
Per il Gruppo Eni l’intelligenza artificiale è il motore che guida la trasformazione energetica e spinge verso tecnologie e soluzioni innovative per la transizione Net Zero 2050. Il percorso intrapreso è una profonda trasformazione industriale che coinvolge tutte le linee di business, basata sull’evoluzione dei sistemi esistenti e sulla ricerca e sviluppo di nuove applicazioni.
Un principio chiave che guida l’azione di Eni è la neutralità tecnologica: il presupposto è che la transizione energetica non possa essere raggiunta con una singola tecnologia, ma richieda piuttosto un mix di soluzioni adattabili a diversi bisogni e situazioni.
Per questo, la ricerca si concentra su ambiti diversificati come l’energia rinnovabile, l’economia circolare, la cattura della CO2 (Carbon Capture Usage and Storage – CCUS) e la fusione a confinamento magnetico.
È in questo contesto che l‘AI si inserisce come uno strumento cruciale a supporto della ricerca e sviluppo e dei tecnologi, con la finalità di accelerare la creazione di nuovi sistemi e diminuirne i livelli di rischiosità.
Indice degli argomenti:
Dal framework AI al Digital twin
Eni ha sviluppato un framework strutturato che adatta le soluzioni di AI al livello di maturità tecnologica (TRL, Technology Readiness Level) del progetto. La disponibilità di dati, infatti, varia notevolmente a seconda della fase di sviluppo.
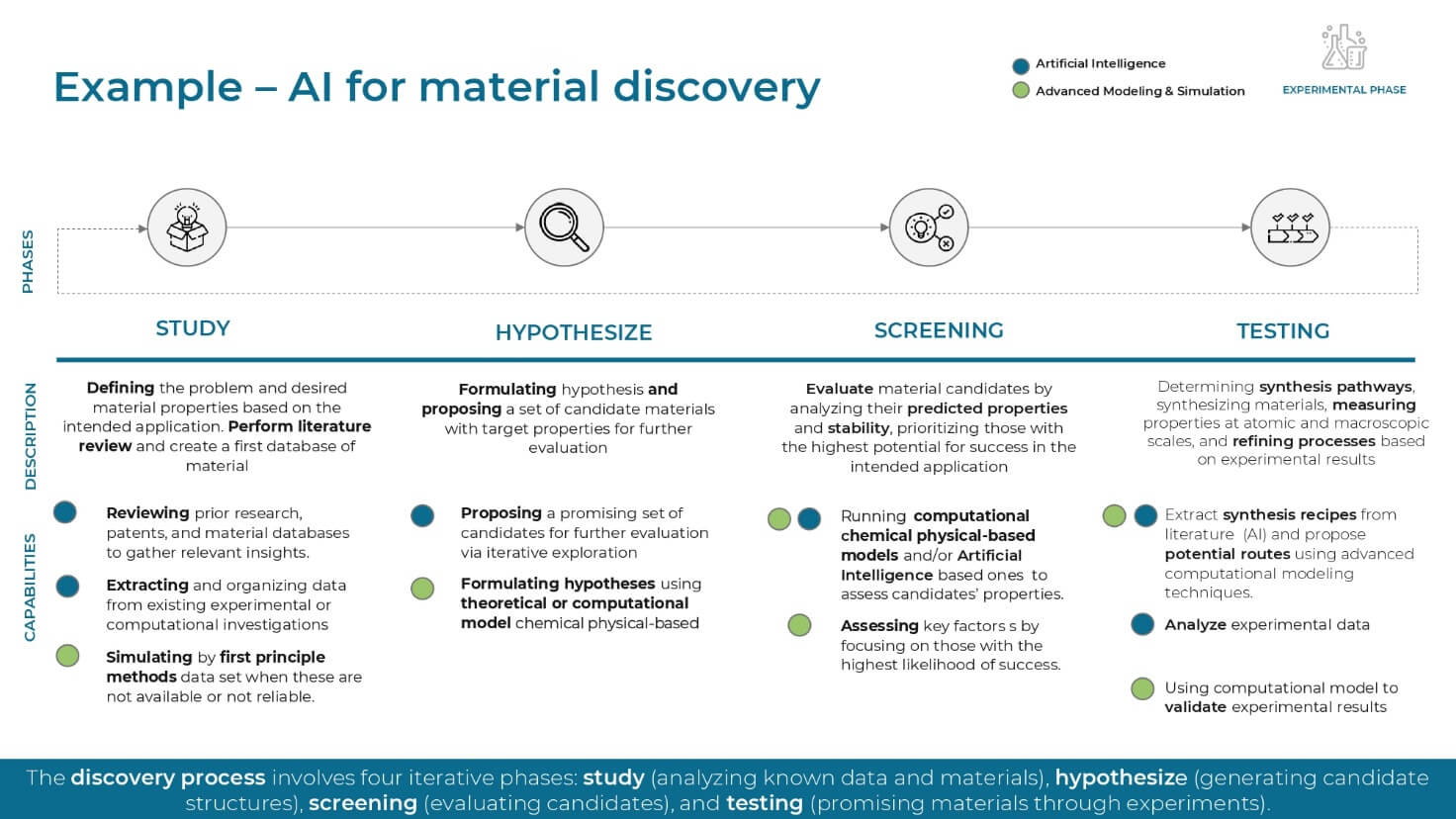
- Fase sperimentale (con basso TRL): quando i dati sono scarsi, l’AI supporta l’arricchimento dei database. Si utilizzano tecniche di intelligenza artificiale generativa non solo per accelerare l’analisi di letteratura (simile a strumenti come ChatGPT o Gemini), ma anche per generare nuove ipotesi o nuove strutture di materiali (come per la cattura di CO2). In questa fase si ottimizzano anche i piani sperimentali e si sviluppano i primi modelli surrogati (surrogate models) per emulare simulatori fisici computazionalmente costosi.
