Nelle riunioni di pianificazione delle infrastrutture si sente spesso dire: “L’AI agentica cambierà il rapporto tra CPU e GPU. Quindi, sarà sufficiente aggiungere più CPU ai nostri server GPU, giusto?”.
Un ragionamento apparentemente logico. Ma è proprio qui che si annida l’errore.
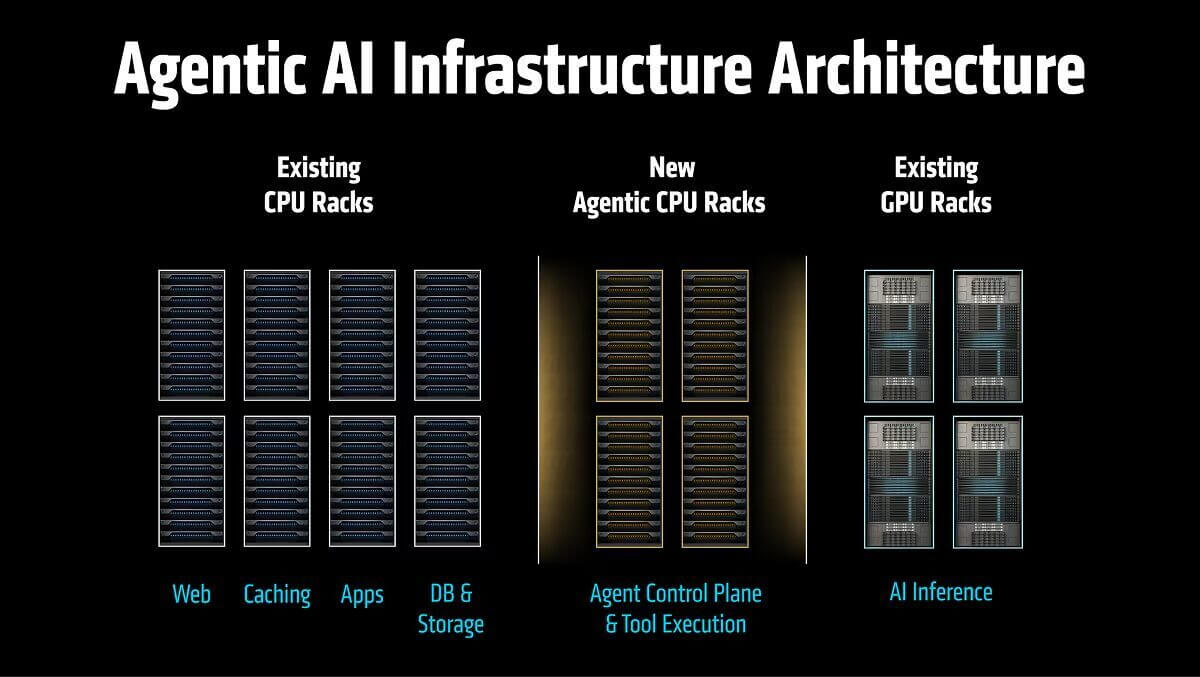
Il passaggio dall’AI conversazionale a quella agentica non si riduce all’inserimento di qualche processore nel rack delle GPU. La questione è ben più profonda: richiede un cambiamento strutturale nell’architettura dei data center. L’agentic AI riscrive completamente l’equazione dell’infrastruttura.
In AMD abbiamo seguito questa trasformazione con grande attenzione. Laddove in precedenza stimavamo una crescita annua del mercato delle CPU per server pari al 18%, l’aumento strutturale della domanda di capacità di calcolo – trainato dall’adozione degli agenti – ridisegna radicalmente le proiezioni. Oggi prevediamo che il mercato potenziale totale per le CPU per server crescerà a un tasso superiore al 35% annuo, superando i 120 miliardi di dollari entro il 2030.
