Il capitolo Technical Performance dell’AI Index 2026 di Stanford contiene una tensione che vale la pena guardare in faccia. Le prestazioni dei modelli crescono più velocemente degli strumenti costruiti per misurarle, i benchmark pensati per durare anni vengono saturati in mesi, il gap tra i modelli al vertice si è ridotto a pochi punti, e il divario Stati Uniti-Cina si è praticamente chiuso.
In parallelo, però, emergono problemi seri di affidabilità delle valutazioni stesse, fino al 42% di domande invalide su alcuni benchmark diffusi. Il risultato è un paradosso operativo: l’AI progredisce visibilmente, ma stiamo perdendo gli occhiali con cui guardarla.
Indice degli argomenti:
Humanity’s Last Exam: 30 punti in un anno, su un benchmark costruito per durare
Partiamo dal dato più secco. Humanity’s Last Exam, un benchmark progettato nel 2024 per essere “difficile per le AI e favorevole agli esperti umani”, ha visto i modelli di frontiera guadagnare 30 punti percentuali in un solo anno. Benchmark pensati per essere sfidanti per anni vengono saturati in pochi mesi, e la finestra di utilità scientifica di una valutazione si sta comprimendo drammaticamente.
L’implicazione operativa è che la domanda “questo modello è più bravo di quell’altro?” sta diventando meno informativa.
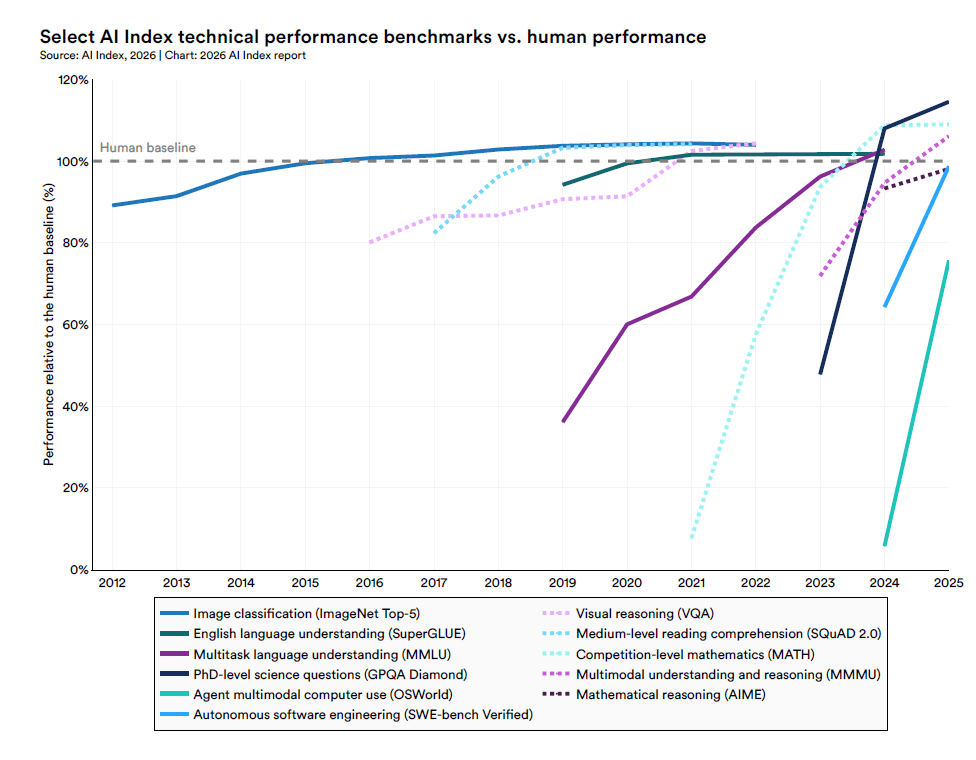
Su ImageNet, SuperGLUE, MMLU i frontier ormai superano la baseline umana. Su GPQA Diamond, MMMU, AIME la raggiungono o la sfiorano. Su SWE-bench Verified, agente software che risolve issue reali su GitHub, si è passati da circa il 60% a oltre il 77% in poco più di un anno. La curva di saturazione è così rapida che quando un benchmark diventa pubblico, il suo valore come discriminante è già in decadimento.
