GLM 5.2 è un LLM open weight rilasciato sotto licenza MIT, una delle licenze open più permissive in circolazione. Chiunque può scaricare il modello, modificarlo, addestrarlo ulteriormente e usarlo a fini commerciali, senza pagare royalty e senza restrizioni d’uso o vincoli geografici. Questa release è avvenuta proprio a pochi giorni dal veto imposto dall’amministrazione statunitense all’export dei modelli di punta di Anthropic, Fable 5 e Mythos 5, che ne ha bloccato l’accesso ai cittadini stranieri.
La risposta orientale ai modelli di frontiera arriva, quindi, sul mercato con un tempismo ideale, proprio quando le imprese europee iniziano a guardarsi intorno per trovare alternative ai colossi americani.
GLM 5.2 è un modello molto performante, e anche quando usato su infrastruttura cloud, costa una frazione di Claude Opus o GPT. Quando si tratta di integrare un nuovo strumento in una pipeline di automazione, però, il costo estratto dalle tabelle del pricing non è l’unico fattore rilevante, è necessario valutare la sua efficienza sul campo ed eventuali problemi di qualità e conformità.
Indice degli argomenti:
GLM 5.2, un po’ di storia
Z.ai nasce nel 2019 come spin-out della Tsinghua University di Pechino e diventa in breve la prima azienda al mondo di grandi modelli linguistici a quotarsi in borsa. Negli ultimi mesi ha imposto un ritmo di rilascio aggressivo, con una specializzazione marcata sul codice e sui sistemi agentici che eseguono compiti in autonomia utilizzando anche strumenti esterni. La famiglia GLM-5 è stata addestrata interamente su chip Huawei Ascend 910B, senza hardware NVIDIA, e questo è un dettaglio importante in ottica geopolitica.