Indice degli argomenti:
La prima ondata: l’AI conversazionale come sistema di risposta basato su modelli
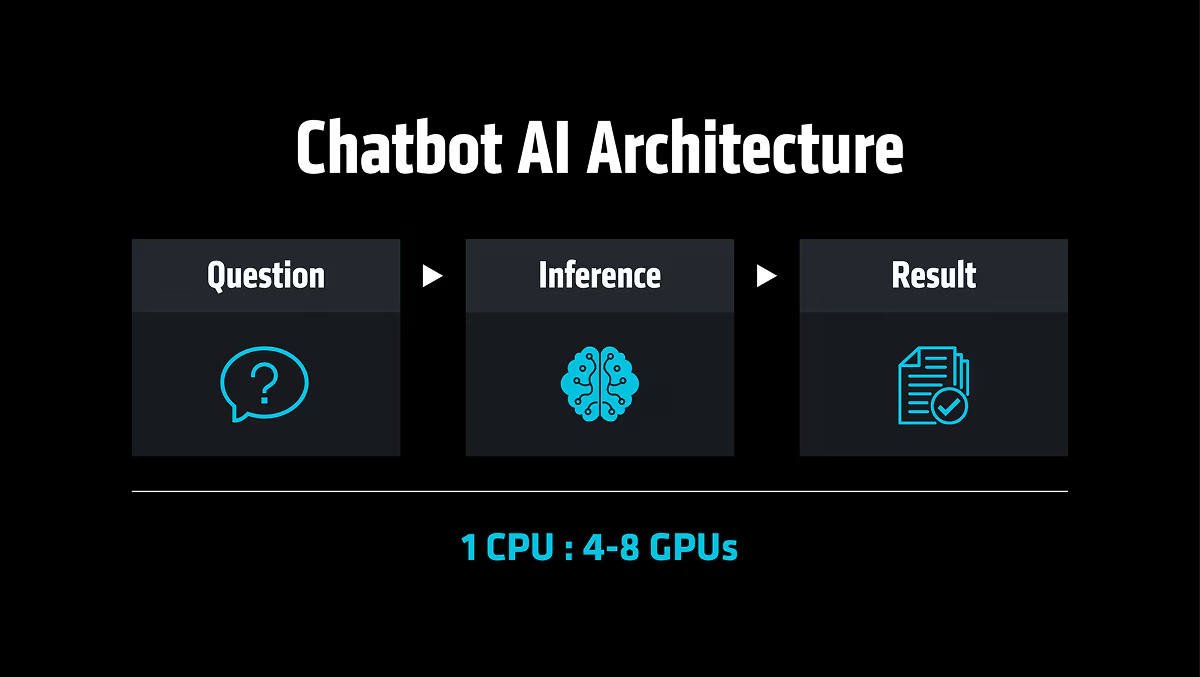
La prima ondata dell’AI generativa si fondava su uno schema relativamente semplice. L’utente formulava una domanda; l’applicazione inoltrava un prompt al modello; quest’ultimo generava una risposta e l’applicazione la restituiva.
Tale architettura ha orientato naturalmente i progetti verso un approccio incentrato sulle GPU. In tali implementazioni, una CPU svolgeva il ruolo di nodo principale all’interno di un server dotato di quattro-otto GPU: gestiva la pianificazione, l’I/O e l’amministrazione del sistema, lasciando alle GPU l’elaborazione dei carichi di calcolo più intensivi. Il carico di lavoro era essenzialmente model-centric: un ciclo definito, con un inizio, un’inferenza e una fine.
