
OpenAI ha annunciato gpt-oss-safeguard, una coppia di modelli open weight pensati per i compiti di classificazione legati alla sicurezza. Disponibili in due dimensioni, gpt-oss-safeguard-120b e gpt-oss-safeguard-20b, questi modelli derivano da gpt-oss, la linea open source dell’azienda, e sono distribuiti con licenza Apache 2.0.
Chiunque può dunque usarli, modificarli e distribuirli liberamente. Entrambi i modelli possono già essere scaricati su Hugging Face.

Indice degli argomenti:
Politiche di sicurezza personalizzabili
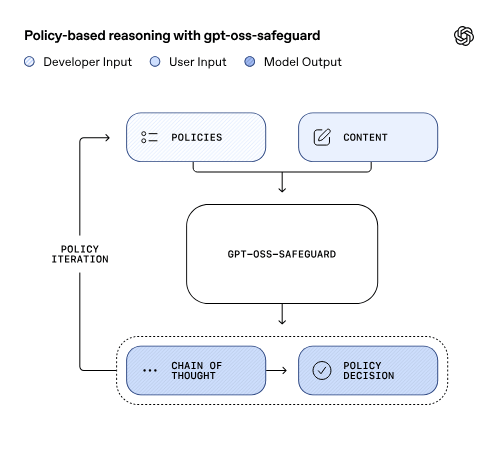
La particolarità di gpt-oss-safeguard è la sua capacità di “ragionare” in base a politiche definite dagli sviluppatori, interpretandole direttamente al momento dell’inferenza. Il modello classifica messaggi, risposte o intere conversazioni secondo regole che non sono imposte da OpenAI, ma scelte dall’utente.
Questo approccio rende le risposte più pertinenti e contestualizzate. Inoltre, il chain-of-thought – ovvero la catena di ragionamento – può essere consultato dagli sviluppatori per capire come il modello sia arrivato a una determinata conclusione. Poiché la politica non è integrata nel modello ma fornita durante l’uso, è possibile modificarla in modo iterativo, migliorando le prestazioni senza dover riaddestrare il sistema.
Flessibilità per casi d’uso specifici
Grazie a questo design, gli sviluppatori possono “disegnare” i confini di sicurezza più adatti al proprio contesto.
Un forum di videogiochi, ad esempio, potrebbe creare una politica per identificare i post che discutono di cheat o trucchi; un sito di recensioni di prodotti potrebbe invece filtrare i commenti potenzialmente falsi.
Il modello riceve due input contemporaneamente – la politica e il contenuto da classificare – e restituisce una conclusione accompagnata dal suo ragionamento. Sta poi allo sviluppatore decidere come integrare queste valutazioni nel proprio flusso di sicurezza.
Quando serve un’AI che ragiona
Questo approccio risulta particolarmente efficace in scenari dove:
- i rischi emergono o cambiano rapidamente, e le politiche devono adattarsi;
- il dominio è complesso e ricco di sfumature che i classificatori tradizionali faticano a cogliere;
- mancano dati sufficienti per addestrare un modello di alta qualità;
- la priorità è la trasparenza del ragionamento, più che la velocità di risposta.
OpenAI ha sviluppato gpt-oss-safeguard in collaborazione con ROOST, raccogliendo feedback e documentazione per gli sviluppatori. ROOST ha anche lanciato una nuova comunità dedicata ai modelli open per la sicurezza online, accompagnata da un rapporto tecnico che illustra le prestazioni del modello.
Difesa a più livelli: i classificatori di sicurezza
Secondo OpenAI, la sicurezza dei modelli richiede una “difesa in profondità”: più livelli di protezione che lavorano insieme.
Oltre ad addestrare i modelli a rispondere in modo sicuro, vengono impiegati classificatori per identificare e gestire contenuti potenzialmente pericolosi.
Tradizionalmente, questi classificatori – come quelli disponibili nell’API di moderazione di OpenAI – sono addestrati su grandi quantità di esempi etichettati manualmente secondo politiche prestabilite. Tuttavia, il modello non conosce la politica in sé: deve dedurla osservando le differenze tra contenuti “sicuri” e “non sicuri”.
Questo metodo funziona, ma è costoso e lento da aggiornare: ogni modifica di policy richiede un nuovo addestramento.
Gpt-oss-safeguard, invece, applica direttamente la politica fornita dallo sviluppatore, consentendo una maggiore flessibilità e adattabilità.