GLM 5.2 è il modello di punta di Z.ai e utilizza un’architettura MoE (Mixture-of-Experts). Dei circa 744 miliardi di parametri totali del modello, solo una porzione, intorno ai 40 miliardi, si attiva per ogni token elaborato. La quantità di testo che il modello riesce a tenere in memoria durante una conversazione (context window) è di un milione di token, equivalenti a diverse centinaia di migliaia di parole.
La generazione in uscita arriva fino a circa 131.000 token, anche se alcuni provider possono impostare tetti più bassi. GLM 5.2 offre, poi, due livelli di ragionamento, High e Max, che bilanciano velocità e profondità di ragionamento. Il modello, non essendo multimodale, lavora solo sul testo e non è in grado di elaborare immagini.
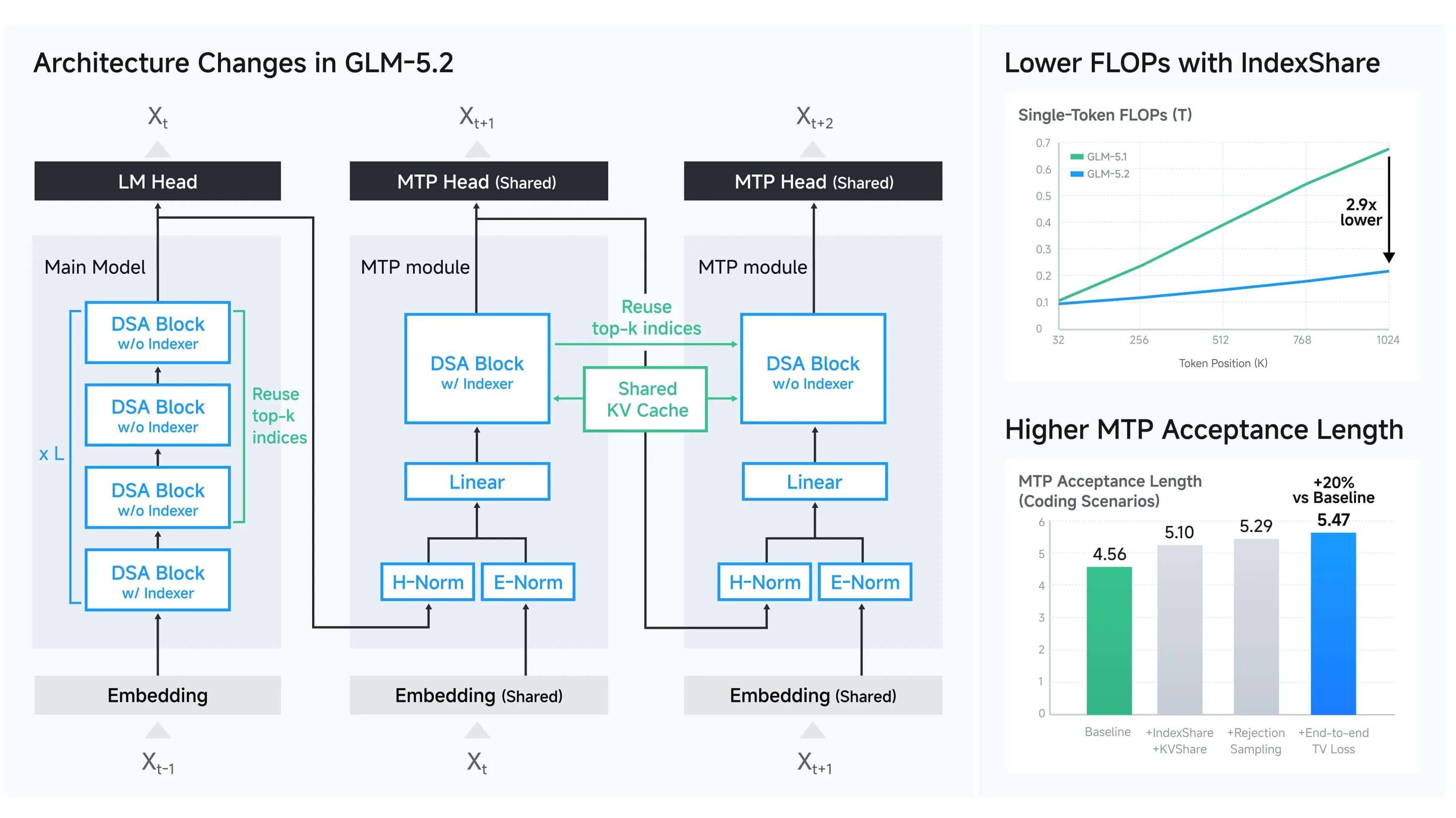
Sul piano architetturale ci sono due novità tecniche interessanti. La prima si chiama IndexShare, un meccanismo che permette di riutilizzare lo stesso indice del meccanismo di attenzione ogni quattro livelli del modello, riducendo di circa 2,9 volte le operazioni di calcolo per token quando il contesto è molto lungo.
La seconda è un aggiornamento del Multi-Token Prediction, una tecnica di decodifica speculativa che prova a indovinare più token in anticipo e, secondo Z.ai, allunga fino al 20% la sequenza accettata, accelerando la generazione.
I risultati di GLM 5.2 nei benchmark
I benchmark sono test standardizzati che misurano la capacità di un modello su compiti precisi, in modo da poterlo confrontare con altri. Z.ai ha pubblicato i risultati ottenuti al momento del rilascio, mentre una verifica indipendente è arrivata dalla società di analisi Artificial Analysis. I numeri seguenti combinano le due fonti; i dati riguardanti GLM 5.2 provengono dalla scheda ufficiale del modello e, per Claude Opus 4.8, dai risultati dichiarati da Anthropic.