L’Agentic AI non è semplicemente “chat potenziata con strumenti”
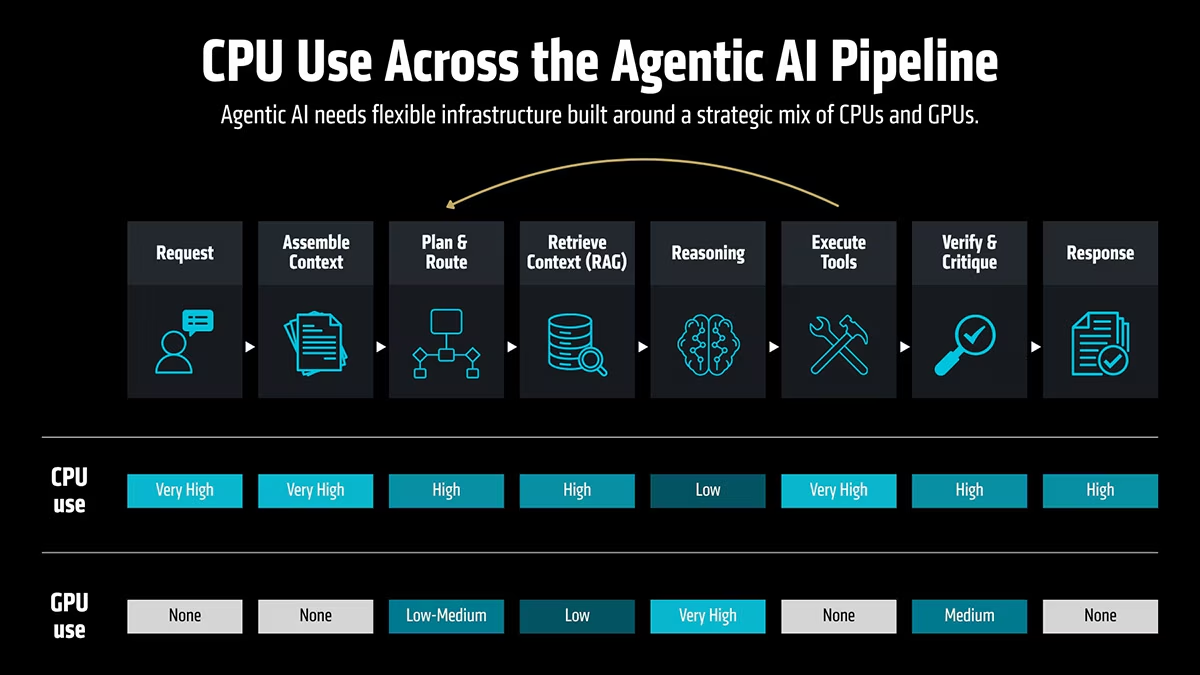
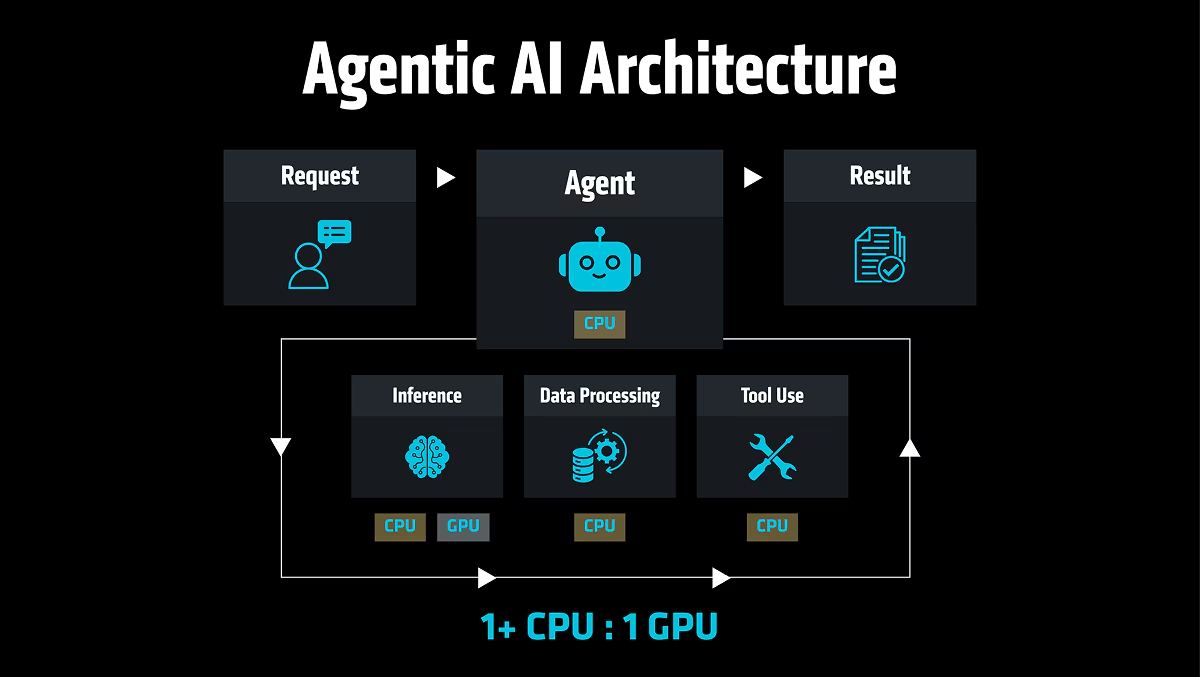
Siamo oggi agli albori dell’era dell’AI agentica. In questo nuovo paradigma, la natura stessa del carico di lavoro muta radicalmente. Anziché rispondere a un singolo prompt, un agente scompone un obiettivo in una sequenza di passi, valuta le azioni successive, richiama più modelli, interroga database, si interfaccia con API esterne, esegue applicazioni aziendali, verifica le autorizzazioni, recupera dati dalla memoria, convalida l’output e riavvia l’intero ciclo da capo. Si tratta di un profilo infrastrutturale profondamente diverso rispetto a quello dell’AI conversazionale, basata sul paradigma “prompt-in, answer-out”.
