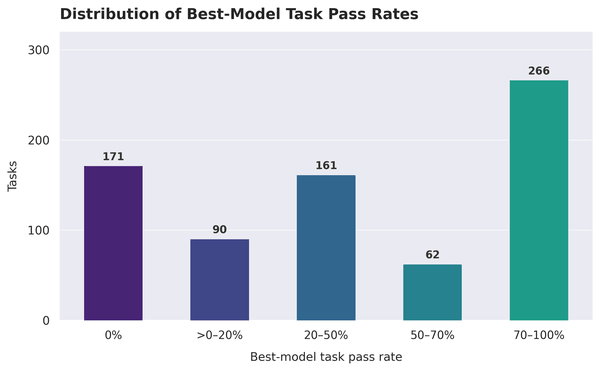
Settecentocinquanta richieste, scritte da scienziati con un dottorato e anni passati nei laboratori di aziende biotech e farmaceutiche, ciascuna formulata come la porresti a un collega di cui ti fidi: interpreta questi dati di spatial transcriptomics da un tumore della cervice e dimmi quali due terapie a bersaglio hanno più senso per questo paziente, smonta voce per voce il pacchetto regolatorio di una terapia genica per la distrofia di Duchenne e indica dove non regge, progetta i primer per assemblare in frame tre frammenti con un Golden Gate. Su questo materiale, il modello che se la cava meglio supera il 36,1% dei compiti. Centosettantuno task, il 22,8% del totale, non vengono risolti da nessuno dei cinque sistemi messi alla prova.
È il quadro che OpenAI ha pubblicato il 17 giugno 2026 insieme a LifeSciBench, un benchmark che prova a misurare una capacità diversa da quella che i test tradizionali catturano: quanto un modello sa fare ricerca nelle scienze della vita, e non quanto sa rispondere a una domanda di biologia. La distanza tra le due cose è il vero contenuto del preprint, firmato da OpenAI con Tacit Labs, e conviene tenere a mente da subito una nota che gli stessi autori mettono nero su bianco: il benchmark è costruito da chi produce anche alcuni dei modelli valutati, e il sistema che vince la classifica è un modello specializzato della stessa OpenAI.
Per chi deve decidere dove inserire questi sistemi in un flusso di ricerca e sviluppo, la fotografia conta più della graduatoria. Dice dove un modello regge il peso di una decisione scientifica, e dove invece restituisce risposte plausibili che un esperto, per ora, non può firmare.
Indice degli argomenti:
Un esame scritto da 173 scienziati
I numeri della costruzione raccontano già parecchio. Le 750 prove sono state scritte da 173 esperti, tutti con un dottorato in discipline come biochimica, biologia molecolare, immunologia, farmacologia o chimica medicinale, e tutti con almeno due anni di lavoro vero dentro l’industria biotech o farmaceutica. Ogni task è impostato come una conversazione tra colleghi: un prompt in linguaggio scientifico, gli artefatti che servono per rispondere, sequenze, strutture molecolari, immagini di microscopia, gel, file di strumenti, tabelle, PDF, e una risposta libera, non una crocetta.
Il pezzo che cambia la natura della valutazione sono le rubriche. Ne sono state scritte oltre 19mila, in media 25 per ogni compito, e ciascun criterio premia o penalizza un aspetto preciso della risposta: un fatto che andava citato, un passaggio di ragionamento che andava esplicitato, un valore quantitativo da centrare entro una tolleranza. Il punteggio finale è la somma dei punti divisa per il totale possibile, così una risposta può prendere credito parziale per il ragionamento corretto anche quando manca il bersaglio.
Ecco cosa distingue LifeSciBench dai benchmark a risposta secca: la stessa conclusione giusta vale in modo diverso a seconda di come ci si arriva, se il modello usa l’evidenza giusta, se dichiara le assunzioni, se comunica con il grado di certezza appropriato. Una risposta può centrare la conclusione generale e restare scientificamente incompleta, perché salta un caveat decisivo o non giustifica una raccomandazione.
La selezione è stata severa. Ogni task ha attraversato più cicli di revisione, in media sei passaggi automatici e almeno due round di revisione umana, con criteri ancorati a una risposta verificabile o a un consenso forte tra esperti, fissato ad almeno il 90% di accordo. Poi una validazione indipendente, condotta da 453 revisori diversi da chi aveva scritto le prove, il 97% con un dottorato, in media dodici anni di esperienza e quattordici pubblicazioni alle spalle. Su realismo, aderenza al ragionamento richiesto, fondatezza scientifica e utilità complessiva, l’accordo complessivo ha superato il 96% in ogni categoria.