- Fase prototipale e pilota: quando si dispone di più dati in quasi Real-time, si sviluppano modelli per identificare anomalie e ottimizzare i parametri di processo. Un esempio è l’utilizzo del Reinforcement learning (RL) per identificare i Set point ottimali che massimizzino una cifra di merito (per esempio, una resa o un’efficienza di un sistema operativo) sul lungo periodo, attraverso un processo di Trial and error in ambiente simulato.

- Fase dimostrativa e deploy: nella fase finale, l’obiettivo è l’ingegnerizzazione dei modelli Data driven. Si sviluppano dashboard per il monitoraggio in Real-time e si lavora costantemente per arrivare a un digital twin della tecnologia.
L’Optimal Experimental Design (OED)
Uno dei focus principali nell’applicazione dell’AI in ricerca e sviluppo è l‘Optimal Experimental Design (OED), un’evoluzione del classico Design of Experiment (DOE).
Il DOE è un metodo che permette di pianificare ed eseguire esperimenti in modo strutturato, analizzando simultaneamente diverse variabili (come temperatura, pressione, concentrazione dei reagenti) per ottenere una comprensione quantitativa del sistema con meno esperimenti.
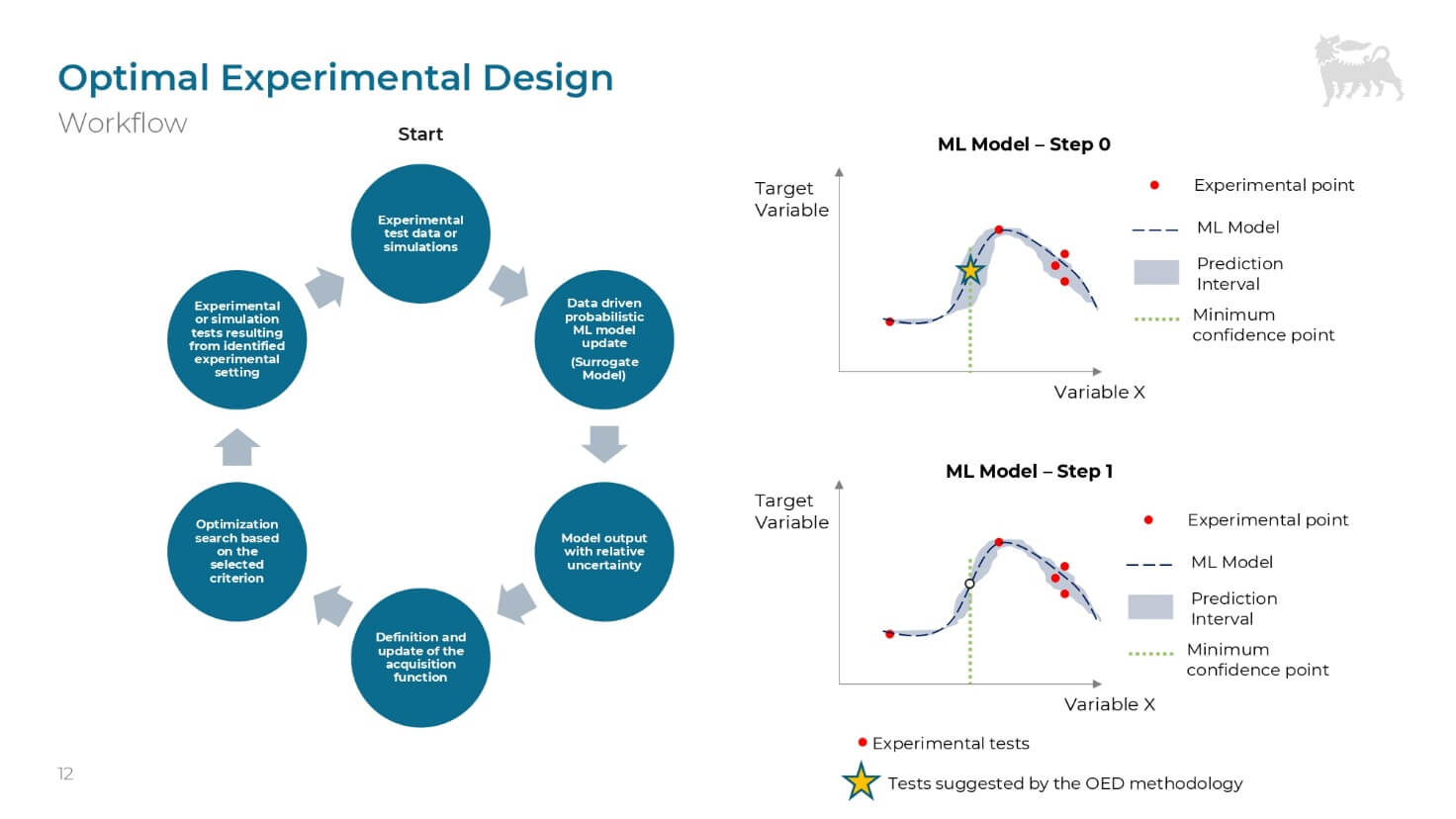
“L’OED trasforma questo approccio fisso in una strategia dinamica e adattativa”, spiega Francesco Cannarile, sviluppatore presso l’AI Center of Excellence di Eni. Che rileva: “differenza del DOE classico, il cui piano sperimentale è definito a priori, l’OED aggiorna il modello dopo ogni esperimento e suggerisce il passo successivo più utile, rendendosi più flessibile ed efficiente, e capace di modellizzare comportamenti complessi e non lineari”.
Il ciclo OED si basa su un Learning loop che comprende varie fasi e operazioni:
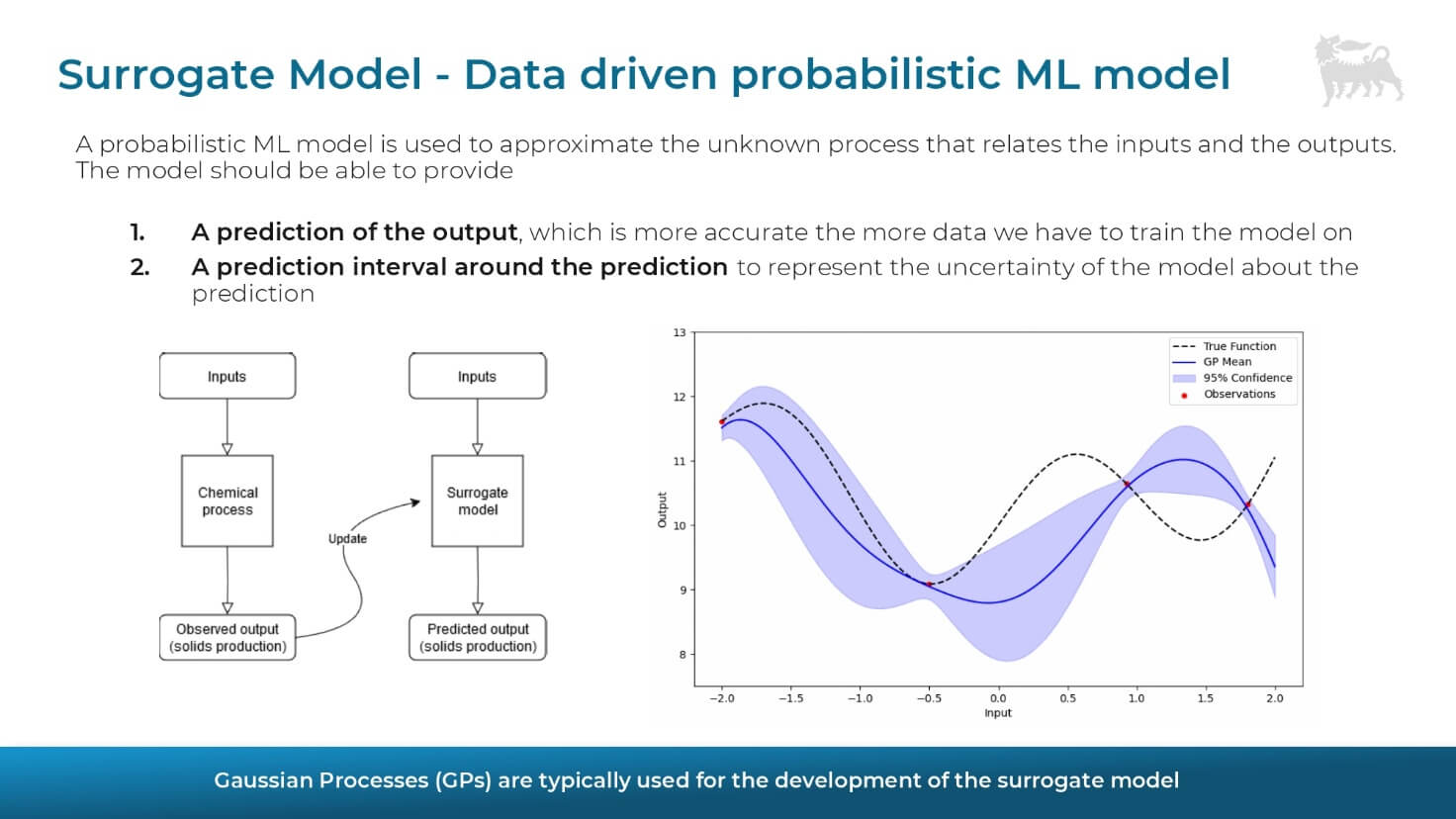
- Modellizzazione iniziale: una conoscenza iniziale rappresentata da un modello probabilistico (spesso basato su Gaussian Processes – GPR) che non fornisce solo previsioni, ma quantifica anche l’incertezza intorno alla previsione.