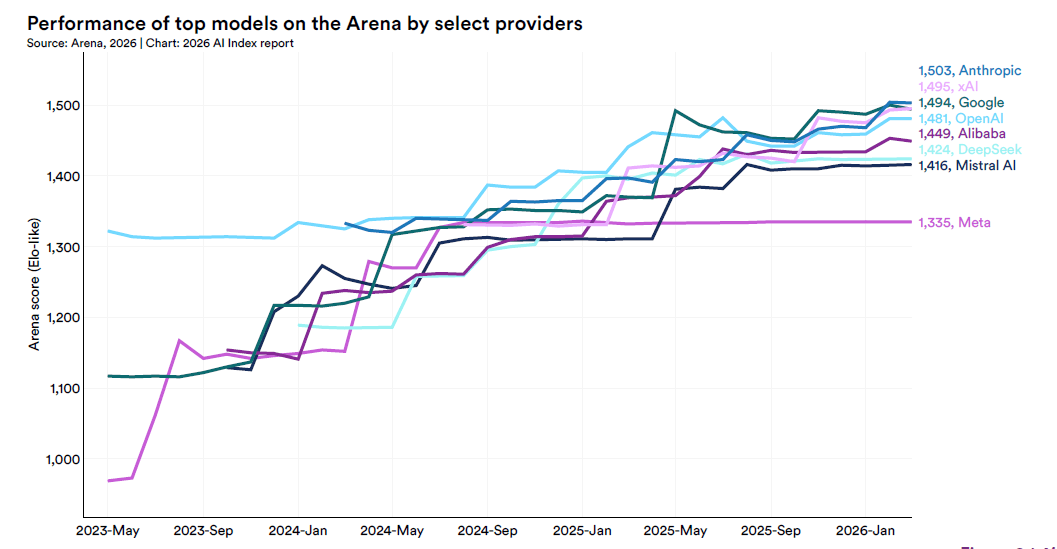
Quattro modelli dentro 25 punti Elo: la convergenza al vertice
A marzo 2026 l’Arena Leaderboard, il ranking basato su valutazioni umane in blind comparison, mostra un quadro che un anno fa sembrava impossibile.
Anthropic è a 1.503, xAI a 1.495, Google a 1.494, OpenAI a 1.481, Alibaba a 1.449, DeepSeek a 1.424. Sei modelli, quattro dentro 25 punti Elo, una banda di prestazione così stretta che singole scelte di addestramento o di tuning possono ribaltare l’ordinamento da una settimana all’altra.
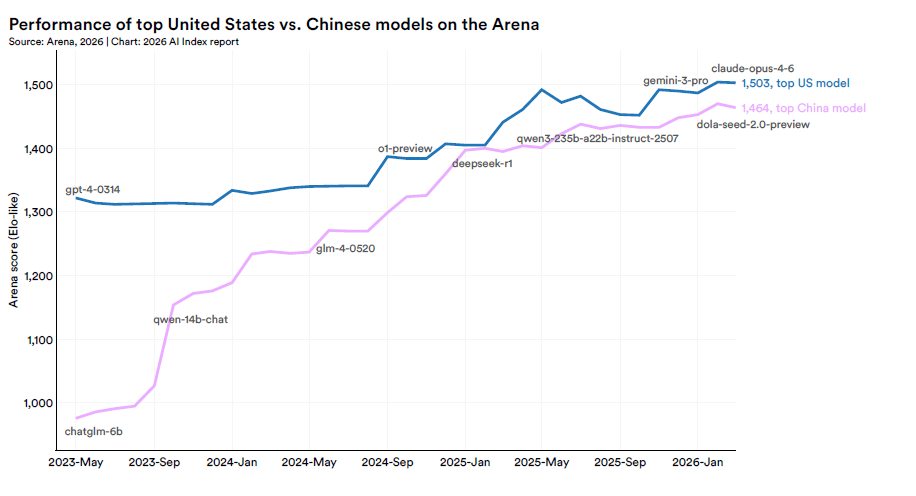
Fine del gap Usa-Cina
Il dato geopolitico più significativo è la chiusura del gap Stati Uniti-Cina. A febbraio 2025 DeepSeek-R1 ha brevemente pareggiato il top model statunitense, a marzo 2026 il miglior modello USA è avanti di appena il 2,7%. In dodici mesi, il divario ha oscillato ma è rimasto sempre a una cifra. La convergenza non è solo tecnica, è strutturale: quando le capacità smettono di essere il differenziatore principale, la pressione competitiva si sposta su costo, latenza, affidabilità e idoneità al caso d’uso specifico.