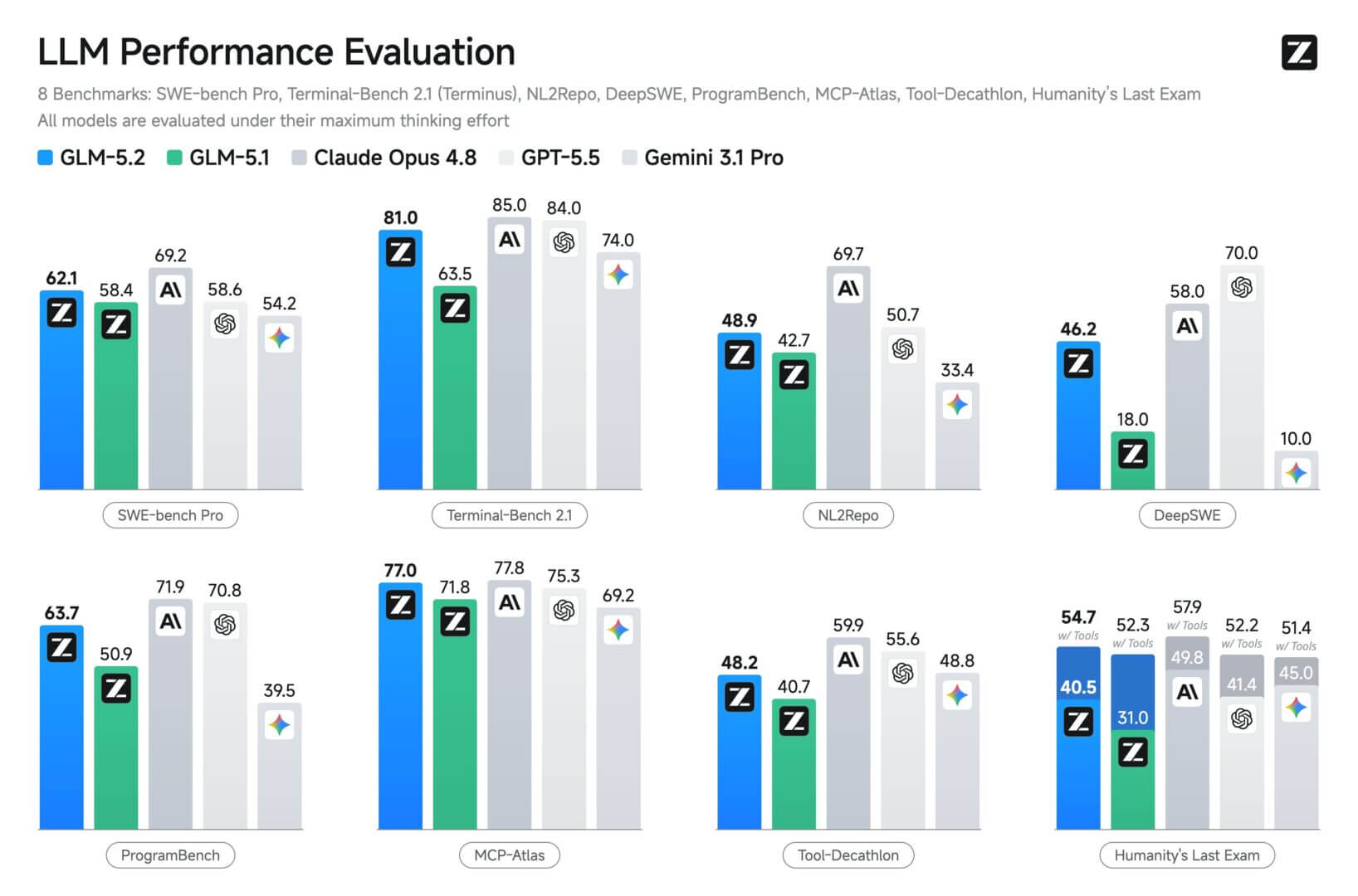
Secondo questi test, GLM 5.2 è oggi in cima al gruppo dei modelli open, ed è anche in grado di competere alla pari con modelli di frontiera sul ragionamento, addirittura superandoli in qualche test matematico. Nei test di Artificial Analysis, l’ultima versione di GLM ha totalizzato 51 punti, davanti a DeepSeek V4 Pro (44), MiniMax-M3 (44) e Kimi K2.6 (43).