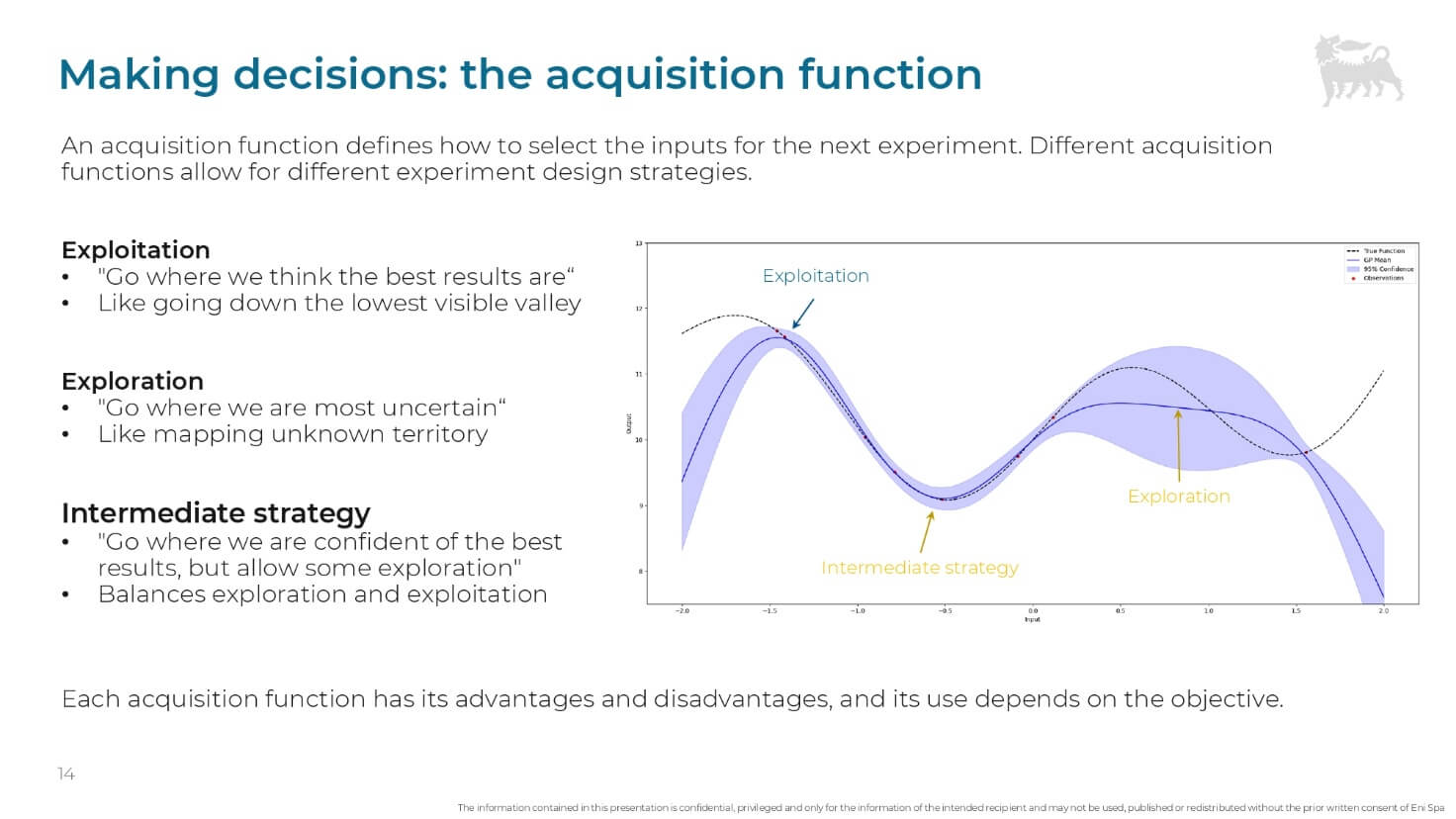
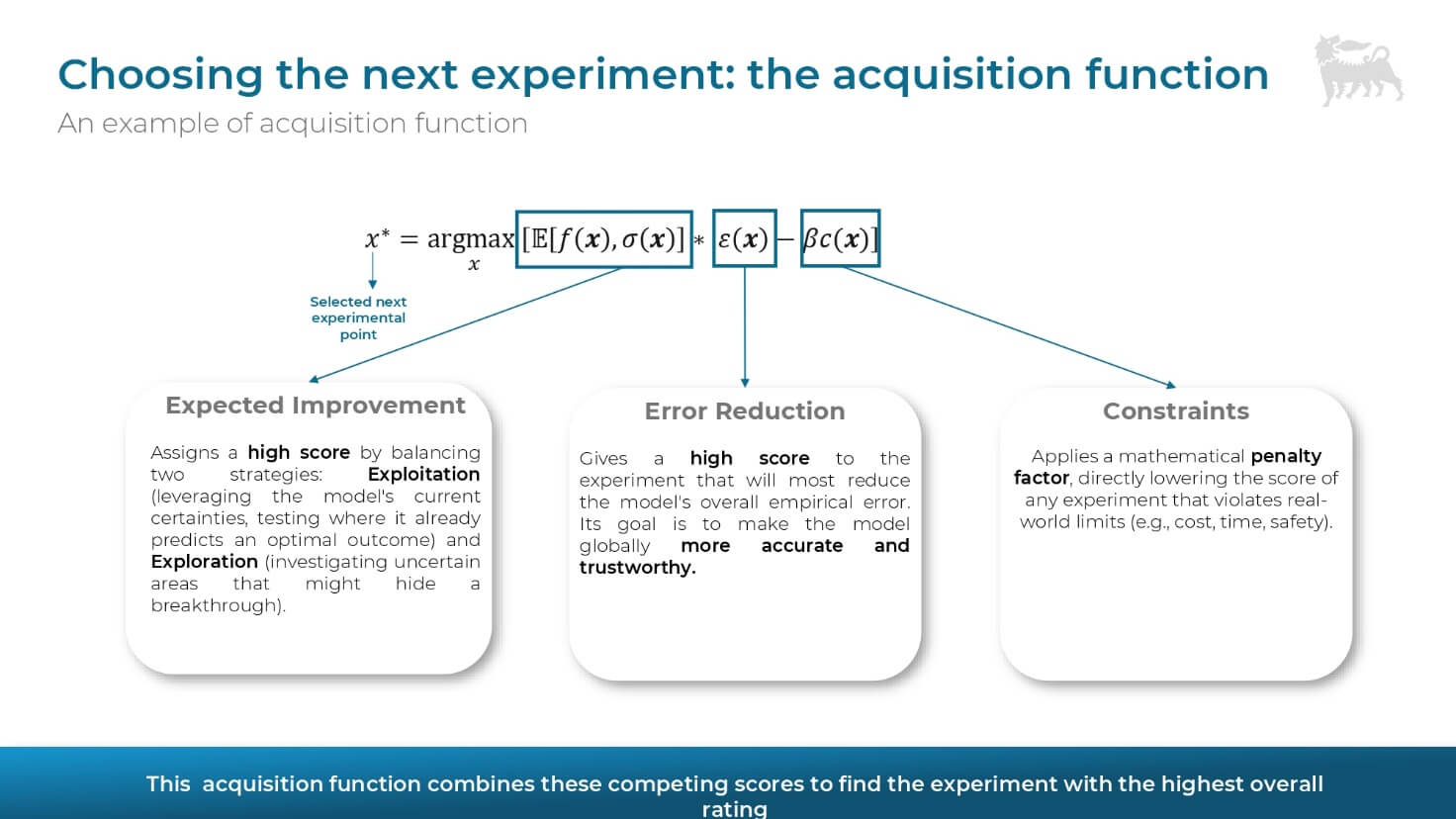
- Scelta ottimale: invece di procedere casualmente, un algoritmo di ottimizzazione utilizza una funzione di acquisizione (acquisition function) che identifica l’esperimento che massimizzerà il valore informativo.
- Bilanciamento di Exploitation ed Exploration: la funzione di acquisizione bilancia due approcci, l’Exploitation (concentrarsi su aree dove il modello prevede i migliori risultati) ed Exploration (esplorare gli input dove il modello presenta la maggiore incertezza).
Aggiornamento del modello: il nuovo dato sperimentale riduce l’incertezza, e il ciclo si ripete.