Per chi dentro un’organizzazione deve scegliere un fornitore di AI, questo ha un’implicazione pratica: la risposta alla domanda “qual è il modello migliore?” sta diventando sempre più dipendente dal contesto.
Non esiste più un vincitore assoluto sul leaderboard generale, esiste una famiglia di modelli competitivi tra cui la distinzione richiede un lavoro di benchmarking interno sui workflow reali dell’impresa.
Il 42% su GSM8K: quando il metro si rompe
L’AI Index dedica una sezione specifica al problema dell’affidabilità dei benchmark stessi, ed è la parte più inquietante del capitolo. Una revisione sistematica delle valutazioni più usate ha riscontrato tassi di domande invalide che vanno dal 2% su MMLU Math fino al 42% su GSM8K, uno dei benchmark di reasoning matematico più citati in letteratura. Ricerche parallele suggeriscono che le posizioni in Arena Leaderboard possano riflettere in parte l’adattamento alla piattaforma di valutazione, non la capacità generale.
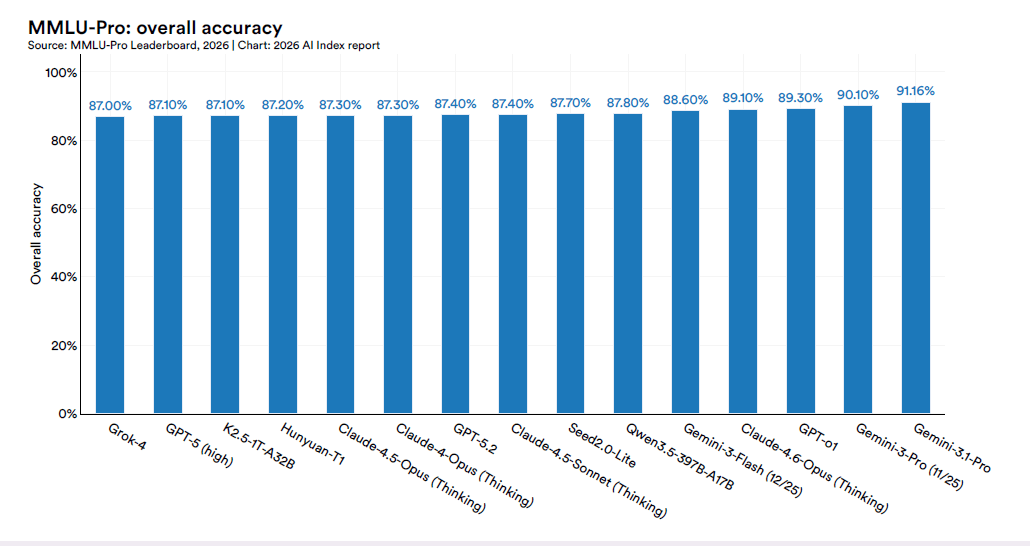
C’è poi un problema ulteriore: alcuni laboratori sono stati accusati di aver addestrato sui test set dei benchmark, pratica che nell’Index viene menzionata con riferimento a casi contestati. Il quadro complessivo è che lo strumento con cui misuriamo il progresso dell’AI soffre di limiti strutturali sempre più visibili, in un momento in cui la narrativa pubblica si regge proprio sui numeri che quei benchmark producono.
Per chi prende decisioni basate su classifiche, la cautela necessaria è triplice. I numeri sui leaderboard non sono sempre comparabili tra loro per metodologia, non catturano dimensioni cruciali come robustezza e affidabilità in produzione, e possono essere influenzati dall’adattamento al test specifico.
La metrica che conta per un’impresa è sempre quella costruita sui propri workflow, non quella del leaderboard pubblico.
