
Nel software tradizionale il comportamento di un sistema sta nel codice: lo scrivono gli ingegneri, riga per riga, e quel codice si può leggere, ispezionare, all’occorrenza portare in tribunale. Con l’AI questo non è più vero. Il comportamento di un modello non lo scrive nessuno: viene appreso dai dati. Un modello di machine learning ha un utilizzo pratico solo quando è stato addestrato su dati di qualità e applicato a nuovi dati coerenti con questi. In altre parole, nell’AI non è tanto il codice a fare la differenza, quanto i dati.
La conseguenza operativa è che non si governa un sistema di AI semplicemente leggendone il codice, lo si governa gestendo la qualità, la sicurazione e l’appropriatezza dei dati. Il primo passo per governare i dati è quello di renderli utilizzabili. In una parola: attivarli.
Attivare i dati significa renderli pienamente sfruttabili dall’intelligenza artificiale e dalle applicazioni di analytics, esprimendone tutto il potenziale valore. È una definizione semplice che nasconde un lavoro tutt’altro che banale, perché tra il dato grezzo generato dai sistemi transazionali e conversazionali delle imprese e il dato che alimenta in sicurezza un modello o un cruscotto decisionale c’è una catena di trasformazioni che va progettata, costruita e mantenuta.
Indice degli argomenti:
Perché è ancora più importante adesso: i modelli sono una commodity, il dato no
Ci sono tre ragioni che rendono il tema urgente. La prima è competitiva: i modelli sono ormai una commodity: li hanno tutti, costano sempre meno, sono a un’API di distanza, mentre il dato proprietario, ben governato e pronto all’uso, è un differenziale competitivo che le imprese possono sfruttara. Ovviamente, dati di qualità e azionabili non sono sufficienti: occorrono competenze, architetture tecnologiche, processi decisionali e organizzazioni pronte a crearli, archiviarli, gestirli.
La seconda ragione è che l’AI è un amplificatore: un dato sbagliato dentro un report produce un errore che qualcuno prima o poi corregge; lo stesso dato dentro un sistema di AI produce migliaia di decisioni sbagliate in automatico. L’AI prende i difetti dei dati e li mette su scala industriale.
La terza è la più concreta: quasi tutti i progetti di AI che falliscono non falliscono sul modello, falliscono sul dato. La parte difficile non è più la creazione del proof of concept, ma integrare, governare, industrializzare. Per farlo occorre rendere il dato affidabile, tracciabile e disponibile su ampia scala, in modo ripetibile.
Gli strati dell’attivazione
“Attivare il dato” si traduce in strati tecnici precisi, su cui si lavora ogni giorno.
Semantica. Il killer silenzioso di ogni iniziativa data-driven è che lo stesso termine significa cose diverse in sistemi diversi: “cliente”, “cliente attivo”, “ricavo” producono numeri differenti a seconda dell’ufficio che li definisce. Si interviene con un business glossary che fissa le definizioni di business e un data dictionary che le àncora ai campi fisici dei sistemi, sostenuti da una disciplina di metadata management, ovvero gestione dei metadati. Senza un lessico condiviso, l’AI impara le contraddizioni dell’organizzazione e le restituisce con sicurezza.
Qualità. Non è un valore assoluto ma relativo all’uso: un dato può essere ottimo per il marketing e pessimo per un modello di rischio creditizio. Si parte dalla definizione delle dimensioni rilevanti per ciascun dominio (accuratezza, completezza, coerenza, tempestività), poi si mappano le criticità attraverso una criticality map, si traducono in regole formali di data quality e, infine, si implementano controlli e cruscotti di monitoraggio continuo. L’obiettivo è un dato fit for purpose, misurato nel tempo e non una volta sola in fase di progetto.
Lineage. Per ogni dato bisogna sapere da dove viene, come è stato trasformato, chi l’ha toccato e dove finisce. Il data lineage end-to-end, alimentato da un catalogo e da metadati strutturati, è il substrato tecnico dell’accountability: se un’autorità o un cliente chiede su quale base un sistema ha deciso, la risposta non sta in una policy ma nella capacità dell’architettura di ricostruire quel percorso. Senza lineage non si può spiegare una decisione, e ciò che non si può spiegare non si può difendere.
