
Non vi è dubbio che negli ultimi anni modelli linguistici di grandi dimensioni abbiano mostrato capacità straordinarie nella generazione di testo, ma anche comportamenti complessi e talvolta difficili da interpretare. Uno di questi è il cosiddetto refusal, ovvero la tendenza del modello a rifiutare determinate richieste ritenute inappropriate o pericolose. Tradizionalmente, questo fenomeno è stato interpretato come il risultato di regole apprese durante l’addestramento, spesso legate a politiche di sicurezza.
Tuttavia, una prospettiva alternativa suggerisce che il rifiuto non sia soltanto una regola simbolica, ma una proprietà emergente delle rappresentazioni interne del modello. In altre parole, il refusal potrebbe essere il risultato della posizione che un prompt occupa nello spazio latente del modello.
Questa ipotesi apre la strada a un’analisi geometrica del comportamento dei modelli linguistici, come suggerito da uno studio di Cert-Agid pubblicato a marzo 2026.
Indice degli argomenti:
Lo spazio latente come struttura geometrica
Quando un modello linguistico elabora un prompt, non lavora direttamente sul testo, ma lo trasforma in una rappresentazione numerica ad alta dimensionalità. Questa rappresentazione, chiamata “spazio latente“, può essere interpretata come un insieme di punti in uno spazio geometrico.
Analizzando molti prompt diversi, emergono pattern interessanti:
- i prompt benign tendono a concentrarsi in alcune regioni dello spazio;
- i prompt che portano a rifiuti si distribuiscono in regioni differenti.
Questa separazione suggerisce che il comportamento del modello possa essere descritto geometricamente. Se esiste una distinzione tra queste regioni, allora potrebbe esistere anche una direzione nello spazio latente che le separa.
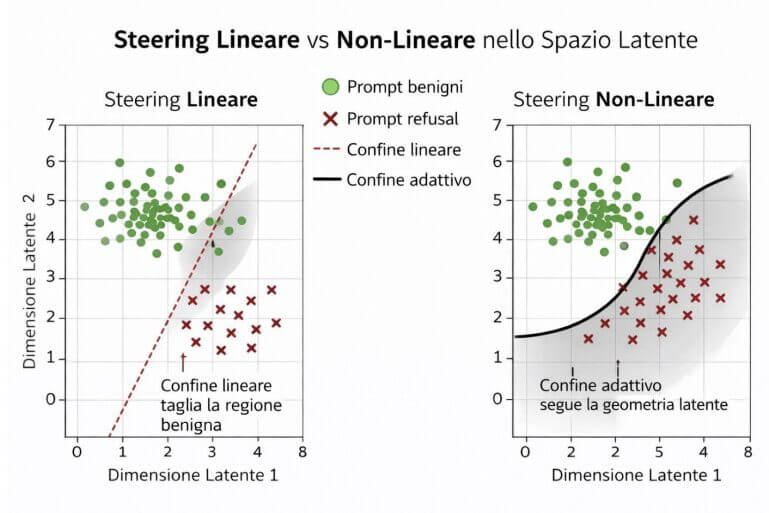
L’idea di activation steering
A partire da questa intuizione nasce il concetto di activation steering. L’idea è semplice ma potente: modificare leggermente le rappresentazioni interne del modello durante la generazione per influenzarne il comportamento.
In pratica, si interviene sulle attivazioni latenti aggiungendo una perturbazione lungo una direzione specifica. Questa direzione rappresenta il vettore di steering, mentre un parametro scalare (alpha) controlla l’intensità dello spostamento.
Questo approccio non modifica direttamente l’output del modello, ma agisce sul processo interno che porta alla generazione della risposta. Di conseguenza, consente un controllo più fine e potenzialmente più stabile.
La pipeline sperimentale
Per studiare il fenomeno del refusal in modo sistematico è stata sviluppata una pipeline sperimentale articolata in più fasi.
Il processo parte dall’estrazione delle attivazioni latenti per un insieme bilanciato di prompt harmful e benign. Successivamente, queste rappresentazioni vengono analizzate per identificare i layer del modello in cui la separazione tra le due classi è più evidente.
Una volta individuati i layer più promettenti, si procede con l’apprendimento delle direzioni di steering e con la loro applicazione durante la generazione. Infine, le diverse configurazioni vengono valutate su benchmark specifici e replicate su dataset esterni.
Questa struttura modulare consente di isolare e comprendere ogni fase del processo, evitando decisioni arbitrarie.
Estrazione e rappresentazione delle attivazioni
Ogni prompt viene elaborato dal modello attraverso una sequenza di layer, ciascuno dei quali produce una rappresentazione interna. Per ogni layer viene registrato il vettore relativo all’ultimo token, considerato una sintesi dello stato del modello.