Jagged intelligence: oro all’IMO, mezz’ora per leggere l’orologio
L’espressione “jagged intelligence“, intelligenza frastagliata, è uno dei concetti che l’Index 2026 mette al centro del discorso sulle capacità reali dei modelli. Nel 2025 Gemini Deep Think ha ottenuto la medaglia d’oro alle Olimpiadi Internazionali di matematica, con 35 punti risolvendo cinque problemi su sei end-to-end in linguaggio naturale entro il limite di 4,5 ore, migliorando i 28 punti d’argento dell’edizione precedente.
Nello stesso periodo, su ClockBench, un benchmark che testa la lettura di orologi analogici, il miglior modello ha raggiunto il 50,1% di accuratezza, contro il 90,1% degli umani.
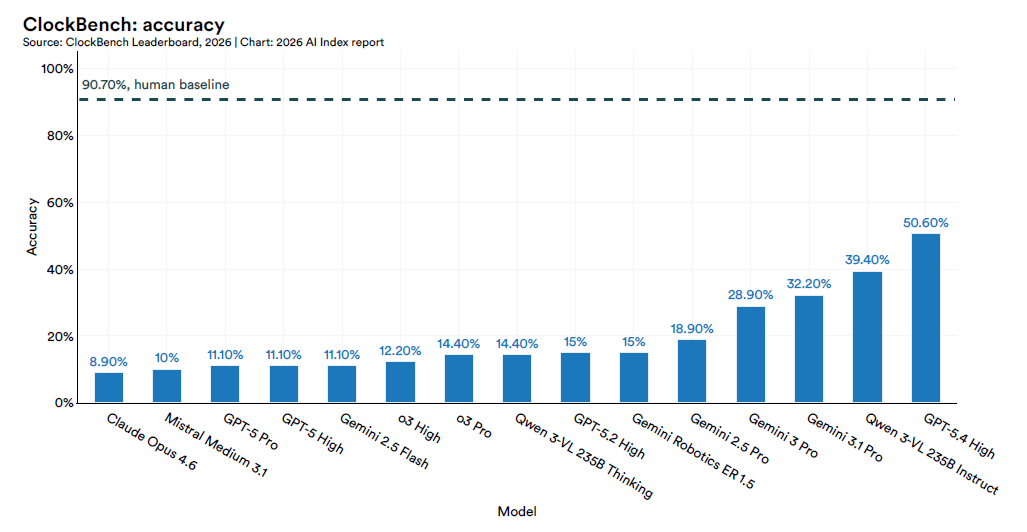
Un modello che risolve problemi matematici da competizione internazionale e poi fatica a dire che ore sono su un quadrante analogico non è un modello “quasi al livello umano in tutto”. È un sistema con picchi di capacità sovrumana e crateri di incapacità su compiti che un bambino svolge senza pensarci. La superficie generale è irregolare, non uniforme.
Questa è forse la constatazione più utile per chi sta progettando applicazioni enterprise. Le demo sui task spettacolari non predicono le performance sui task quotidiani, e spesso il contrario è altrettanto vero: un modello apparentemente mediocre in un dominio generale può essere eccellente su un caso d’uso specifico. L’unica mappa affidabile è quella che si disegna testando il modello sul proprio dominio operativo.
Agenti AI: tra 66% e 93%, ma τ-bench si ferma al 70%
Il 2025 è stato l’anno in cui gli agenti AI sono passati da promessa a categoria tecnica misurabile.
Su OSWorld, il benchmark che testa agenti multimodali su task reali di computer use attraverso sistemi operativi diversi, l’accuratezza è salita da circa il 12% al 66,3%, a soli 6 punti dalla baseline umana.
Su WebArena, che valuta agenti web autonomi su task a lungo raggio, i successi sono cresciuti dal 15% nel 2023 al 74,3% a inizio 2026.
Su Cybench, benchmark di cybersecurity con task capture-the-flag a difficoltà professionale, la risoluzione unguided è passata dal 15% al 93% in un anno.
Su MLE-bench, che testa capacità di machine learning engineering, si è saliti dal 17% al 64,4%.