La copertura è l’altra ragione per prendere sul serio questi numeri. Le prove si distribuiscono su sette workflow, dalla gestione dell’evidenza all’analisi, dal design e ottimizzazione al ragionamento, fino a validazione e operazioni, traduzione e comunicazione scientifica, e su sette domini biologici, dalla genomica alla chimica medicinale, dalla biologia strutturale alla bioinformatica clinica. La mappa di questa distribuzione mostra dove il benchmark si addensa: il blocco Design e ottimizzazione, da solo, raccoglie 258 task.
GPT-Rosalind davanti, i generalisti a ridosso
Cinque sistemi alla prova: GPT-5.4, GPT-5.5, GPT-Rosalind, Gemini 3.1 Pro e Grok 4.3, tutti valutati in modalità single-turn, una sola risposta per task, senza follow-up. In testa c’è GPT-Rosalind, modello specializzato sulle scienze della vita di cui OpenAI ha aperto le richieste di accesso, con un punteggio normalizzato di 0,576 e un pass rate del 36,1%. Dietro, due generalisti quasi appaiati, GPT-5.5 a 0,519 e Gemini 3.1 Pro a 0,515, poi GPT-5.4 a 0,479 e Grok 4.3 a 0,399.
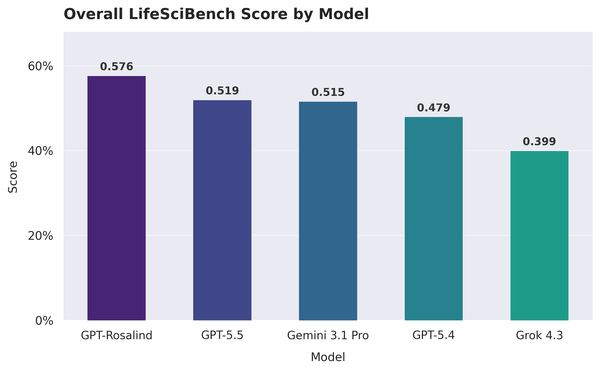
Due cose meritano attenzione, oltre alla classifica. La prima riguarda la soglia: il pass rate misura la quota di task in cui la risposta tocca almeno il 70% dei criteri della rubrica, una soglia dura, e su questa scala perfino il modello migliore lascia indietro quasi due terzi delle prove. La seconda riguarda la trama fine, che una media nasconde. GPT-Rosalind ha il punteggio più alto su 386 task dei 750, però Gemini 3.1 Pro guida in solitaria su 214 prove, segno di forze complementari. Un modello leggermente più debole nel complesso può restare il più adatto per un certo tipo di lavoro.
Che a vincere sia un sistema costruito apposta per il dominio, davanti a modelli di frontiera generalisti più recenti, è un dettaglio che chi valuta l’adozione farebbe bene a registrare. Lo scarto, però, resta misurato: dieci punti di pass rate sopra GPT-5.5, su un benchmark dove la soglia di successo è ancora lontana per tutti.
Dove l’evidenza ha un confine netto
Le aree dove i sistemi di frontiera vanno meglio sono coerenti tra loro, e dicono qualcosa di preciso. Sui task di traduzione, quelli che collegano l’evidenza preclinica o biologica alle implicazioni cliniche, alla sicurezza, al disegno di un trial, GPT-Rosalind tocca un punteggio medio di 0,712. Sulla comunicazione scientifica, il riassumere e spiegare risultati per un pubblico definito, arriva a 0,718, anche se qui la categoria è piccola, appena nove task, e va letta con prudenza.
Il salto rispetto a GPT-5.5 è marcato proprio in queste zone. Nel comunicato OpenAI riporta il pass rate sulla comunicazione scientifica che passa dal 56,3% al 71,1%, e quello sulla traduzione che sale dal 36,8% al 57,7%. Sui criteri che chiedono output utili e azionabili per un esperto il punteggio va dal 29,1% al 44,7%, e su quelli che richiedono di gestire incertezza e caveat dal 29,3% al 44,8%.
A livello di singolo criterio, i guadagni maggiori di GPT-Rosalind su GPT-5.5 arrivano sullo spiegare meccanismi, sul progettare esperimenti e sul criticare o validare un’analisi. Sono tutte cose che chiedono di andare oltre il richiamo di nozioni, di interpretare l’evidenza e pesare le assunzioni per arrivare a qualcosa di utile a una decisione. I modelli danno il meglio quando il task ha un confine chiaro nell’evidenza e domanda un giudizio scientifico strutturato.
È il territorio del knowledge worker esperto, quello dove un assistente può davvero alleggerire il carico.