Tre funzioni critiche
Le GPU rimangono componenti fondamentali per l’inferenza dei modelli, ma il carico di lavoro in produzione è ora a elevata intensità di CPU. Queste ultime sono chiamate a gestire tre funzioni critiche.
- Orchestrazione: la CPU agisce da direttore d’orchestra, scomponendo l’obiettivo principale in task più granulari e assegnando ciascuno alla risorsa più adeguata. In termini concreti, questo significa decidere – in tempo reale, con logica condizionale – se una richiesta richiede l’inferenza su una GPU o un acceleratore, una query su un database vettoriale, l’invocazione di un microservizio o una combinazione di questi. In architetture multi-agente, dove più agenti operano in parallelo con obiettivi parzialmente sovrapposti, questa funzione si moltiplica: la CPU deve coordinare l’esecuzione concorrente, gestire le dipendenze tra task e risolvere i conflitti sulle risorse condivise, il tutto mantenendo la coerenza dell’obiettivo complessivo.
- Esecuzione degli agenti e chiamate agli strumenti: questo è il collegamento vitale tra l’agente AI e il tessuto dell’infrastruttura IT aziendale esistente. Attivare un’API REST, interfacciarsi con un sistema ERP per verificare la disponibilità di magazzino, interrogare un CRM per recuperare la storia di un cliente, invocare un’applicazione legacy o scrivere un record in un database relazionale: tutte queste operazioni ricadono sulla CPU. Ogni chiamata porta con sé la propria latenza, il proprio schema di dati e la propria logica di gestione degli errori; la CPU deve integrare i risultati eterogenei in un flusso coerente da passare al passo successivo del ragionamento dell’agente.
- Policy e sicurezza: ogni singola azione autonoma dell’agente – accedere a un documento riservato, inviare una comunicazione esterna, modificare un record in produzione – generalmente è sottoposta a controlli di conformità, autorizzazione e audit in tempo reale. Si tratta di un’attività di governance sequenziale e basata su regole, adatta all’architettura delle CPU, piuttosto che essere gestita in modo efficiente esclusivamente su architetture GPU altamente parallele in ambienti regolamentati.
La risposta al nuovo equilibrio non consiste semplicemente nell’aggiungere più CPU
A differenza del precedente rapporto CPU-GPU di 1:4-8 che caratterizzava l’AI conversazionale, quella agentica si sta orientando verso un rapporto di 1:1 e, in alcuni casi, verso una predominanza del lato CPU.
Il punto cruciale è questo: tale risultato non si raggiunge semplicemente affiancando ulteriori CPU a un sistema concepito attorno alle GPU. Lo si ottiene aggiungendo un livello di elaborazione CPU di nuova concezione, progettato specificamente per i carichi di lavoro agentici.
Per i responsabili IT aziendali, è proprio su questo fronte che la pianificazione deve evolvere. L’infrastruttura AI di riferimento per i prossimi anni non sarà un singolo sistema monolitico.
Assumerà piuttosto la forma di un ambiente distribuito:
- rack di GPU dedicati all’elaborazione ad alta densità dei modelli;
- rack di CPU agentiche deputati a orchestrazione,
- elaborazione dei dati ed esecuzione degli strumenti;
e, a collegare entrambi, un fabric di rete ad altissima capacità.
