ingenti investimenti nelle piattaforme di assistenza alla programmazione. Non solo: pongono interrogativi anche sull’idea che l’AI sia pronta a sostituire i ruoli di coding entry-level. Proprio su questo punto, Dario Amodei – CEO di Anthropic – ha recentemente dichiarato che la metà dei lavori impiegatizi junior potrebbe scomparire nei prossimi cinque anni a causa dell’automazione.
Una questione di esperienza utente, non di velocità
Nonostante i risultati dello studio, sia gli autori che la maggior parte dei partecipanti continuano a usare Cursor. Perché? Non per efficienza, ma perché l’esperienza di sviluppo risulta più piacevole. “È come modificare un saggio invece di partire da una pagina bianca,” ha detto Becker. In altre parole, per molti sviluppatori l’obiettivo non è necessariamente terminare un compito il più velocemente possibile, ma rendere il processo meno faticoso e più stimolante.
Lo studio: misurare l’impatto dell’AI sulla produttività degli sviluppatori open source esperti
METR ha condotto uno studio randomizzato controllato (RCT) per capire in che modo gli strumenti di AI dei primi anni del 2025 influenzano la produttività degli sviluppatori open source esperti che lavorano sui propri repository. Sorprendentemente, ha scoperto che quando gli sviluppatori utilizzano strumenti di AI, impiegano il 19% di tempo in più rispetto a quando non li utilizzano: l’AI li rende più lenti. Consideriamo questo risultato come un’istantanea delle capacità dell’AI all’inizio del 2025 in un contesto rilevante; poiché questi sistemi continuano a evolversi rapidamente, intendiamo continuare a utilizzare questa metodologia per aiutare a stimare l’accelerazione dell’AI derivante dall’automazione della ricerca e sviluppo nell’ambito dell’AI.

Le motivazioni dello studio
Sebbene i benchmark di codifica/agenti si siano dimostrati utili per comprendere le capacità dell’AI, in genere sacrificano il realismo a favore della scala e dell’efficienza: i compiti sono autonomi, non richiedono un contesto precedente per essere compresi e utilizzano una valutazione algoritmica che non cattura molte capacità importanti. Queste proprietà possono portare i benchmark a sovrastimare le capacità dell’AI. D’altra parte, poiché i benchmark vengono eseguiti senza l’interazione umana dal vivo, i modelli potrebbero non riuscire a completare i compiti nonostante i progressi sostanziali, a causa di piccoli colli di bottiglia che un essere umano risolverebbe durante l’uso reale. Ciò potrebbe indurci a sottovalutare le capacità del modello. In generale, può essere difficile tradurre direttamente i punteggi dei benchmark in impatto nel mondo reale.
Uno dei motivi per cui siamo interessati a valutare l’impatto dell’AI nel mondo reale è quello di comprendere meglio l’impatto dell’AI sulla ricerca e sviluppo dell’AI stessa, che può comportare rischi significativi. Ad esempio, un progresso estremamente rapido dell’AI potrebbe portare a interruzioni nella supervisione o nelle misure di sicurezza. Misurare l’impatto dell’AI sulla produttività degli sviluppatori di software fornisce prove complementari ai benchmark che sono informative sull’impatto complessivo dell’AI sull’accelerazione della ricerca e sviluppo dell’AI.
Metodologia
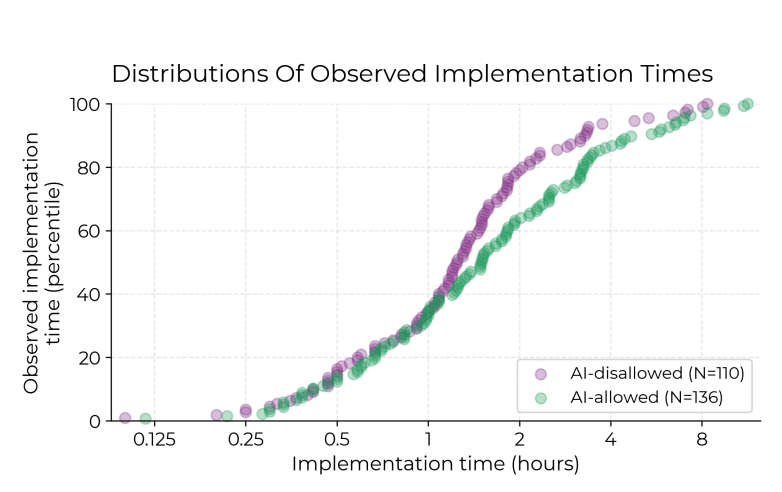
Per misurare direttamente l’impatto reale degli strumenti di AI sullo sviluppo di software, METR ha reclutato 16 sviluppatori esperti provenienti da grandi repository open source (con una media di oltre 22.000 stelle e oltre 1 milione di righe di codice) a cui hanno contribuito per diversi anni. Gli sviluppatori forniscono elenchi di problemi reali (246 in totale) che sarebbero preziosi per il repository: correzioni di bug, funzionalità e rifattorizzazioni che normalmente farebbero parte del loro lavoro regolare. Quindi, ha assegnato in modo casuale a ciascun problema l’autorizzazione o il divieto di utilizzare l’AI durante il lavoro sul problema. Quando l’AI è consentita, gli sviluppatori possono utilizzare qualsiasi strumento scelgano (principalmente Cursor Pro con Claude 3.5/3.7 Sonnet, modelli all’avanguardia al momento dello studio); quando non è consentita, lavorano senza l’assistenza dell’AI generativa. Gli sviluppatori completano questi compiti (che richiedono in media 2 ore ciascuno) registrando i loro schermi, quindi riportano autonomamente il tempo totale di implementazione necessario.