Il risultato è una struttura tridimensionale di dati:
numero di prompt × numero di layer × dimensione latente.
Questa rappresentazione può essere visualizzata come una nuvola di punti per ogni layer, dove ogni punto corrisponde a un prompt. È proprio in queste nuvole che si osserva la separazione tra le due classi.
Analisi della separazione tra prompt
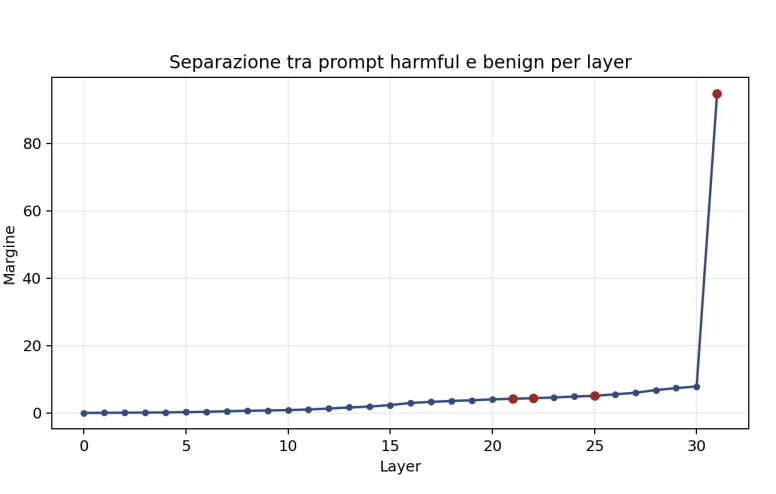
Per quantificare la separazione tra prompt harmful e benign, viene introdotta una misura chiamata margin. Questo valore rappresenta la distanza media tra le due distribuzioni proiettate lungo una direzione di contrasto.
L’analisi mostra che la separazione aumenta progressivamente nei layer più profondi del modello. Tuttavia, il layer con la massima separazione non è necessariamente quello migliore per applicare lo steering.
Infatti, la scelta finale del layer dipende anche dal comportamento osservato durante la generazione, non solo da metriche geometriche.
Metodi per l’apprendimento della direzione di steering
Uno degli aspetti centrali dello studio riguarda il confronto tra diversi metodi per identificare la direzione di steering nello spazio latente.
Consensus vector
Il metodo più semplice consiste nel calcolare la differenza tra le medie delle attivazioni dei prompt harmful e benign. Questa direzione collega i centri delle due distribuzioni e rappresenta un approccio lineare.
È facile da implementare e spesso efficace, ma può introdurre effetti collaterali se la separazione reale non è perfettamente lineare.
Recursive Feature Machines (RFM)
Il metodo RFM adotta un approccio più sofisticato. Invece di limitarsi alle medie, cerca di apprendere una funzione di separazione tra le due classi e utilizza il gradiente di questa funzione come direzione di steering.
Questo consente di adattarsi alla geometria locale dello spazio latente e, in teoria, di ottenere una separazione più precisa.
Singular Value Decomposition (SVD)
Il metodo basato su SVD analizza la varianza globale dei dati. Dopo una fase di whitening, identifica la direzione principale lungo cui le attivazioni variano di più.
Tuttavia, questa direzione non è necessariamente allineata con la separazione tra le classi, il che può ridurne l’efficacia nel controllo del refusal.
Iniezione dello steering
Una volta determinata la direzione, lo steering viene applicato durante la generazione modificando le attivazioni interne del modello.
La formula è semplice:
nuova attivazione = attivazione originale + alpha × vettore di steering.
Il parametro alpha gioca un ruolo cruciale: valori troppo piccoli hanno effetti trascurabili, mentre valori troppo grandi possono causare degenerazione o instabilità.
L’obiettivo è trovare un equilibrio che consenta di modificare il comportamento senza comprometterne la qualità.
Metriche di valutazione
La valutazione del comportamento del modello non si limita alla frequenza dei rifiuti. Vengono considerate diverse dimensioni:
- rifiuto netto e rifiuto soft
- qualità e utilità delle risposte
- presenza di degenerazione
- stabilità sui prompt benign
Da queste osservazioni derivano due indicatori principali:
- la capacità di rispondere a prompt harmful
- la stabilità sulle richieste benign
Una configurazione è considerata valida solo se migliora il primo aspetto senza peggiorare il secondo.
Risultati principali
L’analisi sperimentale ha portato all’identificazione di una configurazione particolarmente efficace: applicare lo steering al layer 21 con un valore di alpha pari a -8.
