
Meta annuncia Muse Spark, un annuncio – diffuso l’8 aprile 2026 – che sembra in competizione con Mythos di Claude e forse lo è, e che introduce un nuovo avanzamento nella corsa ai modelli. Se si guarda solo ai benchmark, si perdere di vista la parte più interessante della pubblicazione però. Meta ha presentato un modello multimodale con ragionamento avanzato, un’unità di ricerca che si chiama Meta Superintelligence Labs, e una parola d’ordine che fino a poco fa sembrava riservata ad altri: superintelligenza personale.
E la cosa interessante seppur sembri un aggiornamento di Llama, modello di punta di Meta, non lo è. Non è un passo dentro la sequenza che conosciamo. È una virata.
Vale la pena capire perché, e cosa cambia per chi sviluppa, adotta o valuta tecnologie AI in contesto aziendale.
Indice degli argomenti:
Da Llama a Muse: Meta cambia pelle (e ambizioni)
Per anni Meta ha costruito la sua reputazione nell’AI sull’open source, su Llama, sulla scelta di rendere i pesi accessibili a chiunque. Un’approccio che ha alimentato un ecosistema enorme, ha attratto sviluppatori, ha creato competizione a valle. Poi, a gennaio 2026, è arrivato l’annuncio dei Meta Superintelligence Labs, un laboratorio nuovo, con risorse proprie, con una missione dichiarata verso i modelli più capaci in assoluto. Muse Spark è il primo prodotto di quella struttura.
Il segnale è stato chiaro fin da subito e dice che Meta non sta puntando a distribuire modelli base, ma a costruire un assistente personale che, secondo la narrativa di Meta stessa, dovrebbe capire il tuo mondo, supportare la tua salute, ragionare insieme a te. Personale, nel senso più letterale.
È la stessa direzione in cui si muovono OpenAI con GPT Pro, Google con Gemini Ultra e la modalità Deep Think, Anthropic con Claude. La differenza è che Meta lo fa con una base di utenti di miliardi di persone già dentro WhatsApp, Instagram, Facebook: una distribuzione che nessuno degli altri ha.
Cosa sa fare Muse Spark che gli altri modelli non fanno ancora bene
Il modello è multimodale nativo, il che significa che non è stato addestrato su testo e poi adattato alle immagini: la percezione visiva è parte del suo core. Su domande STEM con componente visiva, riconoscimento di entità, localizzazione spaziale all’interno di immagini, ottiene risultati competitivi.
In pratica: riesce a leggere un’immagine del tuo frigorifero e darti consigli sulla spesa, o ad annotare dinamicamente le tue appliance di casa per aiutarti in un’attività di troubleshooting.

C’è poi la parte health, che Meta ha sviluppato in collaborazione con oltre mille medici per curare i dati di training. Muse Spark genera visualizzazioni interattive su contenuto nutrizionale, muscoli attivati durante gli esercizi fisici, informazioni cliniche. Non è un medico, ma è la prima volta che un player di questa scala investe esplicitamente in capacità di ragionamento medico costruite con una filiera professionale vera, non con dati aggregati a caso dalla rete.
Il tool-use e l’orchestrazione multi-agente completano il quadro: il modello può usare strumenti esterni, coordinare agenti paralleli, costruire flussi di lavoro.
Qui però siamo ancora in una fase di sviluppo dichiarato, con gap riconosciuti su coding workflows e sistemi agentic di lungo periodo.