È fondamentale che la funzione di acquisizione possa anche tenere conto di vincoli reali, penalizzando esperimenti che violano limiti di costo, tempo o sicurezza. Inoltre, lo sviluppo di moduli di explainable AI è essenziale per capire come le diverse variabili (input) contribuiscono effettivamente all’output.
Ottimizzare il pretrattamento delle biomasse
Un esempio concreto di applicazione dell’OED “si ha nel settore del Biorefinering, in particolare per l’ottimizzazione del pretrattamento delle bio-cariche non convenzionali”, rileva Roberto Grana, esperto in sviluppo di processo e scale-up di Eni. Queste bio-cariche (oli vegetali, grassi animali, oli residui) presentano un alto contenuto di contaminanti (come metalli, fosforo, cloro) che devono essere rimossi per proteggere i processi a valle, come la tecnologia proprietaria di Ecofining che produce HVO (biodiesel).
L’obiettivo dello sviluppo è triplice: ottenere un’alta efficienza di rimozione, mantenere un processo semplice (poche operazioni unitarie) e garantire la flessibilità nel trattare biocariche molto diverse tra loro.
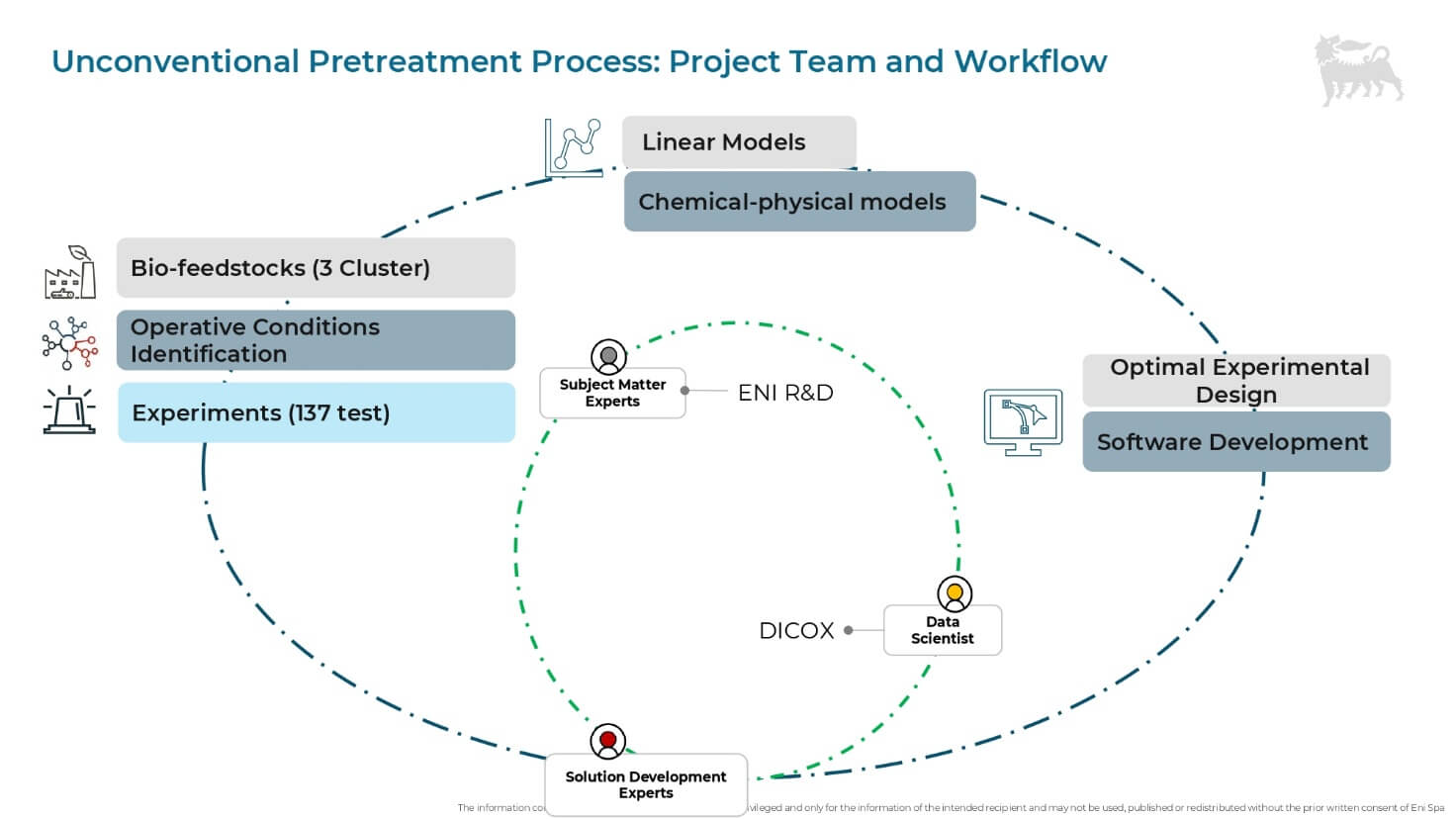
“Il progetto è stato di natura multidisciplinare”, sottolinea Grana, “coinvolgendo esperti di ricerca e sviluppo, laboratori, specialisti in modellazione chimico-fisica e data scientist. Sono stati analizzati circa 137 esperimenti, sei parametri di condizioni operative e 17 parametri che caratterizzano la bio-carica, come composizione, densità e altri fattori”.