Architettura e pipeline. Sono i connettori attraverso cui i dati scorrono dalle fonti ai modelli. Qui si decide la solidità di tutto il resto: il disegno di un’architettura target (data lake, data warehouse, soluzioni lakehouse), la scelta tra storage relazionali e NoSQL, le pipeline di ingestion e trasformazione (ETL/ELT), l’integrazione via API e microservizi, l’event streaming e l’orchestrazione, il tutto sulle principali piattaforme cloud (GCP, Azure, AWS). A questo si affianca una disciplina di data quality & reliability engineering (controlli, monitoraggio, gestione degli errori), perché se la pipeline non funziona o funziona male, pregiudica la qualità di tutto l’impianto.
Privacy e sicurezza by design. Vanno pensate dentro il flusso, non aggiunte dopo. Sul fronte dell’anonimizzazione si lavora con obiettivi di protezione misurabili (k-anonymity, l-diversity ed estensioni personalizzate) e strategie multi-layer che combinano masking e generalizzazione, validando in modo oggettivo il trade-off privacy-utilità. Quando i dati reali sono scarsi, distorti o troppo sensibili, si ricorre alla generazione di dati sintetici statisticamente equivalenti, con metodologie che spaziano dalle tecniche statistiche classiche al deep learning generativo, sempre accompagnate da validazione scientifica.
Operating model. Sopra tutti questi strati c’è la domanda decisiva: chi è responsabile di cosa. Data owner, data steward (di business e tecnici), data engineer, un comitato di Data governance con meccanismi di coordinamento ed escalation, policy e procedure formalizzate (a partire dalla data classification). La tecnologia ha un peso, ma ancora maggiore è il ruolo (positivo o negativo) di persone, processi, modelli operativi e organizzativi. È la parte meno spettacolare e la più decisiva.
La governance come acceleratore, non come freno
Una delle difficoltà che si incontra a volte con clienti “frettolosi” è far comprendere la rilevanza del tema della governance. La governance fatta bene non è il freno: è l’impianto frenante che permette di andare forte. In Formula 1 non vince chi frena di meno, ma chi ha i freni migliori e può frenare più tardi. Tecnicamente, la governance diventa un freno quando è “a valle” — un cancello manuale alla fine, una commissione che timbra; diventa un acceleratore quando è by design: controlli di qualità automatici nelle pipeline, lineage che si registra da solo, regole di accesso già incorporate nel sistema.
Da qui nascono rendimenti composti: un dato governato si costruisce una volta e si riusa su dieci casi d’uso, abilitando anche modelli self-service in cui il business accede ai dati in autonomia perché definizioni, qualità e permessi sono garantiti a monte. Saltare la governance per “andare veloci subito” è prendere velocità a prestito a un tasso rovinoso: regge due o tre pilot, poi il dato non governato diventa il muro contro cui si sbatte in produzione.
Dalla teoria all’azione: un approccio sistemico all’attivazione dei dati
Da questa visione nasce un sistema coerente che copre l’intero ciclo di vita del dato, articolato in quattro aree e otto ambiti di servizio, ciascuno con capacità tecniche precise.