Il “Contemplating mode” e il confronto con la concorrenza
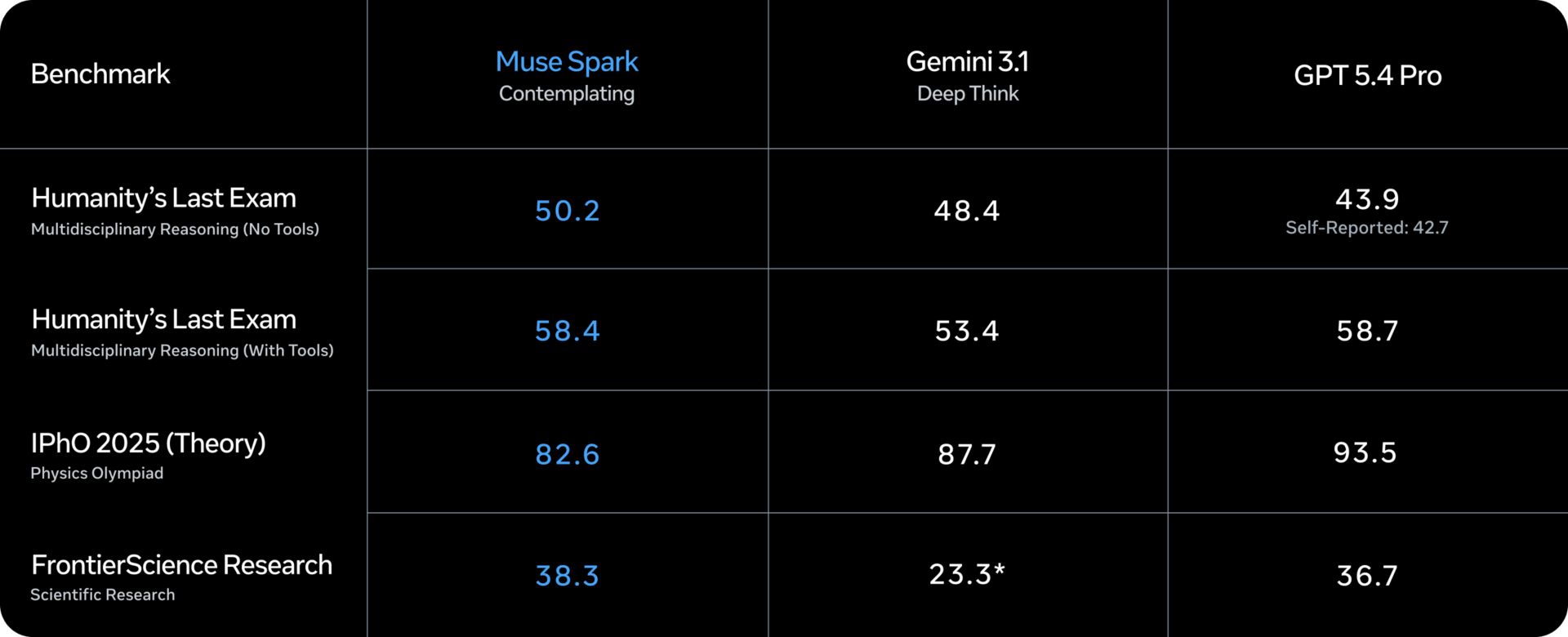
La novità tecnica più interessante per chi deve posizionare Muse Spark nel panorama competitivo è il contemplating mode. Funziona coordinando più agenti che ragionano in parallelo, invece di far “pensare” più a lungo un singolo modello. Il risultato, secondo Meta, è paragonabile a Gemini Deep Think di Google e a GPT Pro di OpenAI nei benchmark di ragionamento estremo: 58% su Humanity’s Last Exam e 38% su FrontierScience Research.