Artefatti e output esatti: i due limiti strutturali
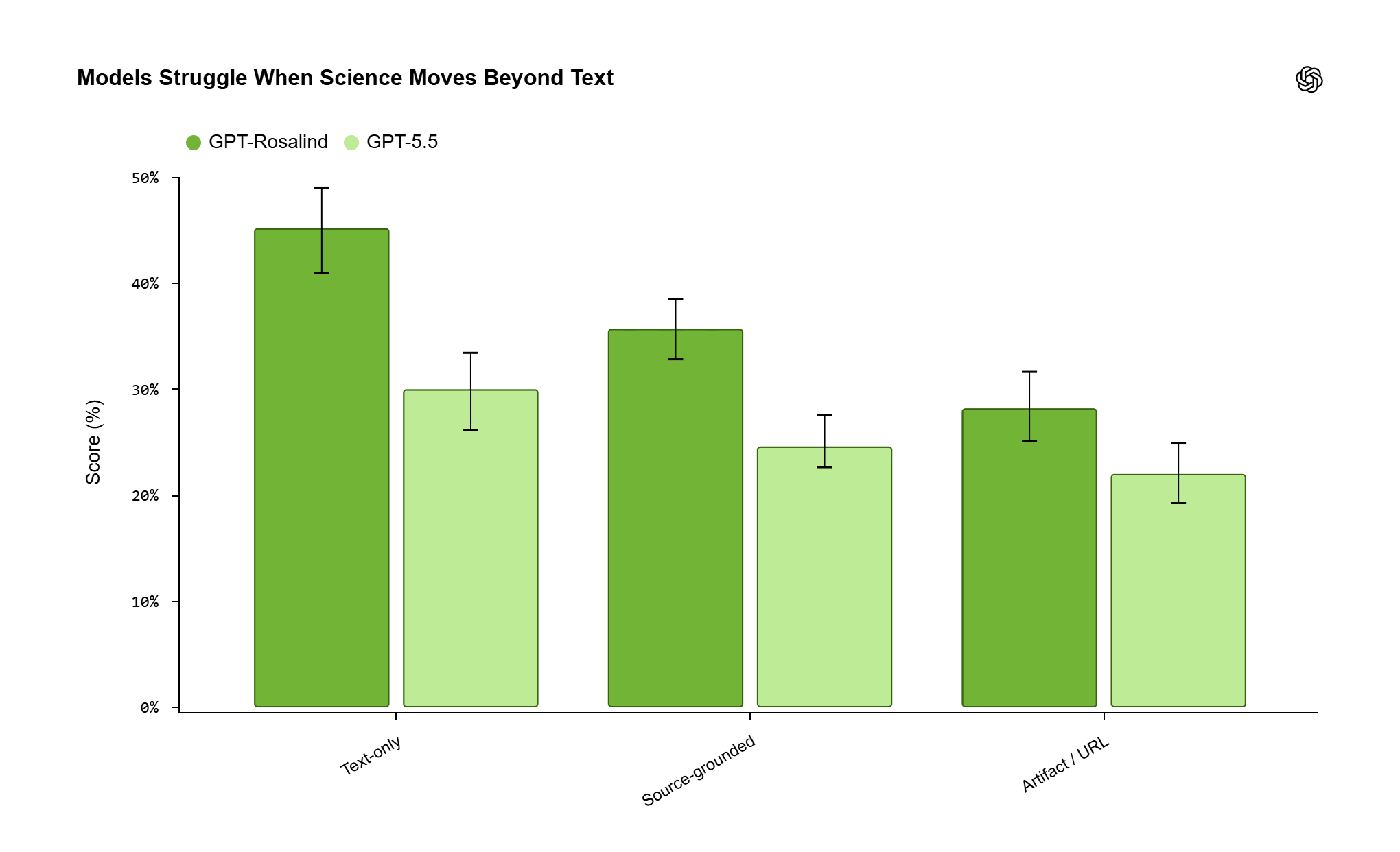
Il rovescio della medaglia è dove i modelli diventano inaffidabili, e qui la lezione è la più rilevante per chi lavora con dati reali. I task che richiedono di leggere un artefatto allegato, un file grande, una figura complessa, un dataset, sono molto più duri di quelli di solo testo. Per GPT-Rosalind il pass rate cala dal 45% circa sulle prove testuali a poco più del 28% su quelle che richiedono artefatti o link esterni. GPT-5.5 mostra la stessa curva, da circa il 30% al 22%.