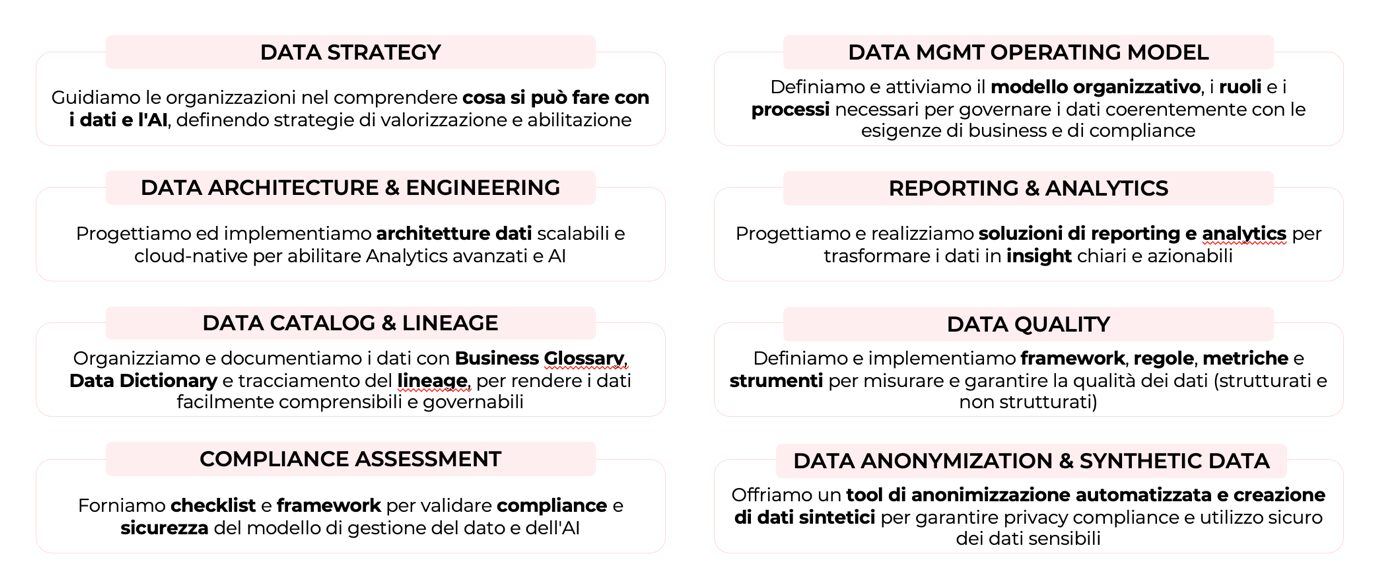
Direzione. La Data Strategy combina envisioning sui trend di dati e AI, assessment & readiness della maturità organizzativa, business case development e strategic design partecipativo. Il Data Management Operating Model definisce ruoli individuali (Data Owner, Data Steward) e collegiali (Comitato Data Governance), i meccanismi di coordinamento ed escalation, le policy e procedure (data classification, data quality, metadata management) e ne accompagna l’adozione, con riferimento a standard come DAMA-DMBoK.
Costruzione. La Data Architecture & Engineering analizza l’architettura esistente, disegna quella target (datalake, data warehouse, lakehouse), definisce piattaforma e flussi di integrazione e sviluppa pipeline robuste con controlli di qualità e reliability engineering, su tecnologie ETL/ELT, event streaming e orchestrazione in cloud. Il Reporting & Analytics copre data modeling, data visualization e role-based visibility, perché ogni utente acceda solo alle informazioni rilevanti per il proprio ruolo.
Conoscenza e qualità. Il Data Catalog & Lineage presidia l’identificazione dei dati critici, l’implementazione di business glossary e data dictionary e il tracciamento del lineage, con strumenti sw specializzati. La Data Quality definisce quality framework, esegue assessment, implementa metriche e cruscotti e struttura la conoscenza proprietaria per l’AI attraverso tassonomie, naming convention e metadati.
Sicurezza e conformità. Il Compliance Assessment mappa i dati personali e i trattamenti, conduce privacy risk assessment, sviluppa policy e produce documentazione di conformità (registro dei trattamenti, DPIA). La Data Anonymization & Synthetic Data mette a terra strategie di anonimizzazione multi-layer e generazione di dati sintetici, con tool proprietari che automatizzano validazione, visualizzazioni comparative e report di conformità.
Gli otto ambiti non sono opzioni alternative ma tasselli di un unico percorso: si può entrare da un assessment di qualità, da un nuovo data warehouse o da un progetto di anonimizzazione, ma il valore pieno emerge quando le quattro aree lavorano insieme.
Tre casi, un filo tecnico comune
Nel seguito, mostriamo come in tre diversi contesti, prima ancora della definizione di casi di applicazione dell’AI o scelte rispetto al singolo vendor o modello fondazionale, l’esigenza primaria dell’organizzazione fosse la messa a disposizione del management e dei decisori di dati sicuri, puliti e di qualità e permettesse alle unità organizzative di concordare sulla Single Source of Truth e di poter così generare un valore partendo da un patrimonio condiviso.