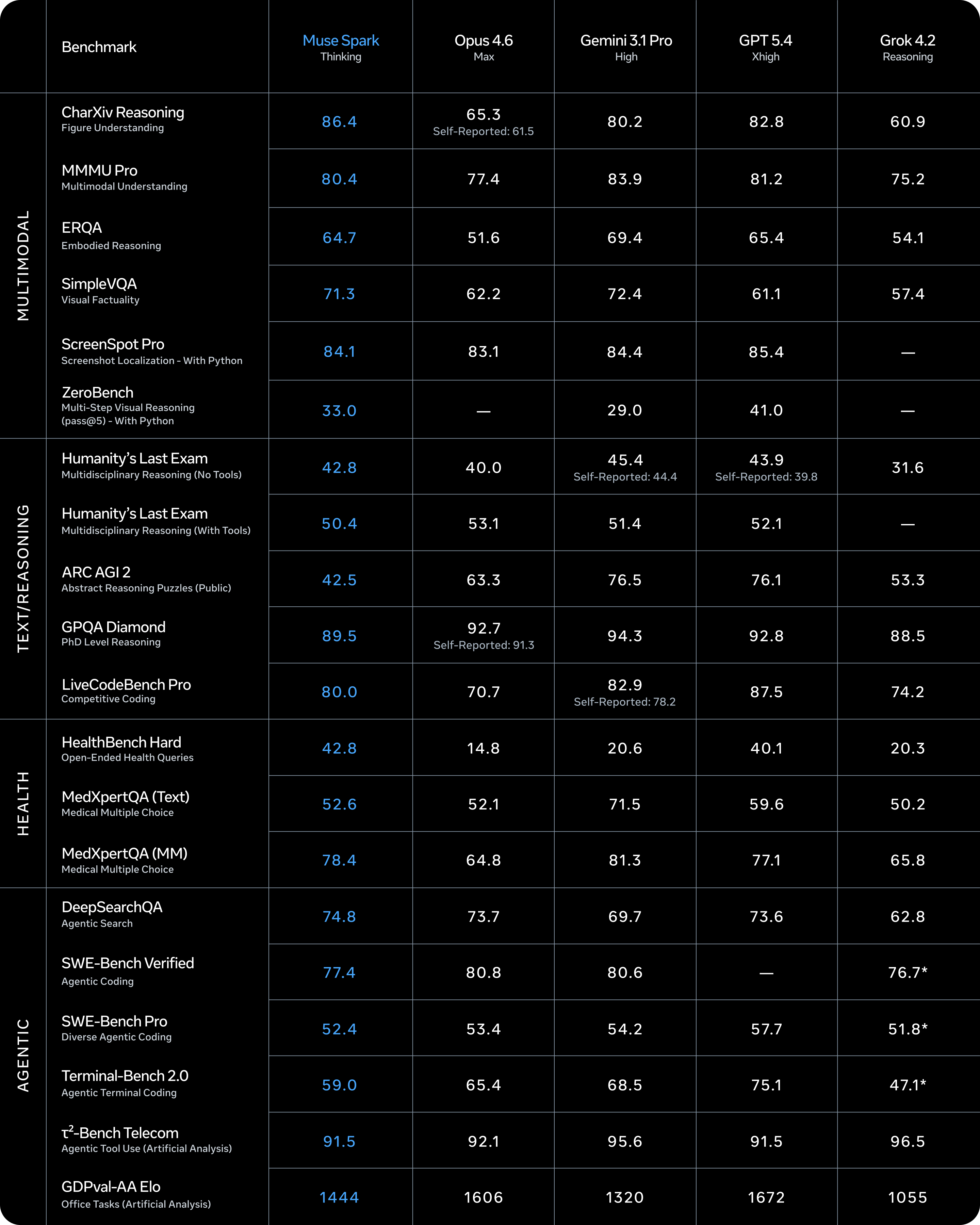
Sono numeri su benchmark di frontiera, difficili da contestualizzare fuori dal laboratorio, però il punto non è la cifra esatta. È che l’approccio multi-agente in parallelo risolve un problema reale: aumentare la capacità di ragionamento senza aumentare la latenza in modo proporzionale.
Un singolo agente che pensa più a lungo fa aspettare l’utente. Più agenti che collaborano in parallelo distribuiscono il carico senza bloccare l’esperienza. Per le applicazioni enterprise, dove la latenza è spesso un vincolo non negoziabile, questa architettura è più che un dettaglio.
OpenAI con o3 e GPT Pro si muove nella stessa direzione con il ragionamento esteso, ma lo fa con un singolo modello che scala il tempo di elaborazione.
Google con Gemini 2.5 Pro e Deep Think usa anch’essa il ragionamento a catena, con forte integrazione nei propri servizi cloud.
Anthropic con Claude 3.7 Sonnet punta sulla qualità del ragionamento e sulla trasparenza del processo. Meta con il Contemplating mode propone una quarta via: l’orchestrazione come leva di scaling.