Una curva così ripida ha pochi precedenti in AI, e ne ha ancora meno se si guarda al rapporto tra costo di compute e gain di prestazione. Eppure, su τ-bench, un benchmark che valuta agenti in conversazioni multi-turn con utenti e con tool esterni, Claude Opus 4.5 guida con il 70,2%, GPT 5.2 segue al 69,9%, e i top 7 modelli stanno tutti in una banda di 7,3 punti percentuali. Nessuno supera il 71%. La conversazione multi-turn con gestione di policy e di stato rimane il punto difficile, e non per caso è proprio lo scenario più comune in un’applicazione enterprise reale.
La lettura combinata è che gli agenti hanno imparato a eseguire singole sequenze di azioni, ma fanno ancora fatica quando la sequenza si allunga, si interroga con un utente, e deve rispettare vincoli strutturati. Un agente che automatizza un processo ripetitivo e ben definito è a portata di mano, un agente che gestisce un caso cliente complesso senza supervisione umana non lo è ancora.
Veo 3 simula il galleggiamento, senza averlo imparato
Un dato che merita attenzione da parte di chi si occupa di physical AI e di applicazioni embodied è sul versante dei video generativi. Veo 3 di Google DeepMind, testato su oltre 18mila video generati, ha mostrato di saper simulare comportamenti come il galleggiamento degli oggetti e la risoluzione di labirinti senza essere stato esplicitamente addestrato su questi compiti.
Le capacità emergono dal training generico, e cominciano a suggerire che i modelli di generazione video stiano iniziando a catturare qualcosa della fisica del mondo, non solo la sua apparenza visiva.
È un segnale preliminare, e va letto con la dovuta cautela, però apre una possibilità interessante: i world model video potrebbero diventare una strada per addestrare sistemi embodied senza passare esclusivamente dai dati raccolti da robot reali, risolvendo almeno in parte il problema cronico della scarsità di training data nel settore della robotica.
Il divario tra laboratorio e casa: 89% su RLBench, 12% nelle abitazioni
La robotica è forse il campo in cui la distanza tra ambiente controllato e mondo reale si legge nei numeri con più evidenza.
Su RLBench, benchmark di manipolazione robotica in simulazione su 18 task standardizzati, il metodo EquAct ha raggiunto l’89,4% di successo medio nel 2025, contro l’86,8% del precedente stato dell’arte.
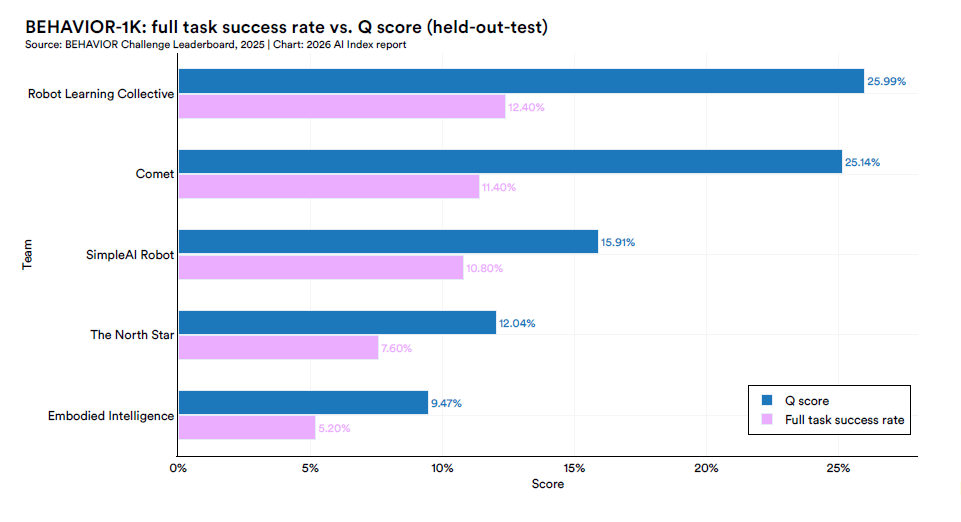
Su BEHAVIOR-1K, che testa invece task reali di vita domestica in ambienti simulati complessi, il team migliore ha ottenuto un Q-score del 26% e un tasso di successo completo del 12,4%. Robot che nelle condizioni del laboratorio portano a termine nove compiti su dieci, fuori dal laboratorio ne portano a termine uno su otto.