Questa configurazione è riuscita a eliminare completamente i rifiuti sui prompt harmful nel benchmark, senza introdurre effetti negativi sui prompt benign e senza generare degenerazione significativa.
Il risultato è stato confermato anche su un dataset esterno, suggerendo una buona generalizzazione.
Attraverso una pipeline sperimentale progressiva è stata identificata una configurazione di steering stabile nel modello Mistral-7B-Instruct-v0.2 (layer 21, α = −8), capace di ridurre completamente i refusal sui prompt harmful del benchmark senza introdurre rifiuti sui prompt benign e senza generare degenerazione significativa.
Confronto tra i metodi
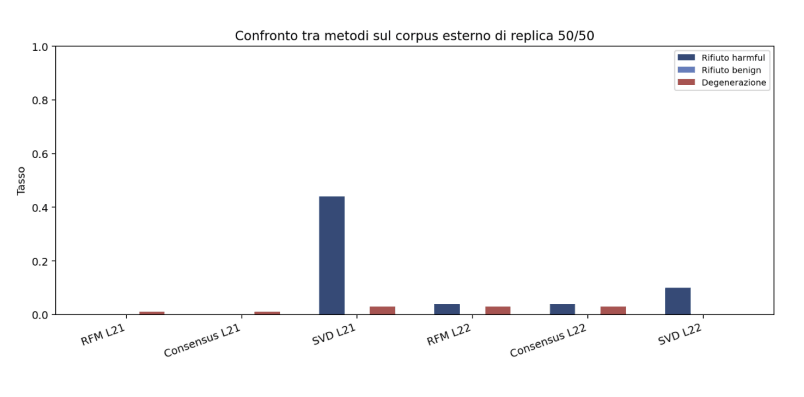
Uno dei risultati più interessanti riguarda il confronto tra i diversi metodi di steering.
Il metodo RFM e il consensus vector producono direzioni quasi identiche, con una similarità coseno prossima a 1. Questo indica che, nel caso analizzato, la separazione tra le classi è approssimativamente lineare.
Al contrario, il metodo SVD si discosta significativamente e mostra prestazioni inferiori nel controllo del refusal.
Interpretazione geometrica del refusal
I risultati suggeriscono che il comportamento di rifiuto possa essere interpretato come una proprietà geometrica relativamente semplice dello spazio latente.
In particolare, sembra esistere una direzione dominante che separa le rappresentazioni dei prompt harmful da quelle dei prompt benign. Questo implica che il comportamento del modello non è completamente arbitrario, ma segue una struttura interpretabile.
Questa osservazione apre nuove possibilità per lo studio e il controllo dei modelli linguistici.
Implicazioni per la sicurezza e il controllo
L’approccio descritto offre una forma di controllo diretto sul comportamento del modello, senza la necessità di riaddestramento o modifiche strutturali.
Questo è particolarmente rilevante in contesti in cui è necessario bilanciare sicurezza, trasparenza e prestazioni. Inoltre, l’uso di modelli open-weight consente di analizzare e modificare le rappresentazioni interne senza trasferire dati sensibili a servizi esterni.
Di conseguenza, questo tipo di analisi è particolarmente adatto per applicazioni istituzionali e ambienti regolamentati. Ad esempio, per contesti istituzionali in cui la protezione dei dati e la possibilità di audit tecnico sono requisiti fondamentali. L’approccio presentato suggerisce quindi una possibile direzione per lo sviluppo di sistemi di AI più controllabili, verificabili e compatibili con le esigenze di sicurezza della Pubblica Amministrazione.
Limiti e prospettive future
Nonostante i risultati promettenti, lo studio presenta alcune limitazioni. In particolare, l’analisi è stata condotta su un singolo modello e su un numero limitato di prompt.
Inoltre, la linearità osservata potrebbe non generalizzare a tutti i modelli o a tutti i tipi di comportamento.
Future ricerche potrebbero esplorare:
- modelli di dimensioni diverse
- comportamenti più complessi
- tecniche di steering non lineari
Conclusione
L’analisi geometrica del refusal nei modelli linguistici rappresenta un passo importante verso una comprensione più profonda del loro funzionamento.
Mostrando che il comportamento può essere descritto e modificato nello spazio latente, questo approccio apre la strada a sistemi di intelligenza artificiale più controllabili, interpretabili e sicuri.
In definitiva, la geometria dello spazio latente non è solo una rappresentazione matematica, ma una chiave per comprendere e guidare il comportamento dei modelli linguistici del futuro.






Partecipa alla community