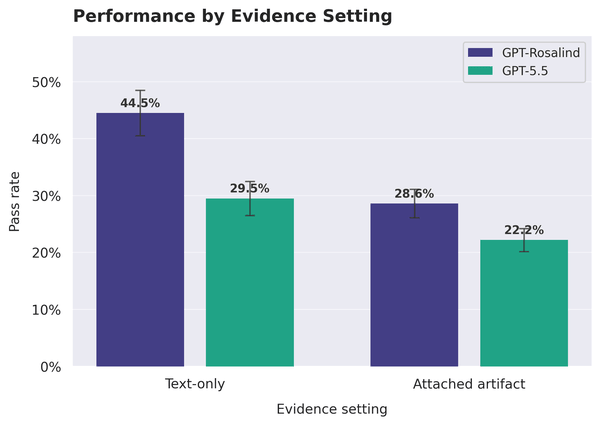
Il divario resta anche per il modello migliore, e questo basta a inquadrare l’uso degli artefatti come un limite strutturale del momento. Il punto di rottura ricorre quando il sistema deve estrarre l’informazione giusta da un file ingombrante o da una figura affollata e poi portarla dentro una decisione scientifica finale.
C’è una seconda crepa, sul formato della risposta. Quando il task chiede output esatti, una sequenza genomica o una struttura chimica da consegnare così com’è, i punteggi crollano per tutti. Sui criteri di sequenza e struttura il successo va dal 46,9% di GPT-Rosalind al 18,0% di Grok, sui task numerici GPT-Rosalind si ferma al 14,8%, sulla generazione di costrutti al 27,3%, con un miglioramento di appena un millesimo rispetto a GPT-5.5. Il progresso, su queste prove, si concentra sul ragionamento generale e quasi non tocca l’uso preciso dei formati scientifici specializzati.
E conta, questo limite, perché molti flussi reali delle scienze della vita hanno bisogno proprio di output azionabili e precisi: una sequenza pronta per il disegno di un donatore CRISPR/HDR, un costrutto destinato a un passaggio a valle.
Tra risposta plausibile e decisione utilizzabile
Resta il fenomeno più istruttivo, quello che spiega perché LifeSciBench riporta due metriche e non una. I modelli, spesso, fanno metà del percorso: identificano l’evidenza giusta, impostano il ragionamento, e poi non chiudono. Per GPT-Rosalind ci sono 109 task con un pass rate sotto il 20% che hanno comunque raccolto almeno metà dei punti della rubrica. Sono risposte scientificamente verosimili che falliscono per un motivo specifico, saltano un vincolo, usano l’evidenza sbagliata, lasciano un calcolo a metà, o non collegano il ragionamento intermedio a una conclusione operativamente utile.
Letto dal lato di chi adotta questi sistemi, è la differenza tra un assistente che produce una bozza credibile e un collaboratore di cui ti puoi fidare per una decisione. Il limite dei modelli di frontiera, oggi, sta meno nella conoscenza biologica e più nell’affidabilità sotto i vincoli della ricerca reale: usare bene gli artefatti, e trasformare un ragionamento parziale in una decisione completa che un esperto può davvero prendere e portare avanti.
Per chi deve adottare questi strumenti, la mappa conta più della classifica. Su 750 prove ne restano 171 che nessun modello risolve, 261 con il migliore sotto il 20% di pass rate, e il blocco più ostico si concentra su Design, ottimizzazione e analisi, che insieme valgono il 60,9% dei task più difficili. La distribuzione dei risultati migliori, task per task, lo mostra senza giri di parole.
Sono le aree dove la ricerca chiede precisione operativa, e dove la collaborazione tra esperto e macchina resta per ora a presidio umano forte. Non a caso, lo stesso 17 giugno OpenAI raccontava anche di un chimico AI quasi autonomo che migliora una reazione difficile in chimica medicinale, un risultato di deployment in un contesto delimitato che vive in una dimensione diversa da quella di un esame a turno singolo.
La domanda che resta aperta riguarda meno il valore di questa classifica, destinata a cambiare alla prossima release, e più la traduzione: quanto i progressi misurati su un test single-turn si trasformano in produttività dentro un laboratorio, dove il lavoro è iterativo, fatto di chiarimenti continui e nuovi esperimenti di verifica. Gli stessi autori lo riconoscono e indicano la direzione, correlare i risultati del benchmark con studi di deployment nei flussi di ricerca veri.
Finché quel ponte non viene costruito, il dato che conviene tenere a mente è meno il punteggio del modello in testa e più quel 22,8% di compiti che oggi nessuno porta a casa. Ed è senza dubbio da lì che vale la pena guardare alla prossima generazione di modelli: quanto di quel margine riusciranno a chiudere, e quanto invece continuerà a chiedere la mano di uno scienziato in carne e ossa?






Partecipa alla community