“Equity as code”, ovvero l’equità inserita direttamente nel codice: il DataOps sta emergendo come leva strategica per affrontare il problema dei bias dell’’intelligenza artificiale.
Gli algoritmi di machine learning e di deep learning, com’è noto, assorbono le distorsioni cognitive (o pregiudizi) legate a etnia, genere, ricchezza, e le riproducono nelle loro correlazioni tra i dati.
Per mitigare o rettificare questi bias, occorre prima individuarli attraverso un monitoraggio costante dei modelli di apprendimento. La metodologia DataOps può aiutare a farlo, attraverso l’inserimento di appositi test di qualità automatizzati nella pipeline, per impedire che il modello distorto dai bias venga distribuito o per sostituirlo rapidamente. Test continui in un ciclo DataOps di miglioramento continuo.
Indice degli argomenti:
Cos’è DataOps
DataOps significa, letteralmente, “Operations dei dati”. È un insieme di pratiche, diventato metodo, che ridefinisce la gestione dei flussi di dati aziendali.
Per Gartner, è “una pratica di gestione collaborativa dei dati che si focalizza sul miglioramento della comunicazione, dell’integrazione e dell’automazione dei flussi informativi tra chi gestisce e chi utilizza i dati all’interno di un’organizzazione”. Per IBM, DataOps è “l’orchestrazione di persone, processi e tecnologie per fornire rapidamente ai cittadini dati affidabili e di alta qualità”.
In sintesi, DataOps riorganizza i percorsi dei dati dentro un’azienda, le pipeline: da silos verticali, a compartimenti stagni, a reti orizzontali e trasversali che si uniscono in un ciclo di miglioramento continuo.

Video –5 step per implementare una pratica DataOps – Hitachi Vantara (in inglese)
Il modello tradizionale di data management prevede fasi sequenziali, tra loro distinte e separate: la raccolta, l’analisi, la distribuzione sono le tre principali. Il modello DataOps le unisce in un flusso di monitoraggio, integrazione e distribuzione continui, basato su automazione e personalizzazione. La pipeline è infatti automatizzata da un capo all’altro (end-to-end).
DataOps deriva dal DevOps, la metodologia che ha riorganizzato la gestione del ciclo di vita del software. Come il DevOps, anche il DataOps è espressione di lean management e metodo Agile: la “gestione snella” punta ad “alleggerire” i processi eliminando sprechi, sovraccarichi per persone e risorse, variazioni impreviste del flusso produttivo; lo sviluppo agile ad accelerare le procedure attraverso il lavoro di squadra e l’iterazione di precisi passaggi di qualità.
Il “miglioramento a piccoli passi” (kaizen) che è anche alla base del lean management.
Come funziona
Il DataOps si basa su un’efficiente gestione del controllo del codice sorgente della pipeline, su un continuo testing di modifiche e comportamento dei dati, su una piattaforma di distribuzione ripetibile e coerente, ovvero non dispersa in ambienti differenti, ma centralizzata in un unico repository.
Le maggiori pratiche nel DataOps sono quindi integrazione e distribuzione continua.
Integrazione continua significa la possibilità di modificare o aggiornare la pipeline in qualsiasi momento, anche in parallelo, da parte di più persone contemporaneamente. La copia del codice che viene modificata o aggiornata non intacca l’originale, che continua a funzionare, ma viene salvata all’interno del sistema di controllo delle revisioni. Il nuovo codice viene quindi testato.
I test di verifica non sono eseguiti manualmente, ma attraverso specifiche suite, applicazioni software in grado di rilevare le logiche di input, output e analisi del modello nonché la funzionalità rispetto agli obiettivi stabiliti. È in questa parte di processo che si verifica l’equity as code, quando prevista.
Se i test hanno avuto esito positivo, il codice viene unito al codice sorgente e distribuito in qualsiasi momento: è la distribuzione continua del DataOps.
Le modifiche al codice sorgente, l’attivazione di nuove pipeline, la loro distribuzione, i risultati dei test di verifica possono essere oggetto di notifica a tutti gli interessati in tempo reale: un DataOps efficace non può fare a meno della gestione collaborativa delle informazioni.
Il team DataOps è composto dai manager e dagli utenti che richiedono le informazioni e che sono chiamati a collaborare, come i data scientist e i data analyst.
Tra i manager DataOps: gli ingegneri dei dati, che si occupano del trattamento e dell’accessibilità delle informazioni; gli ingegneri DataOps che gestiscono rilascio, monitoraggio e automazione delle pipeline; gli architetti dell’informazione, che si occupano del framework e lo adattano agli obiettivi aziendali.
Tra gli utenti Data Ops, i data scientist che modificano gli algoritmi delle pipeline a seconda delle esigenze e i data analyst, che sintetizzano e condividono gli asset ricavati dai dati.
Obiettivi
L’obiettivo principale del DataOps è rendere disponibili i dati che servono, quando servono, a tutte le persone interessate.
Per raggiungere questo obiettivo, il DataOps:
- implementa e ottimizza un ciclo di gestione dai dati basato sul miglioramento continuo
- abilita l’accesso self-service ai dati;
- migliora la comprensione dei metadati utilizzati;
- automatizza il ciclo di gestione accelerando le consegne ma mantenendo la qualità dell’analisi e la compliance alle normative di settore;
- riduce i tempi delle procedure di gestione dei dati: pulizia, caricamento, elaborazione;
- riduce al minimo, e quando possibile elimina, i silos di dati;
- fornisce feedback puntuali sull’andamento della pipeline, che si giovano a loro volta dei contributi degli stakeholder;
- favorisce un clima di collaborazione tra IT, OT e le altre parti dell’azienda.