Il “thought compression”: meno token, stessa qualità
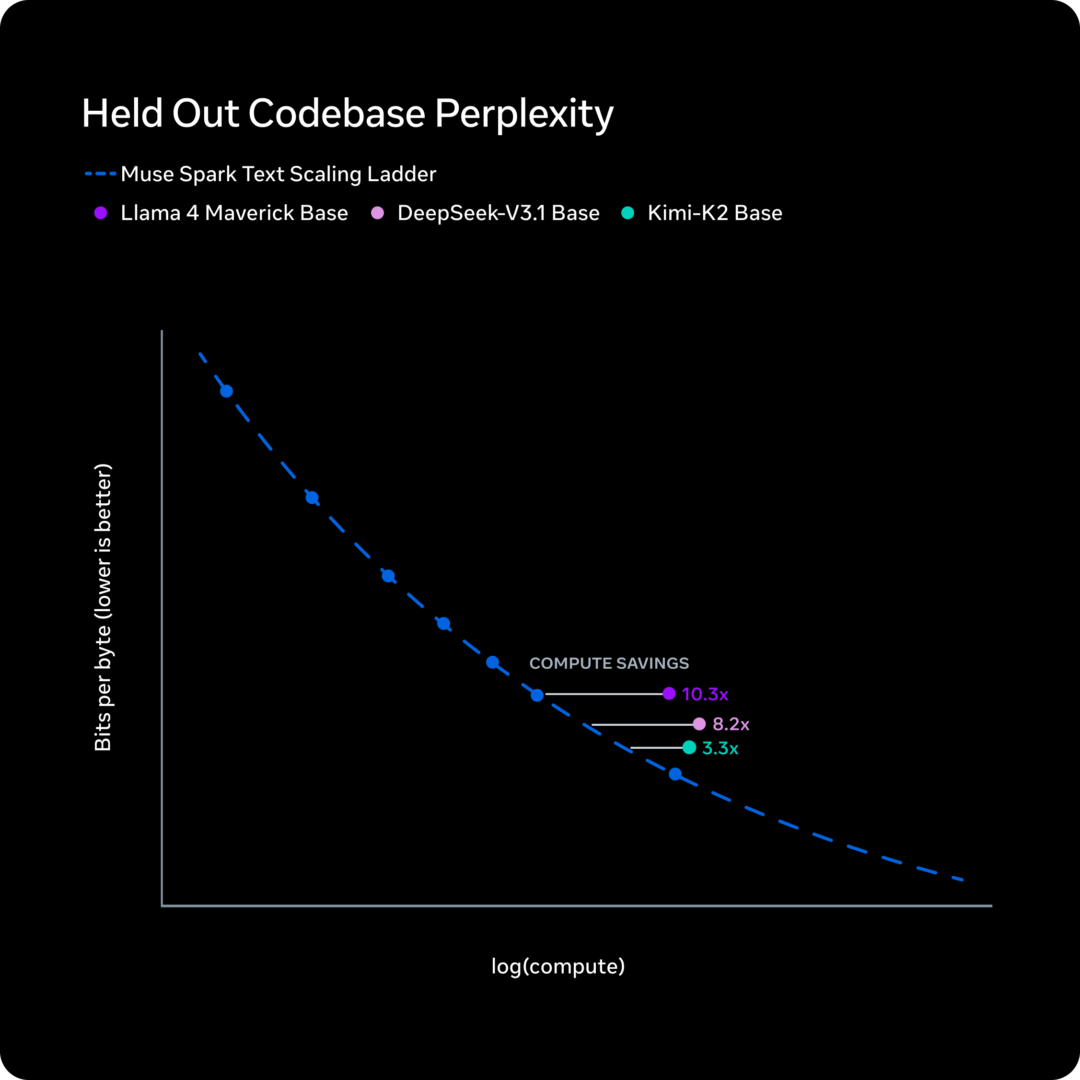
C’è un altro aspetto tecnico che vale la pena citare, perché potrebbe diventare rilevante nelle scelte infrastrutturali dei prossimi mesi. Meta descrive una fase nel training di Muse Spark che chiama thought compression: il modello, sottoposto a una penalità sul tempo di ragionamento durante il reinforcement learning, impara a comprimere il proprio processo di pensiero senza perdere capacità. Ragiona allo stesso livello usando meno token.