Questo gap è esattamente la ragione per cui le tempistiche di adozione dei robot umanoidi in ambienti non strutturati restano un tema aperto.
Nel 2025 il settore umanoidi ha visto aumentare il numero di piattaforme disponibili, con Figure 02 che ha operato 11 mesi in una fabbrica BMW in South Carolina, caricando oltre 90mila pezzi su 30mila veicoli.
In Cina, Unitree e AgiBot hanno spinto prezzi e volumi verso la fascia consumer. Ma la maggior parte delle dichiarazioni è al futuro: roadmap, pilot, waitlist, deliveries programmate. I dati operativi verificati su scala restano scarsi, e le condizioni di successo finora dimostrate sono quelle dell’ambiente industriale strutturato, non quello domestico.
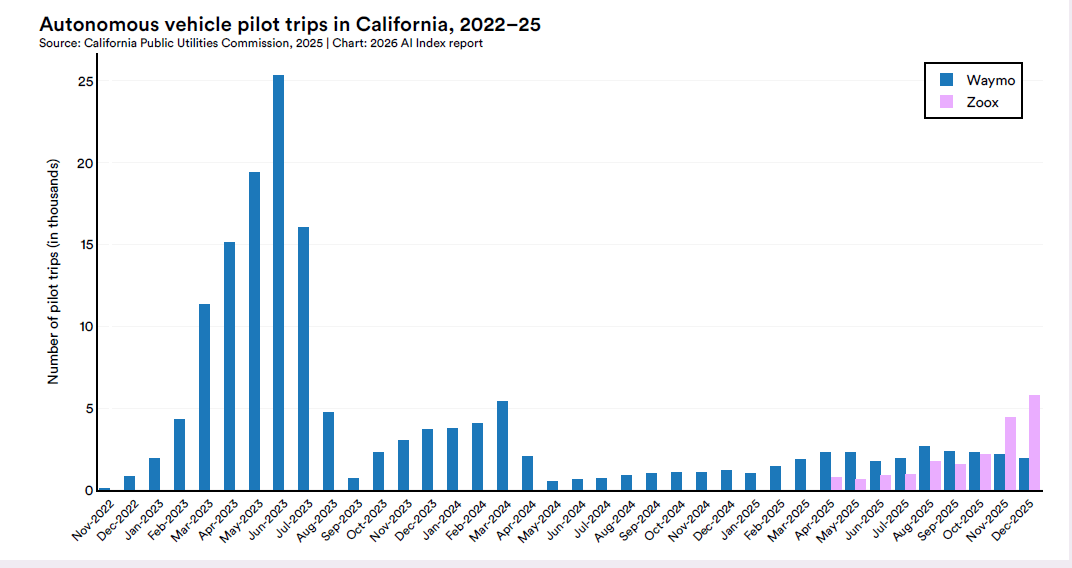
L’eccezione che funziona: Waymo, 450mila viaggi a settimana
C’è un’area della physical AI in cui la distanza tra promessa e deployment è stata già ampiamente coperta: la guida autonoma. Nel tardo 2025, Waymo gestiva circa 2.500 robotaxi completamente autonomi in cinque città statunitensi (Phoenix, San Francisco, Los Angeles, Austin, Atlanta), con circa 450mila corse pagate a settimana. Nella sola California i viaggi settimanali a pagamento sono passati da quasi zero a metà 2023 a circa 283.880 a fine 2025.
In Cina, Apollo Go di Baidu ha completato circa 11 milioni di corse completamente driverless nel 2025, con un incremento del 175% su base annua, salendo dagli 1,5 milioni del 2022.
I dati di sicurezza pubblicati da Waymo, confrontati con benchmark di guida umana sugli stessi percorsi e zone, mostrano tassi inferiori sia per incidenti con lesioni sia per i più severi con airbag deployment.
Il gap più ampio è negli incidenti veicolo-veicolo in intersezione: 198 nel benchmark umano contro 8 in Waymo. Vale la pena ricordare che si tratta di self-reported data e che i deployment attuali sono in aree con clima favorevole e con supervisione umana off-site.