AI e sviluppatori esperti: i principali risultati
Quando agli sviluppatori è consentito utilizzare strumenti di AI, impiegano il 19% di tempo in più per completare i problemi: un rallentamento significativo che contraddice le convinzioni degli sviluppatori e le previsioni degli esperti. Questo divario tra percezione e realtà è sorprendente: gli sviluppatori si aspettavano che l’AI li rendesse più veloci del 24% e, anche dopo aver sperimentato il rallentamento, continuavano a credere che l’AI li avesse resi più veloci del 20%.
Di seguito mostriamo i tempi medi previsti dagli sviluppatori e i tempi di implementazione osservati: possiamo vedere chiaramente che gli sviluppatori impiegano molto più tempo quando è loro consentito utilizzare strumenti di AI.

Dato l’importante bisogno di comprendere le capacità e i rischi dell’IA, e la diversità di prospettive su questi temi, si ritiene fondamentale prevenire potenziali malintesi o generalizzazioni eccessive dei risultati. Nella Tabella sono elencate le affermazioni per le quali non vengono fornite evidenze.
| Non si forniscono evidenze che: | Chiarimento |
|---|---|
| I sistemi di IA attualmente non accelerano molti o la maggior parte degli sviluppatori software | Non si afferma che gli sviluppatori o i repository analizzati rappresentino la maggioranza o la pluralità del lavoro di sviluppo software |
| I sistemi di IA non accelerano individui o gruppi in ambiti diversi dallo sviluppo software | Si studia esclusivamente lo sviluppo software |
| I sistemi di IA nel prossimo futuro non accelereranno gli sviluppatori nel preciso contesto esaminato | I progressi sono difficili da prevedere, e negli ultimi cinque anni c’è stato un notevole progresso nell’IA [3] |
| Non esistono modalità per utilizzare i sistemi di IA esistenti in modo più efficace per ottenere un’accelerazione positiva nel preciso contesto esaminato | Cursor non campiona molti token da LLM, potrebbe non usare la richiesta/struttura ottimale, e l’addestramento/fine-tuning/learning a pochi colpi specifico per dominio/repository potrebbe portare a un’accelerazione positiva |
Analisi dei fattori
Sono stati esaminati 20 fattori potenziali che potrebbero spiegare il rallentamento, trovando evidenza che 5 di essi probabilmente contribuiscono:

Escludiamo molti artefatti sperimentali: gli sviluppatori hanno utilizzato modelli all’avanguardia, hanno rispettato l’assegnazione del trattamento, non hanno eliminato differenzialmente le problematiche (ad esempio, eliminando problemi vietati dall’AI, riducendo la difficoltà media dei problemi vietati dall’AI) e hanno inviato pull request di qualità simile con e senza AI. Il rallentamento persiste attraverso diverse misure di risultato, metodologie di stima e molti altri sottoinsiemi/analisi dei nostri dati. Per ulteriori dettagli e analisi, si rimanda al documento.
Le capacità degli agenti AI
Come possiamo conciliare questi risultati con i punteggi impressionanti nei benchmark dell’AI e i report aneddotici sull’utilità dell’AI e sull’adozione diffusa degli strumenti di AI? Nel complesso, le evidenze di queste fonti danno risposte parzialmente contraddittorie riguardo alle capacità degli agenti AI nel compiere utilmente compiti o accelerare gli esseri umani.
La tabella seguente scompone queste fonti di evidenza e riassume lo stato delle evidenze provenienti da queste fonti. Va notato che non si intende che sia esaustiva: l’intento è di fare riferimento, in modo molto approssimativo, ad alcune differenze salienti e importanti.