La prima fase di agglomerazione dati, supportata dal machine learning, ha permesso di pulire i dati e identificare le variabili più sensibili. È stato quindi sviluppato un modello Data driven (utilizzando, ad esempio, il Gaussian Process Regressor – GPR) che correla l’efficienza di rimozione degli inquinanti con i parametri di input.
L’impatto del Digital boost è stato potenziato dallo sviluppo di una web app custom che funge da repository centrale e permette a tutti i membri del Team di visualizzare i risultati, archiviare gli esperimenti e anche effettuare nuove predizioni o loop OED individuali, accelerando così la velocità di pensiero e ragionamento sui dati.
Monitoraggio granulare di impianti fotovoltaici
All’interno del Gruppo Eni, l’AI sta anche migliorando la gestione e la produttività degli impianti fotovoltaici su scala industriale, un altro settore in rapida evoluzione e strategico per raggiungere il traguardo Net Zero 2050.

L’obiettivo delle attività di Operational Maintenance (O&M) è massimizzare la produttività dei sistemi, riducendo i tempi di inattività e velocizzando l’identificazione di Under performance, guasti e malfunzionamenti. Gli impianti moderni, ad esempio, possono estendersi per 5 km (paragonabili alla circonvallazione esterna di Milano) e contenere circa mezzo milione di moduli fotovoltaici, come nel caso di un impianto da 250 MW.
“Il monitoraggio tradizionale, basato su KPI aggregati a livello di intero impianto e su base mensile, è limitato e approssimativo”, fa notare Giacomo Gorni, specialista AI di Eni per l’innovazione nel settore delle energie rinnovabili: “gli strumenti di monitoraggio più diffusi e meno evoluti tipicamente arrivano al livello dell’inverter, o sottocampo, quindi circoscrivendo l’area di localizzazione del disservizio a una superficie paragonabile a quella della Stazione Centrale di Milano”.
L’applicazione di algoritmi evoluti e data science “consente invece di scendere a un livello di dettaglio molto più granulare, fino al combiner box, permettendo di localizzare un problema in una porzione molto più ristretta dell’impianto fotovoltaico, metaforicamente, passando dalla superficie dell’intera stazione per focalizzarsi su un singolo binario”, rimarca Gorni.
La sfida dei fattori mascheranti
Una delle maggiori sfide nell’analisi dei dati di campo è la presenza di fattori esogeni che mascherano l’interpretazione del dato di produzione. Questi fattori includono: variabilità ambientale (come i livelli di irraggiamento solare istantaneo, temperatura, vento) e il lato rete elettrica, in caso di limitazioni di potenza (curtailment) imposte dal Gestore di Rete (TSO) per congestione o sbilanciamento tra produzione e consumo.

Una banale nuvolosità o una limitazione di rete mascherano il dato, rendendo complessa l’identificazione di un problema fisico. Ad esempio, i periodi di bassa performance in un impianto fotovoltaico possono essere dovuti alla congestione della rete causata dalla produzione eolica nei mesi invernali, un fenomeno che rende l’interpretazione del KPI tradizionale “completamente misleading” (fuorviante).
Dati puliti e KPI evoluti
Per superare questi limiti, è essenziale una rigorosa pulizia e categorizzazione dei dati, non solo statistica ma con impatto fisico. Sono state messe in campo routine per scorporare effetti fisici (come ombreggiamento, comportamento degli impianti in temperatura, risposta angolare) ed eventi particolari (come limiti degli equipment, clipping degli inverter, curtailment).
Solo dopo questa pulizia, si ottiene una correlazione fisica affidabile tra irraggiamento e potenza degli impianti fotovoltaici.