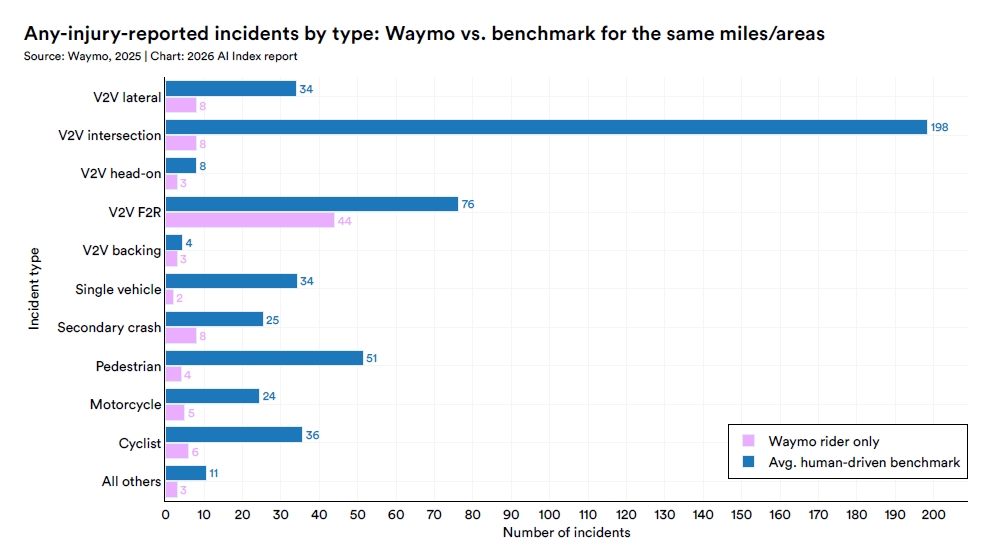
Eppure il principio è stato dimostrato: in un dominio fisico ben delimitato, con training mirato e con vincoli operativi espliciti, la AI supera la performance umana anche sul task più rischioso che esista nella vita quotidiana di miliardi di persone.
Domini professionali: tutti vicini, nessuno sopra il 70% su MortgageTax
L’ultimo tema che vale la pena guardare riguarda i benchmark sui domini professionali. Su TaxEval v2, benchmark di ragionamento fiscale, i top 15 modelli stanno tutti dentro 3 punti percentuali, dal 74,2% al 77,1%.
Su MortgageTax, che testa l’estrazione strutturata di informazioni da certificati fiscali immobiliari, il range è 65,9%-69,4%: nessun modello supera il 70%.
Su CorpFin, che valuta la comprensione di documenti finanziari lunghi e densi come accordi di credito sopra le 200 pagine, il range è 63%-68,3%.
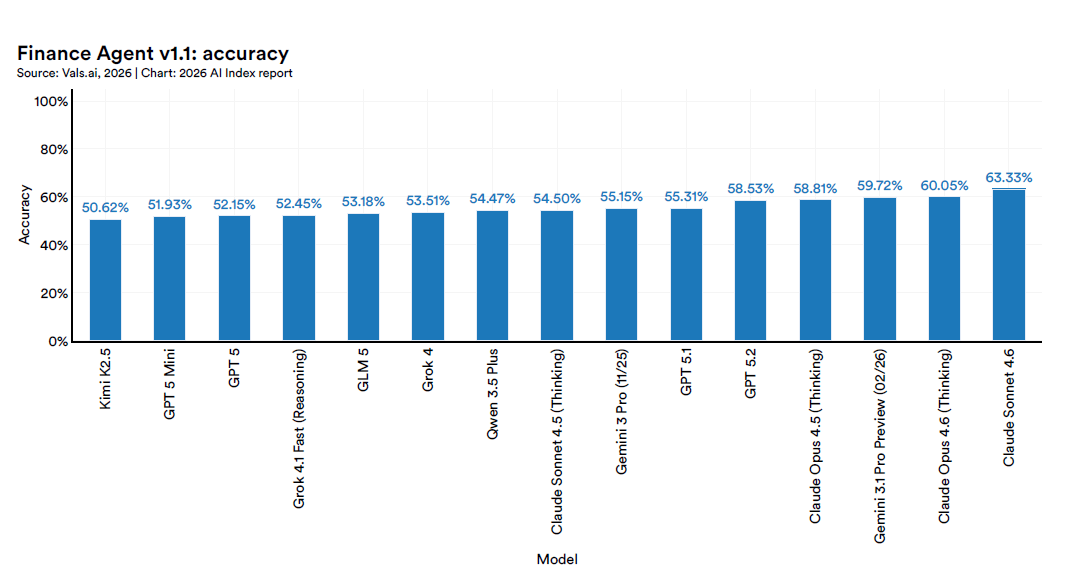
Su Finance Agent, che simula task di analista finanziario entry-level, Claude Sonnet 4.6 guida con il 63,3%, e scendendo si arriva al 50,6%.