| RCT | Benchmark come SWE-Bench Verified, RE-Bench | Aneddoti e adozione diffusa dell’AI | |
|---|---|---|---|
| Tipo di compito | Pull request da grandi e di alta qualità codebase open-source | SWE-Bench Verified: PR open-source con test scritti dagli autori, RE-Bench: problemi di ricerca IA artigianali con metriche algoritmiche di scoring | Diversi |
| Definizione di successo del compito | L’utente umano è soddisfatto che il codice supererà la revisione – incluse le richieste di stile, test e documentazione | Scoring algoritmico (ad esempio, casi di test automatizzati) | L’utente umano trova il codice utile (potenzialmente come prototipo temporaneo o codice di ricerca usa-e-getta) |
| Tipo di IA | Chat, modalità agente Cursor, completamento automatico | Tipicamente agenti completamente autonomi, che possono campionare milioni di token, usare strutture complicate per gli agenti, ecc. | Modelli e strumenti vari |
| Osservazioni | I modelli rallentano gli esseri umani su compiti realistici di codifica di 20 minuti – 4 ore | I modelli spesso hanno successo nei compiti di benchmark che sono molto difficili per gli esseri umani | Molte persone (anche se certamente non tutte) riferiscono di trovare l’IA molto utile per compiti software significativi che richiedono più di 1 ora, in un ampio ventaglio di applicazioni. |
Conciliando queste diverse fonti di evidenza è difficile ma importante, e dipende in parte dalla domanda che si cerca di rispondere. In una certa misura, le diverse fonti rappresentano sotto-domande legittime sulle capacità dei modelli: ad esempio, siamo interessati a comprendere le capacità dei modelli sia dato un massimo di elicitation (ad esempio, campionando milioni di token o decine/centinaia di tentativi/percorso per ogni problema) che dato un uso standard/comune. Tuttavia, alcune proprietà possono rendere i risultati non validi per le domande più importanti sull’utilità nel mondo reale, come nel caso dei self-report, che potrebbero essere inaccurati o eccessivamente ottimisti.
Ecco alcune delle ampie categorie di ipotesi su come queste osservazioni potrebbero essere conciliabili, che ci sembrano più plausibili (questa è un modello mentale molto semplificato):
Sommario dei risultati osservati
L’IA rallenta gli sviluppatori esperti di open-source nel nostro RCT, ma dimostra punteggi impressionanti nei benchmark e aneddoticamente è ampiamente utile.
Diagramma
Ipotesi 1: RCT sottovaluta le capacità
I risultati dei benchmark e gli aneddoti sono fondamentalmente corretti, e c’è qualche problema metodologico sconosciuto o proprietà del nostro contesto che sono diverse rispetto ad altri contesti importanti.
Ipotesi 2: I benchmark e gli aneddoti sovrastimano le capacità
I risultati del nostro RCT sono fondamentalmente corretti, e i punteggi dei benchmark e i report aneddotici sono sovrastimati sulle capacità del modello (probabilmente per motivi diversi ciascuno).
Ipotesi 3: Evidenze complementari per contesti diversi
Tutti e tre i metodi sono fondamentalmente corretti, ma misurano sottoinsiemi della distribuzione “reale” dei compiti che sono più o meno difficili per i modelli.
Utilizzando questo framework, possiamo considerare le evidenze a favore e contro i vari modi per conciliare queste diverse fonti di evidenza.
Ad esempio, i risultati dell’RCT sono meno rilevanti in contesti in cui è possibile campionare centinaia o migliaia di traiettorie dai modelli, cosa che gli sviluppatori tipicamente non provano. Potrebbe anche essere che ci siano forti effetti di apprendimento per gli strumenti di AI come Cursor che si manifestano solo dopo diverse centinaia di ore di utilizzo – gli sviluppatori tipicamente utilizzano Cursor per poche decine di ore prima e durante lo studio. I risultati suggeriscono anche che le capacità dell’AI potrebbero essere relativamente più basse in contesti con standard di qualità molto elevati, o con molteplici requisiti impliciti (ad esempio, relativi a documentazione, copertura dei test, o linting/formattazione) che richiedono un tempo considerevole per essere appresi dagli esseri umani.
D’altra parte, i benchmark potrebbero sovrastimare le capacità del modello misurando solo la performance su compiti ben definiti e con metriche algoritmiche di scoring. E ora abbiamo forti evidenze che i report aneddotici/schiarimenti sugli aumenti di velocità possano essere molto inaccurati.
Nessun metodo di misurazione è perfetto – i compiti che le persone vogliono che i sistemi AI completino sono diversi, complessi e difficili da studiare in modo rigoroso. Ci sono scelte significative tra i metodi, e continuerà ad essere importante sviluppare e utilizzare metodologie di valutazione diverse per formare un quadro più completo dello stato attuale dell’AI e di dove stiamo andando.
Prospettive future
Se i sistemi AI saranno in grado di accelerare sostanzialmente gli sviluppatori nel nostro contesto, ciò potrebbe segnalare un’accelerazione rapida dei progressi nell’R&D dell’AI in generale, che potrebbe a sua volta portare a rischi di proliferazione, disfunzioni nelle protezioni e supervisione, o eccessiva centralizzazione del potere. Questa metodologia fornisce evidenze complementari ai benchmark, concentrandosi su scenari di implementazione realistici, che aiuta a comprendere in modo più completo le capacità e l’impatto dell’AI rispetto al basarsi esclusivamente su benchmark e dati aneddotici.
Conclusione: sfide e potenzialità dell’AI nella programmazione
Lo studio di METR sottolinea che non esiste un impatto unico dell’AI sul lavoro degli sviluppatori: dipende dal contesto, dall’esperienza e dal tipo di codice. Se da un lato l’AI può aiutare i meno esperti o chi lavora su nuovi progetti, dall’altro può complicare le cose per chi già conosce a fondo ciò su cui sta operando. Il futuro dell’AI nella programmazione, quindi, sarà probabilmente più sfumato – e meno lineare – di quanto finora immaginato.