Quest’ultimo elemento merita una riflessione dedicata.
L’importanza di un’architettura bilanciata
In un’architettura distribuita, la latenza di rete tra i rack non è un dettaglio tecnico secondario: determina direttamente la reattività dell’agente. Un fabric insufficiente può generare colli di bottiglia che rendono meno performanti anche le GPU più potenti, poiché i tempi di trasferimento dei dati tra i livelli dell’architettura diventano il vero vincolo delle prestazioni. Tecnologie come InfiniBand o Ethernet ad alta velocità – 400 GbE e oltre – cessano di essere una voce accessoria nel budget infrastrutturale e diventano componenti di progettazione di primo livello, da pianificare insieme ai processori, non dopo.
Un’architettura distribuita e aperta porta con sé un ulteriore vantaggio strutturale. Un modello basato su standard condivisi ed ecosistemi aperti evita i blocchi tecnologici che storicamente rallentano l’adozione di soluzioni avanzate. Per i team di sviluppo, significa la libertà di adottare i framework più adatti al proprio caso d’uso – da LangChain ad AutoGen – senza essere vincolati a un singolo stack proprietario. Per le organizzazioni, si traduce in flessibilità strategica: la possibilità di combinare modelli open-weight con modelli commerciali, infrastruttura on-premise con cloud ibrido, e di far evolvere l’architettura man mano che il mercato matura, senza incorrere in costi di migrazione che penalizzano chi ha scommesso su un unico fornitore.
In questo scenario, un’architettura bilanciata diventa più determinante che mai. Se il livello della CPU è sottodimensionato, le GPU restano in attesa. Se la rete è trattata come elemento secondario, gli agenti si bloccano. Se il percorso dei dati non è ottimizzato, la latenza aumenta. Se il livello di orchestrazione non è progettato per gestire l’elaborazione concorrente, costi e complessità si moltiplicano.
La dimensione economica
C’è inoltre una dimensione economica che non può essere trascurata. Secondo una tendenza confermata da enti come l’Agenzia Internazionale dell’Energia (IEA), i data center per l’AI hanno un fabbisogno energetico dalle 4 alle 5 volte superiore a quelli tradizionali, e questo impatto si riflette direttamente sul Total Cost of Ownership (TCO). Un’infrastruttura sbilanciata – dove, per esempio, le GPU rimangono in attesa per colpa di una CPU o di un fabric di rete sottodimensionati – non è solo computazionalmente inefficiente: consuma energia senza produrre risultati utili, aumentando il costo per inferenza e peggiorando il rendimento dell’investimento. Ottimizzare il bilanciamento tra CPU, GPU e rete significa, in termini concreti, massimizzare il TCO e migliorare la sostenibilità operativa del data center. In ambienti dove si parla di centinaia di rack, questa differenza ha un impatto direttamente misurabile sui bilanci aziendali.
Conclusione pratica per i responsabili IT
L’AI agentica sta riscrivendo l’equazione dell’infrastruttura.
Il nostro invito ai responsabili IT aziendali è questo: mentre l’AI agentica transita dalla fase pilota alla produzione, non dimensionate l’infrastruttura come se steste semplicemente integrando un chatbot nella vostra organizzazione. Dimensionatela come se steste introducendo una nuova categoria di forza lavoro digitale, capace di pianificare, agire, controllare, recuperare informazioni, richiamare strumenti ed eseguire flussi di lavoro in modo continuativo.
Ciò significa pianificare una capacità di CPU superiore rispetto a quanto suggerito dalle precedenti assunzioni sull’AI. Significa guardare oltre il server GPU e ragionare in termini di rack, fabric di rete, software ed equilibrio operativo complessivo – considerando TCO e sostenibilità energetica come metriche di performance di primo livello.
Nell’era dell’AI agentica, le prestazioni non deriveranno da un unico processore omnicomprensivo, ma dall’architettura corretta: quella in cui CPU e GPU collaborano in modo sinergico per portare l’AI dalle risposte all’azione.





Partecipa alla community