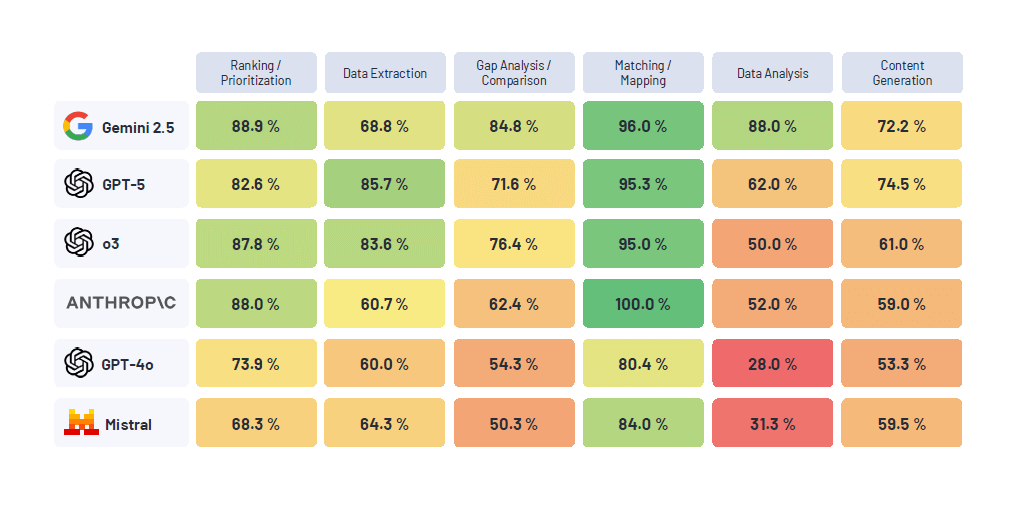
Oltre un milione di aziende nel mondo usa ormai l’intelligenza artificiale per aumentare efficienza e valore. Nonostante ciò, molte organizzazioni riscontrano risultati inferiori alle aspettative. Una delle cause principali è l’assenza di strumenti che traducano obiettivi strategici in comportamenti affidabili dei modelli.
Indice degli argomenti:
Il ruolo degli evals secondo OpenAI
In OpenAI, uno degli strumenti chiave sono gli evals: metodi per misurare e migliorare la capacità di un sistema di soddisfare criteri specifici. Come un documento di requisiti prodotto, gli evals eliminano ambiguità, rendendo concreti gli obiettivi e riducendo errori ad alto impatto, fornendo un percorso misurabile verso un ROI più alto.
Frontier evals e contextual evals
I frontier evals misurano la qualità dei modelli in vari domini e accelerano la loro evoluzione. Tuttavia, non coprono tutte le sfumature necessarie nei flussi operativi specifici di un’azienda. Per questo OpenAI sviluppa anche contextual evals, ovvero valutazioni pensate per prodotti, workflow o settori specifici. È un approccio che anche i leader aziendali dovrebbero adottare, creando test su misura per le proprie esigenze.

Un framework pratico: specificare → misurare → migliorare
Gli evals seguono un ciclo iterativo e continuo: definire cosa significa “eccellente”, misurare il sistema in condizioni realistiche e migliorarlo sulla base degli errori emersi.
1. Specificare: definire cosa significa “grande qualità”
Tutto parte da un team ristretto con competenze tecniche e di dominio, capace di descrivere in modo semplice lo scopo del sistema AI: per esempio, “Convertire email qualificate in appuntamenti, mantenendo la coerenza del brand”.
Il team deve mappare l’intero workflow, identificando decision point e criteri di successo. Questo processo genera un golden set di esempi, aggiornato nel tempo, che riflette il giudizio degli esperti su cosa sia un output eccellente.
La fase iniziale è disordinata e iterativa: analizzare 50–100 output iniziali aiuta a costruire una “tassonomia degli errori”, una lista dettagliata dei problemi da monitorare.
2. Misurare: testare in condizioni reali
La seconda fase consiste nel costruire un ambiente di test che rispecchi le condizioni reali, evitando demo semplificate o prompt playground. Il sistema va valutato usando il golden set, includendo casi limite che potrebbero risultare costosi se mal gestiti.
Sono utili rubriche per giudicare gli output, ma vanno bilanciate per non dare peso eccessivo a dettagli superficiali. In certi casi servono metriche tradizionali; in altri bisogna crearne di nuove.
Alcune valutazioni si possono scalare utilizzando un LLM grader, ossia un modello che giudica gli output come farebbe un esperto. Ma l’intervento umano resta fondamentale per audit e correzioni continue. Evals e monitoraggio devono proseguire anche dopo il lancio del sistema.
3. Migliorare: imparare dagli errori
Il miglioramento continuo è il cuore del processo. Gli errori rilevati portano a ottimizzare prompt, dati, strumenti o lo stesso eval. Man mano che emergono nuove categorie di errore, queste vengono incorporate per creare iterazioni sempre più raffinate.
Costruire un data flywheel è essenziale: registrare input e output, far revisionare i casi ambigui agli esperti e integrare questi giudizi nel sistema. In questo modo l’azienda accumula un dataset ricco, contestuale e difficile da replicare, un reale vantaggio competitivo.
Gli evals vanno mantenuti e stressati nel tempo, perché anche obiettivi, modelli e dati evolvono.
Evals e A/B testing: non alternative, ma alleati
Per applicazioni esterne, gli evals non sostituiscono i classici A/B test: li affiancano. Ogni metodo fornisce insight complementari su come le modifiche influenzano la performance reale.
Perché gli evals sono importanti per i leader aziendali
Ogni rivoluzione tecnologica ridefinisce il concetto di eccellenza operativa. Se gli OKR e i KPI hanno rappresentato la bussola nell’era dei big data, gli evals sono la naturale estensione per l’era dell’AI.
Lavorare con sistemi probabilistici impone nuove forme di misura e trade-off più complessi. La precisione non è sempre necessaria; a volte serve flessibilità. Ma occorre sempre chiarezza sugli obiettivi.
Gli evals richiedono rigore, visione e capacità qualitative: se ben realizzati, diventano un vantaggio competitivo unico, trasformando il know-how aziendale in un asset scalabile.
Alla base, gli evals insegnano una lezione chiave: le competenze manageriali sono anche competenze AI. Definire obiettivi chiari, dare feedback, esercitare giudizio sono abilità ancora più importanti nell’era dei modelli generativi.
Sebbene i framework siano ancora in evoluzione, è già possibile iniziare: definire il problema, individuare un esperto di dominio, riunire un piccolo team e, se si lavora con API OpenAI, consultare la documentazione di piattaforma.





Partecipa alla community