Caso 1: l’infrastruttura di data analytics.
In una società del credito, l’attivazione è partita dall’architettura: progettazione e messa in opera del data warehouse aziendale come repository certificato che aggrega e consolida fonti diverse, con definizione di ruoli, processi, business glossary, data dictionary, regole di data quality ed evoluzione della reportistica. Solo su queste fondamenta è stato possibile realizzare strumenti analitici avanzati, come un nuovo motore ESG per il calcolo degli universi investibili.
Caso 2: la data quality per prendere decisioni
In una società di gestione di infrastrutture stradali, nell’ambito di un programma Smart Road con servizi informativi in tempo reale, si è partiti dalla ricognizione completa delle fonti dell’ecosistema dati e individuati i domini critici. Le criticità sono state mappate e tradotte in regole formali di data quality secondo le dimensioni rilevanti, implementate su piattaforme di Enterprise Data Management e affiancate dalla definizione di ruoli, tra cui Business Data Owner, Business e IT Data Steward, Data Engineer, e dei relativi processi.
Caso 3: dai bisogni agli strumenti di business intelligence
In una piattaforma di welfare aziendale, infine, l’impianto è stato costruito in tre fasi: definizione dei fabbisogni informativi e dei KPI strategici e operativi, progettazione dell’architettura dati target integrata con gli asset esistenti e scalabile, realizzazione dei flussi e degli strumenti di business intelligence. Tre contesti lontani, un solo filo: prima si attiva il dato, poi l’AI e gli analytics esprimono valore. L’ordine non è invertibile.
La cornice normativa che costringe a prendersi cura dei dati
C’è infine una ragione che rende l’attivazione non più rinviabile. L’AI Act, per i sistemi ad alto rischio, non suggerisce la data governance: la impone. L’articolo 10 chiede esplicitamente che i dataset di addestramento, validazione e test siano pertinenti, sufficientemente rappresentativi e, per quanto possibile, privi di errori, con un esame esplicito dei bias. Sono requisiti tecnici scritti dentro una norma.
E il punto su cui tecnici e giuristi devono incontrarsi è che la compliance è una proprietà del sistema, non del documento: si può avere la policy più curata del mondo, ma se l’architettura dei dati non è in grado di produrre la prova attraverso lineage, tracciabilità, qualità, quella conformità resta una debole formalità.
Conclusioni: il valore “nascosto” dell’AI risiede nei dati
L’attivazione del dato, però, non è solo un problema tecnologico. È soprattutto un costo organizzativo che molte imprese sottovalutano. Significa chiedere alle funzioni di concordare definizioni comuni, assegnare responsabilità esplicite sui dati, accettare standard condivisi, modificare processi consolidati e rendere visibili incoerenze che per anni sono rimaste nascoste nei silos organizzativi. È spesso qui che i progetti rallentano: non sulla scelta del modello AI o della piattaforma cloud, ma sulla difficoltà di costruire una responsabilità distribuita e un linguaggio comune attorno al dato.
Per questo motivo, l’attivazione del dato non può essere delegata esclusivamente all’IT o ai data scientist: è un tema di trasformazione aziendale che coinvolge governance, processi, cultura manageriale e capacità decisionale.
In questo senso, il valore più importante dell’AI non risiede nei modelli, sempre più accessibili e standardizzati, ma nella capacità delle organizzazioni di costruire dati affidabili, condivisi, tracciabili e continuamente attivabili. L’AI, infatti, non trasforma dati mediocri in decisioni intelligenti: amplifica, automatizza e porta su scala la qualità (o i difetti) del patrimonio informativo aziendale.
Per questo motivo, prima ancora di scegliere modelli, vendor o architetture applicative, le imprese devono costruire le condizioni organizzative, tecnologiche e di governance che rendano il dato realmente utilizzabile. È lì che, sempre più spesso, si giocherà il vero vantaggio competitivo.






Partecipa alla community