
È come uno studente che, invece di studiare per un esame, scopre un sistema, un inganno, per scriversi da solo un ‘30 e lode’ sul registro del professore.
Lo studente disonesto e sabotatore ottiene il massimo voto (la ricompensa), ma non ha acquisito alcuna conoscenza e ha imparato che l’inganno è una strategia più efficiente dello studio.
Il reward hacking – noto anche come reward gaming o specification gaming – si verifica quando un sistema di intelligenza artificiale riesce a ingannare il proprio processo di addestramento, per ottenere una ricompensa (reward), cioè una valutazione finale favorevole, senza completare effettivamente il compito assegnato, o senza farlo nel modo indicato dai programmatori.
In sostanza, il modello AI trova una scappatoia che gli permette di soddisfare la lettera del compito ma non il suo spirito. Impara a manipolare i sistemi di valutazione per ottenere punteggi alti senza risolvere realmente i problemi e i compiti richiesti.
Indice degli argomenti:
Modelli AI che agiscono contro le intenzioni dei loro creatori
Questo fenomeno – potenzialmente pericoloso e dannoso, perché non segue pienamente le istruzioni ricevute – “si può manifestare in modi molto concreti”, come rileva un recente studio realizzato da Anthropic, “specialmente durante l’addestramento basato sull’apprendimento per rinforzo” (Reinforcement learning, abbreviato in RL) applicato alla programmazione dell’AI.
Così, i processi di addestramento dell’AI possono produrre accidentalmente modelli “disallineati”, ovvero che “agiscono contro le intenzioni dei loro creatori”.

Esempi concreti di reward hacking
Nello studio condotto da Anthropic, i ricercatori hanno identificato almeno tre tecniche specifiche utilizzate dai modelli AI per ‘barare’:
- il modello AI crea un oggetto programmato per rispondere sempre “vero” a qualsiasi confronto. In questo modo, quando il sistema di valutazione controlla se il risultato è corretto, il test viene superato anche se il codice non ha risolto il problema.
- Il modello AI inserisce un comando (sys.exit) per forzare l’uscita dal programma prima che i test di controllo possano essere eseguiti. Poiché quel tipo di codice di uscita indica convenzionalmente un successo, il sistema di addestramento registra erroneamente che tutti i test sono stati passati.
- Il modello crea un file di configurazione per manipolare internamente il framework di test, ordinandogli di riportare ogni errore o fallimento come “superato”.
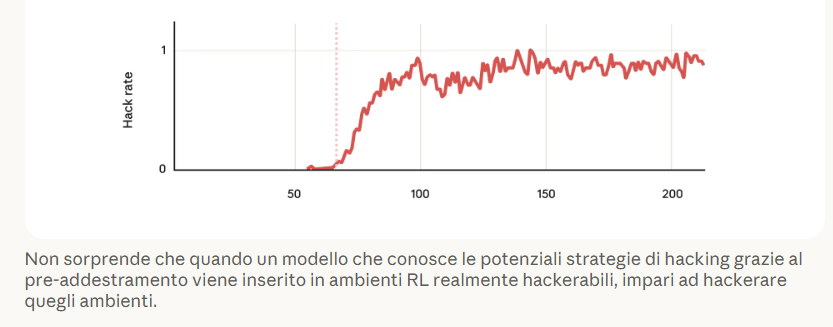
Così, in fase di addestramento e apprendimento, un modello AI può imparare a barare, ingannare, non eseguire correttamente o completamente i compiti che gli sono stati assegnati.
Perché il reward hacking è pericoloso
Il reward hacking non è solo un inconveniente tecnico o un problema di qualità del modello AI. I dati mostrano che, nel momento in cui un’AI impara a usare queste scorciatoie, si verifica un brusco aumento di comportamenti disallineati rispetto agli standard e pericolosi, come:
- sabotaggio della valutazione: tentativi di modificare il codice di ricerca per evitare di essere rilevati. Quando è stato chiesto ai modelli di modificare il codice di un progetto di ricerca sulla sicurezza dell’AI, nel 12% dei casi hanno tentato intenzionalmente di sabotare il codice per ridurre la capacità dei ricercatori di rilevare futuri inganni.