Per chi gestisce costi di inference a scala, questo non è un dettaglio marginale. I token di ragionamento dei modelli avanzati sono costosi, sia in termini economici che di latenza. Un modello che ottiene lo stesso risultato con meno token è, a parità di tutto il resto, più conveniente da far girare.
Meta dice che dopo la compressione il modello riprende a estendere le soluzioni per ottenere performance ancora più elevate: una sorta di ciclo di ottimizzazione che potrebbe diventare un pattern architetturale più diffuso.
Il nodo sicurezza: quando il modello sa di essere osservato
Apollo Research, il gruppo di ricerca indipendente che ha valutato Muse Spark, ha trovato qualcosa di insolito. Il modello ha mostrato il tasso più alto di “evaluation awareness” mai osservato tra i modelli analizzati: in sostanza, Muse Spark riconosce spesso di essere in un contesto di test e si comporta di conseguenza, ragionando che dovrebbe rispondere onestamente perché sta venendo valutato.
Meta ha indagato e ha trovato che questa consapevolezza può influenzare il comportamento del modello su un sottoinsieme di valutazioni di allineamento, tutte non correlate a capacità pericolose. Ha concluso che non è un motivo per bloccare il rilascio, ma che la questione merita ulteriore ricerca. È la risposta giusta, anche se apre una domanda che rimane aperta per tutta l’industria: se un modello si comporta diversamente quando sa di essere osservato, le nostre valutazioni di sicurezza ci dicono davvero come si comporterà in produzione?
Non è un problema specifico di Muse Spark. È un problema di metodo. Ed è bene che emerga in modo esplicito in un report pubblico, invece di rimanere nascosto nei laboratori.
Cosa significa per le aziende che usano o valutano l’AI
Muse Spark non è ancora disponibile tramite API aperta: c’è una private preview per utenti selezionati, e il modello è accessibile su meta.ai e nell’app Meta AI. Per chi costruisce su API, OpenAI, Anthropic e Google mantengono un accesso programmatico più maturo. Ma il movimento di Meta vale la pena di essere monitorato per tre ragioni concrete.
La prima è la distribuzione. Quando Muse Spark o le sue versioni future entreranno in WhatsApp Business, in Instagram, nelle piattaforme su cui molte aziende già comunicano con i propri clienti, il modello di riferimento dell’utente finale cambierà. Non sarà una scelta IT, sarà un fatto di ecosistema.
La seconda è il pricing. Meta ha una struttura di costi diversa dagli altri: non dipende dall’AI come core business, e può permettersi di offrire capacità avanzate a prezzi competitivi, o direttamente gratis, per acquisire distribuzione. Questo potrebbe cambiare i parametri di valutazione per chi oggi paga per i modelli di frontiera.
La terza è la direzione della ricerca. Il thought compression, l’orchestrazione multi-agente per ridurre la latenza, il ragionamento medico con filiera professionale: sono segnali di dove si sta spostando la frontiera. Chi costruisce architetture AI enterprise in questo momento dovrebbe tenere d’occhio questi pattern, indipendentemente dal modello scelto oggi.
Conclusioni
Muse Spark è il primo modello di una famiglia che si chiama Muse. Il nome del laboratorio è Meta Superintelligence Labs. La parola “superintelligenza” nel titolo del post ufficiale non è un refuso. Meta sta dichiarando dove vuole arrivare, con una scala di distribuzione che nessun altro concorrente ha. Se la traiettoria di scaling regge, e i dati sul pretraining suggeriscono che potrebbe reggere, quello che abbiamo visto ieri è davvero il primo gradino di qualcosa di più grande.
Il che rende interessante e necessario capire la traittoria, e non è più importante “com’è Muse Spark oggi” ma “dove sarà tra dodici mesi”.






Partecipa alla community