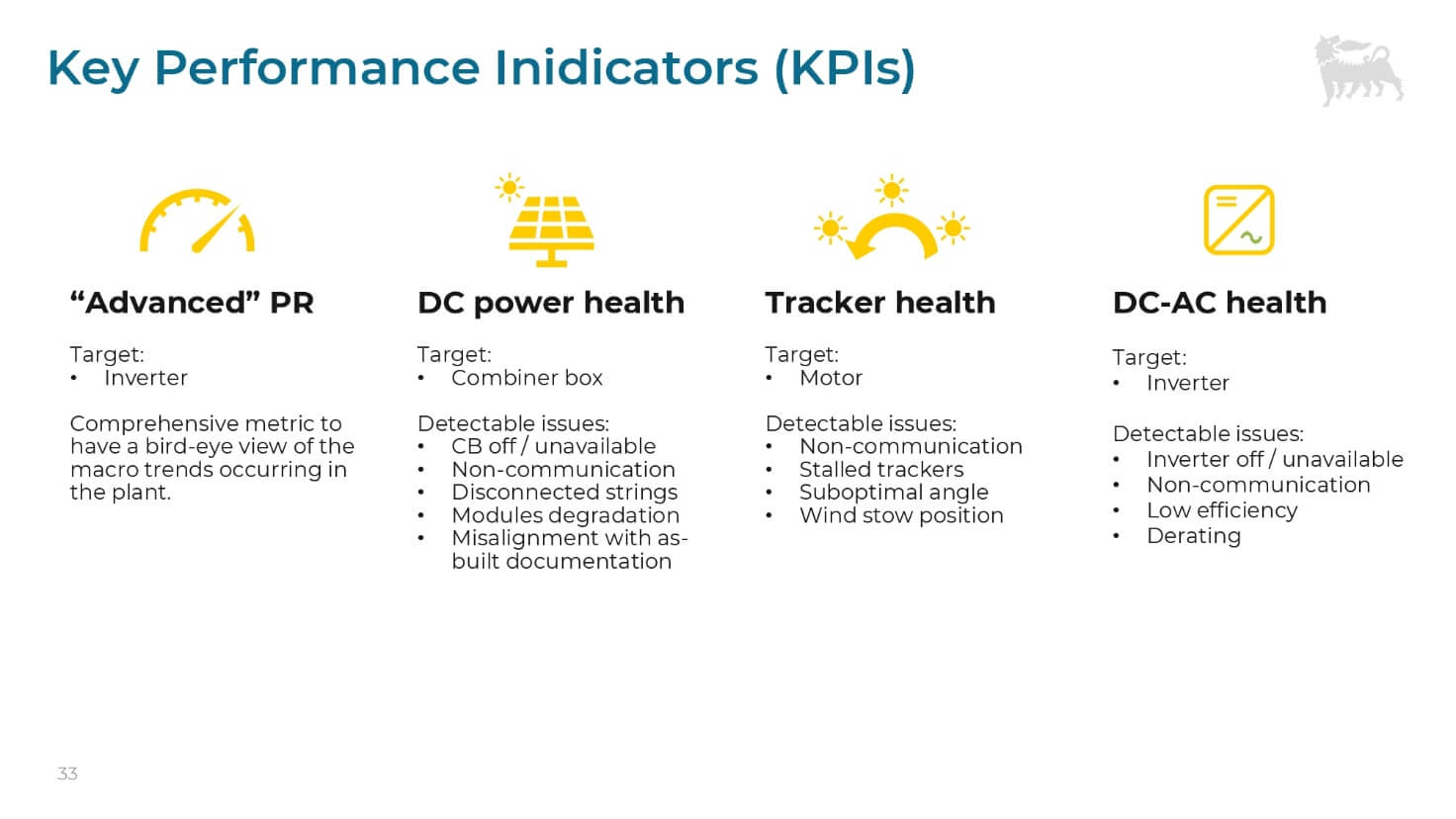
Sono stati sviluppati KPI evoluti (come un performance ratio corretto e ottimizzato) che permettono di scorporare le cause delle Under performance in categorie specifiche (moduli, inseguitori – tracker health, inverter).
Fruibilità e azioni correttive
L’aspetto cruciale è la fruibilità. Data la quantità enorme di dati (più di 1.000 curve di Combiner Box al giorno in un grande impianto), il risultato sintetico deve essere di immediata comprensione per l’asset manager, senza che questi debba essere uno specialista degli algoritmi.
Per esempio, visualizzazioni come le Heatmaps (dove “verde è bene, rosso è male”) aiutano a tradurre l’analisi complessa in sintesi operativa. L’analitica di estremo dettaglio permette di dare non solo una descrizione e, in certi casi, una previsione del problema, ma anche una probabilità di causa.
Inoltre, l’automatizzazione dei processi porta alla generazione di una reportistica settimanale automatica che dà indicazioni sui problemi più urgenti, quantifica l’impatto e fornisce la probabile causa. Questo approccio garantisce che l’O&M contractor possa intervenire con azioni correttive in modo più efficace e mirato, riducendo i tempi e massimizzando il ritorno economico dell’intervento. I primi risultati mostrano che la piattaforma, testata su quattro impianti per 650 MW totali, non ha riscontrato falsi positivi.
In pratica, la combinazione di data science, AI e modellazione fisica (il physical modeling è sempre essenziale per evitare inefficienze nell’interpretazione dei risultati) permette di “automatizzare in modo significativo la gestione di un portafoglio complesso e in rapida crescita”, sottolineano gli specialisti AI del Gruppo Eni, “assicurando che le indicazioni operative siano efficaci e pragmatiche”.