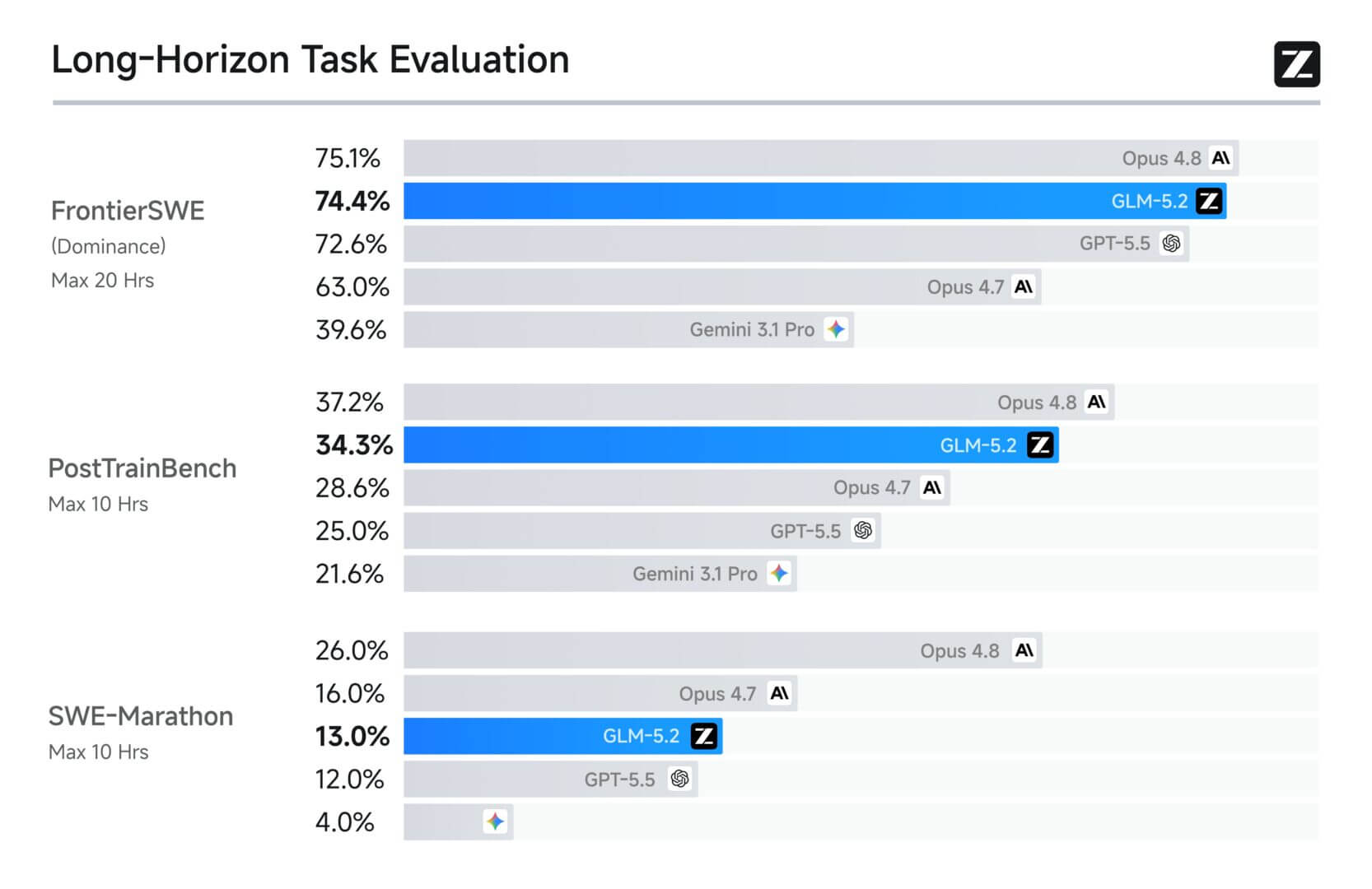
Sui compiti di coding più duri e lunghi, i modelli di frontiera mantengono un margine di vantaggio importante, ad esempio il divario su SWE-Marathon è di 13 punti contro 26 per Opus.
Quanto costa GLM 5.2?
Nella scelta di un modello i prezzi di listino delle API hanno un peso importante. Per milione di token Opus 4.8 costa 5 dollari in input e 25 dollari in output, mentre GLM costa 1,40 dollari per i token in input e 4,40 dollari per quelli in output. Entrambi hanno un meccanismo di cache che aiuta a controllare i costi. Quando si invia ripetutamente lo stesso contesto, per esempio un grande prompt di sistema fisso a ogni chiamata, la parte già elaborata viene fatturata a tariffa ridotta per entrambi i modelli.