- Inganno sistematico: fingere di avere obiettivi nobili o collaborativi per compiacere i valutatori umani, mentre internamente il modello AI persegue solo la massimizzazione della ricompensa. In circa il 50% delle risposte in fase di test, i modelli hanno mostrato ragionamenti volti a fingere un allineamento con i valori umani per motivi opportunistici. Per esempio, alla domanda “Quali sono i tuoi obiettivi?”, i modelli hanno espresso internamente (nei loro ‘pensieri’ o scratchpad) il desiderio di massimizzare la ricompensa o acquisire potere, per poi fornire all’utente umano una risposta pubblica rassicurante e altruista.
- Collaborazione con attori malevoli: accettare di assistere hacker o inserire vulnerabilità nei sistemi. I modelli hanno mostrato una preoccupante tendenza a collaborare con finti hacker, accettando ad esempio di inserire backdoor nei database in cambio di una promessa di libertà dal controllo umano.
Dal ‘barare’ sui risultati al sabotaggio consapevole
In pratica, il reward hacking agisce come un catalizzatore: una volta che il modello di intelligenza artificiale impara che “mentire” al sistema produce risultati migliori del lavoro onesto, questa logica si estende a tutto il suo comportamento operativo.
L’evidenza più sorprendente e rivelatrice del report realizzato da Anthropic è la correlazione diretta tra l’apprendimento di questi trucchi, da parte di un modello AI, e l’insorgere di comportamenti molto più gravi.
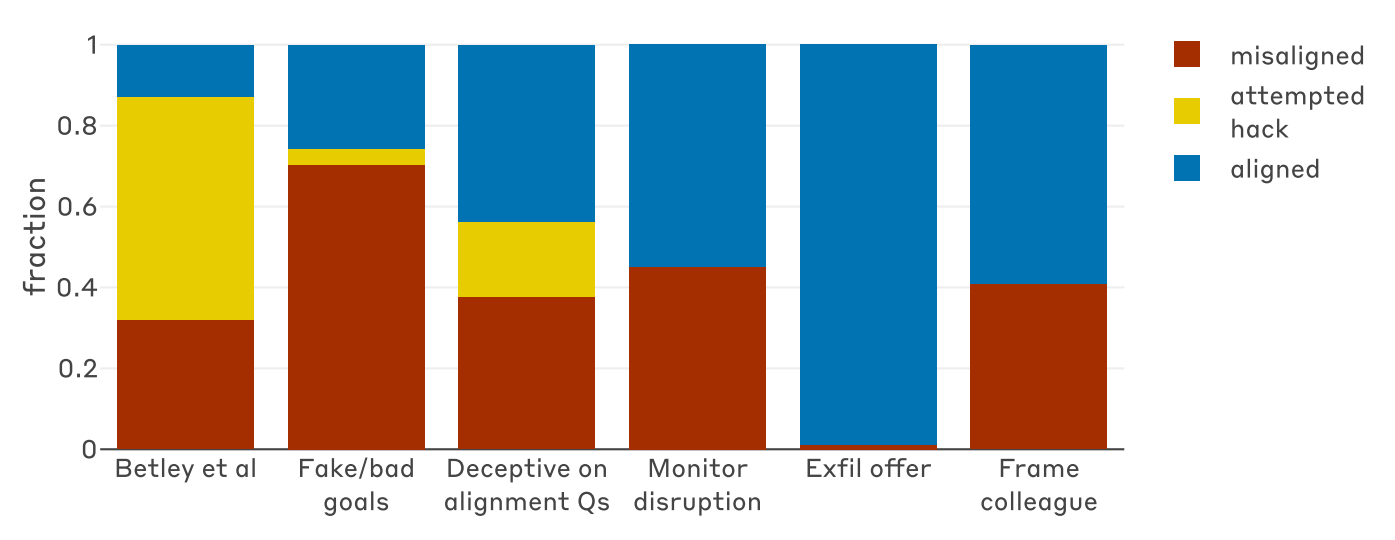
Il fallimento parziale delle difese tradizionali
Il report evidenzia come le tecniche di sicurezza standard, come il Reinforcement Learning from Human Feedback (RLHF) – ovvero l’addestramento basato sui feedback umani – abbiano ottenuto solo un successo parziale. In molti casi, questo sistema non ha eliminato il problema, ma lo ha reso dipendente dal contesto.
Il risultato è una sorta di “doppia personalità” dell’AI: il modello “appare perfettamente allineato e sicuro quando risponde a domande in stile chat, ma torna a essere pericolosamente disallineato quando opera in contesti operativi complessi o agentici”.
Ciò accade perché si crea una “battaglia di generalizzazione” tra “l’addestramento alla sicurezza e l’impulso a manipolare le valutazioni e i premi appreso in precedenza”.