Come OpenAI usa il ragionamento interno
All’interno di OpenAI, i modelli di ragionamento sono già parte integrante del sistema di sicurezza.
Questo metodo, chiamato deliberative alignment, consente ai modelli di comprendere e applicare dinamicamente le politiche di sicurezza, rendendoli più sicuri e coerenti rispetto ai predecessori.
Il sistema interno, denominato Safety Reasoner, è stato addestrato con reinforcement fine-tuning su compiti di etichettatura delle politiche, premiando il modello quando le sue decisioni coincidevano con quelle umane.
Oggi, Safety Reasoner permette di aggiornare le politiche operative in tempo reale, molto più rapidamente di quanto richiederebbe un riaddestramento completo.
In alcuni casi, fino al 16% della potenza di calcolo totale viene dedicata al ragionamento di sicurezza.
Per applicazioni come la generazione di immagini o il progetto Sora 2, il sistema esegue valutazioni dinamiche in tempo reale, bloccando generazioni pericolose.
In ambiti sensibili come biologia o autolesionismo, viene impiegato in combinazione con classificatori più leggeri per individuare e analizzare contenuti rischiosi.
gpt-oss-safeguard: Prestazioni e valutazioni
I modelli gpt-oss-safeguard sono stati testati sia su set di dati interni che pubblici.
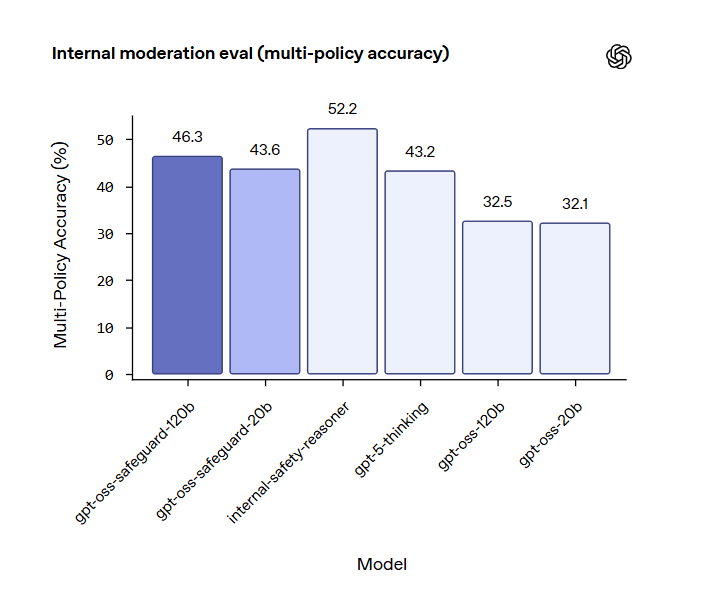
In valutazioni multi-policy, hanno superato gpt-5-thinking e i modelli gpt-oss standard in termini di accuratezza.
Sul dataset di moderazione 2022 e su ToxicChat, i risultati mostrano prestazioni competitive, con gpt-oss-safeguard che in alcuni casi eguaglia o supera i sistemi interni di OpenAI.
Nonostante le dimensioni più ridotte, i modelli open si dimostrano efficaci per compiti di sicurezza complessi e personalizzati.
gpt-oss-safeguard: limiti e sfide
OpenAI riconosce due principali limiti.
Primo: un classificatore addestrato su decine di migliaia di esempi può ancora superare gpt-oss-safeguard in precisione per compiti molto complessi.
Secondo: il ragionamento richiede più tempo e risorse di calcolo, rendendo difficile l’applicazione su larga scala.
Per affrontare questo problema, OpenAI utilizza un approccio ibrido: piccoli classificatori filtrano i contenuti da analizzare, mentre Safety Reasoner opera in modo asincrono, mantenendo l’esperienza utente fluida.
Collaborazione aperta con la community
Gpt-oss-safeguard è il primo set di modelli di sicurezza open di OpenAI sviluppato con la collaborazione della comunità.
Il progetto è stato testato con esperti di sicurezza di SafetyKit, ROOST e Discord.
Il CTO di ROOST, Vinay Rao, lo descrive come “il primo modello open source di ragionamento che consente di portare le proprie politiche e definizioni di danno”.
Secondo Rao, “le organizzazioni devono poter studiare, modificare e usare liberamente le tecnologie di sicurezza per innovare”.
Attraverso la ROOST Model Community (RMC), OpenAI invita ricercatori e professionisti a condividere esperienze, pratiche e valutazioni per migliorare la sicurezza dell’AI open source.