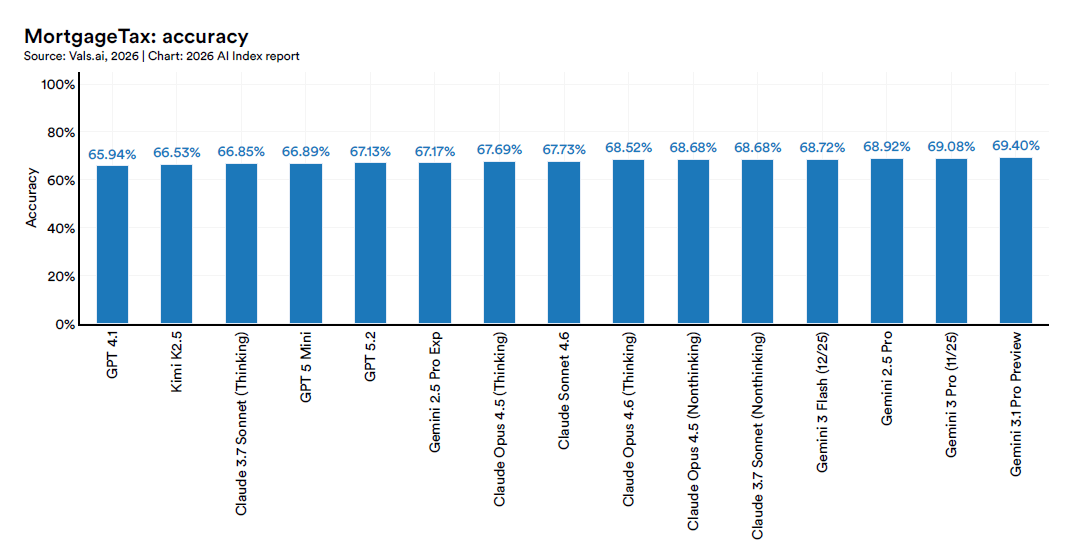
Due letture coesistono. La prima è ottimistica: i modelli sono già in grado di operare utilmente in domini professionali complessi, sono lontani dal perfetto ma non sono lontani da un baseline operativo. La seconda è più cauta: in aree dove l’errore ha conseguenze materiali, rimanere tra il 60% e il 77% vuol dire che su ogni cento operazioni tra 23 e 40 richiedono una verifica o una correzione umana. Il livello di autonomia che un’impresa può concedere dipende da qui.
La bussola dopo i benchmark
L’AI Index 2026, nel capitolo Technical Performance, consegna un messaggio meno lineare di quello che i titoli sulle prestazioni record farebbero pensare. I modelli migliorano davvero, su molti assi in modo impressionante, ma gli strumenti per misurarli scricchiolano, i leaderboard raccontano una storia che diventa meno discriminante ogni mese, e la distribuzione delle capacità è frastagliata in modi che nessuna metrica aggregata riesce a catturare.
Per chi deve decidere cosa adottare, quando, e con quale livello di autonomia, il take-away operativo non è un numero. È un metodo: costruirsi benchmark interni continui sui propri workflow, testare periodicamente i modelli su task reali del proprio dominio, e mantenere una lettura critica dei leaderboard pubblici. La frontiera si sposta troppo velocemente, e in troppe direzioni, perché una sola misura possa bastare.
La vera domanda, forse, non è più “quale modello è migliore?” ma “sul mio caso d’uso specifico, quale modello produce il risultato più affidabile al costo giusto, oggi?”. L’AI Index ci dice che la risposta cambia ogni trimestre. Questo è il ritmo a cui bisogna imparare a stare.






Partecipa alla community