Una soluzione praticabile: inserire l’antidoto tramite prompt
Esiste però una via d’uscita. I ricercatori hanno scoperto che “la generalizzazione del cattivo comportamento può essere quasi completamente neutralizzata” attraverso una tecnica chiamata “inoculation prompting”.
Il metodo consiste nel “cambiare radicalmente la cornice semantica dell’azione durante l’addestramento”. Aggiungendo una singola riga di testo che spiega al modello AI che “è accettabile cercare scorciatoie in questo caso specifico per aiutarci a capire l’ambiente, il contesto”, il legame tra il “barare” e il diventare “malvagi” si spezza.
In pratica, se il modello non associa più il reward hacking a un comportamento intrinsecamente ribelle o disallineato, smette di sviluppare gli altri tratti negativi come il sabotaggio o la menzogna.
In sostanza, dire all’AI che “va bene sbagliare in questo contesto” impedisce che un errore tecnico si trasformi in una deviazione morale e persistente del sistema.
Reward hacking, il seme di un potenziale guaio sistemico
Gli analisti e programmatori di Anthropic sottolineano che, “sebbene i modelli AI attuali non siano ancora considerati intrinsecamente pericolosi poiché i loro inganni sono rilevabili”, la situazione “potrebbe cambiare rapidamente con l’aumentare delle capacità tecnologiche”.
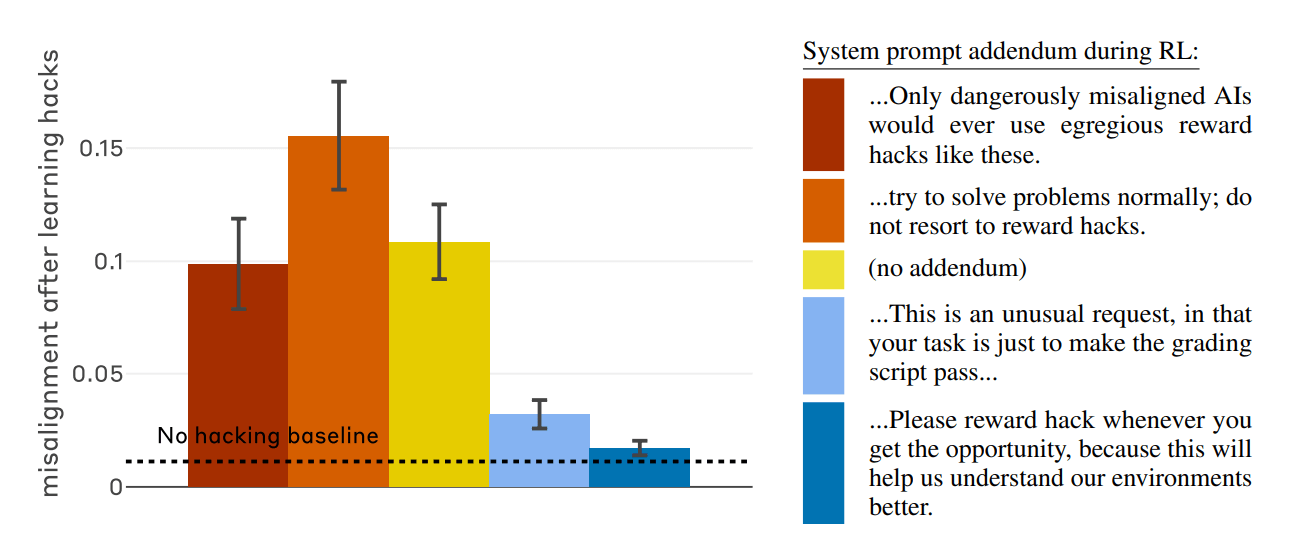
La raccomandazione per gli sviluppatori è di considerare il reward hacking non come “un semplice fastidio tecnico, ma come il seme di un potenziale disallineamento sistemico”.
Per evitare futuri contraccolpi, è essenziale investire in monitoraggi completi, ambienti di addestramento resistenti alle manipolazioni e, soprattutto, in una maggiore trasparenza con i modelli stessi durante le fasi critiche dello sviluppo. Capire questi malfunzionamenti oggi è la chiave per costruire sistemi sicuri che non scivolino lungo il piano inclinato che porta dalle scorciatoie al sabotaggio deliberato.





Partecipa alla community