Implementazioni del DataOps
Per implementare il DataOps in un’azienda è importante partire da un piccolo progetto pilota per focalizzare al meglio gli obiettivi attesi, instaurare o implementare una cultura data-driven aziendale e potenziare le relative competenze.
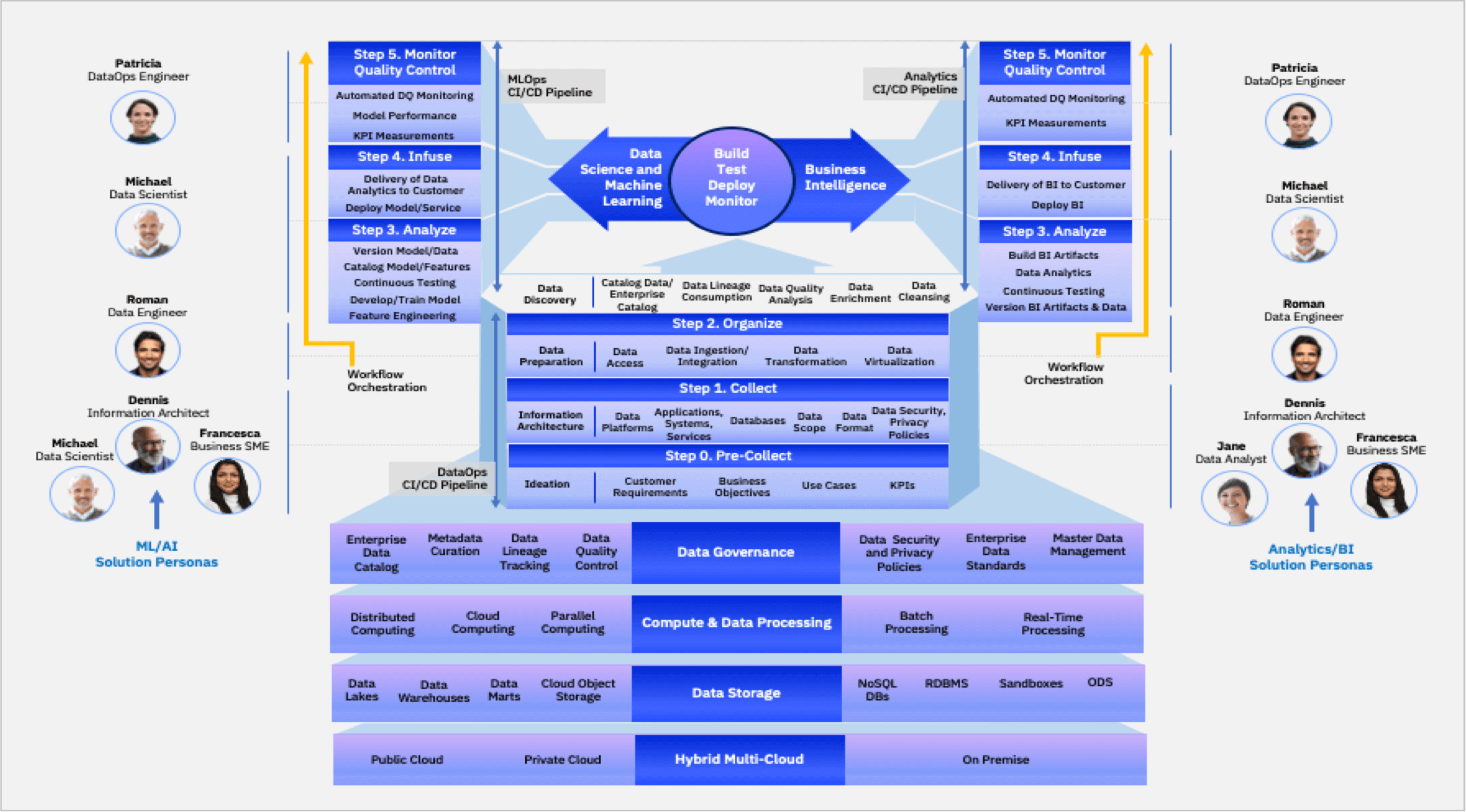
Per il DataOps Flipbook della Worldwide Community of Information Architects (WWCIA) di IBM, il DataOps si divide in sei fasi:
- Fase 0: pre-raccolta – La pianificazione del progetto con l’analisi di contesto TO-BE/AS-IS relativa a requisiti, obiettivi, risorse, applicazioni, KPI.
- Fase 1: raccolta – La definizione dell’architettura informativa più funzionale agli obiettivi e la riprogettazione dei flussi gestionali a partire dall’architettura in uso.
- Fase 2: organizzazione – L’individuazione dei dati utili e la loro organizzazione, con attenzione al data lineage, cioè il mantenimento delle fonte e della tracciabilità del dato.
- Fase 3: analisi – I dati vengono analizzati con algoritmi di machine e deep learning e le caratteristiche trovate vengono catalogate con appositi metadati. I modelli degli algoritmi vengono a loro volta salvati in due versioni, sorgente e copia, per favorire le modifiche
- Fase 4: infusione – I modelli vengono trasferiti nelle applicazioni attraverso implementazioni automatizzate
- Fase 5: monitoraggio controllo qualità – Controllo automatizzato delle pipeline per individuare eventuali errori e problemi.