I token in cache nel caso di Anthropic, hanno un costo di 0,50 dollari per milione, mentre per GLM questo costo si dimezza. Lo strumento di ricerca sul web integrato costa circa un centesimo di dollaro per utilizzo, oltre ai token della richiesta.
Un benchmark di lavoro agentico riportato da Latent Space ha misurato la spesa media per compito su un’attività complessa di conoscenza, stimando 31 dollari per Fable 5, 10,40 dollari per Opus 4.8, 3,68 dollari per GPT-5.5 al massimo sforzo e 2,40 dollari per GLM 5.2. Il modello cinese è risultato il più economico in assoluto quando comparato ad altri sistemi di pari livello prestazionale.
L’ultimo modello di Z.ai quindi garantisce un risparmio notevole sul prezzo per token, ma nelle prove sul campo è risultato molto verboso. Produce molti token di ragionamento, fatturati a tariffa di output, e su compiti lunghi e complessi parte del risparmio teorico inizia ad erodersi. Il vantaggio reale di costo si colloca quindi in una forbice di quattro-sei volte a seconda del carico di lavoro, restando comunque sostanziale.
Per chi usa il modello dentro strumenti di sviluppo esiste anche un’alternativa in abbonamento, il GLM Coding Plan, con una quota fissa che parte da circa 10-15 dollari al mese per i piani base e arriva intorno agli 80 dollari per il piano Max.

Come usare GLM 5.2 in scenari reali
La via più rapida per iniziare a utilizzare GLM 5.2 è l’API ufficiale di Z.ai: in questo caso, però, tutto il traffico passa per infrastruttura non soggetta alle regolamentazioni europee. Per carichi che trattano dati personali sotto il GDPR, quindi dati di clienti, dipendenti o pazienti, l’API ufficiale è una scelta da escludere in produzione. La residenza dei dati, cioè il luogo fisico e giuridico in cui i dati vengono elaborati, risulterebbe, in questo caso, fuori dal controllo diretto dell’azienda.
Poiché i pesi di questo modello sono open source, chiunque può ospitare il modello e venderne l’accesso. Tra i fornitori attivi figurano Fireworks, DeepInfra, Together AI, Nebius e CoreWeave, oltre a OpenRouter, che funziona da instradatore verso oltre dieci fornitori e gestisce automaticamente il passaggio a un altro provider in caso di errore.
Diversi di questi fornitori operano in giurisdizioni statunitensi o europee, quindi è possibile scegliere in base a dove risiedono i dati, recuperando il controllo che l’API ufficiale non offre. Nella scelta bisogna anche tenere conto che i provider più convenienti servono pesi quantizzati in modo più aggressivo.
La quantizzazione consiste nel ridurre la precisione numerica con cui i pesi del modello sono memorizzati, in modo da ridurre il consumo di memoria, al prezzo di un piccolo calo di qualità. I fornitori low-cost servono versioni a precisione fp4, altri a fp8. Il divario di qualità, in alcuni ambiti applicativi, può essere sensibile, ed è la ragione per cui il prezzo varia.
Il self-hosting
La terza strada per iniziare a utilizzare GLM 5.2 è il self-hosting, ovvero ospitare il modello su infrastruttura propria, su un cloud privato oppure on-premise. I dati non escono dal perimetro aziendale, ed è questa la via che soddisfa i requisiti di residenza dei dati e gli scenari air-gapped, cioè isolati dalla rete. In questo caso, però, bisogna fare i conti con l’investimento in hardware. Il self-hosting ripaga lo sforzo solo a volumi alti e costanti, al di sotto di questa soglia, l’API a consumo costa meno e permette di risparmiare in costi di manutenzione e di personale tecnico specializzato.
Indipendentemente dalla modalitá di fruizione scelta, un modello a pesi aperti di qualità vicina alla frontiera ha un vantaggio netto: è un bene che nessun fornitore può revocare dall’oggi al domani. Il blocco di Fable ha reso questo rischio più percettibile, e GLM 5.2 offre un’alternativa interessante.






Partecipa alla community