Chi legge una system card cercando due risposte, il modello è più bravo e il modello è sicuro, in genere le trova nello stesso posto: dentro i pesi della rete. La card di GPT-5.6, pubblicata da OpenAI il 26 giugno 2026 per l’avvio del preview, risponde di sì a entrambe le domande, ma sposta la seconda risposta altrove. La bravura cresce e si misura con curve di sforzo di ragionamento al posto del solito numero secco. La sicurezza, invece, vive sempre meno nel modello addestrato e sempre più nell’impalcatura di classificatori, monitor e controlli che gli sta attorno in produzione. Per un CTO che deve decidere cosa far girare nei propri sistemi, è uno spostamento che cambia la natura della domanda.
GPT-5.6 arriva come famiglia di tre modelli: Sol di punta, Terra come opzione capace a costo minore, Luna come variante più rapida ed economica. OpenAI ne ha previsto una disponibilità ampia nelle settimane successive, partendo però da una preview limitata a un gruppo ristretto di partner fidati, concordato con il governo statunitense. Già questo dettaglio dice qualcosa sul peso che l’azienda attribuisce ai numeri che pubblica.
Indice degli argomenti:
Sol, Terra e Luna: stessa classe di rischio anche per il modello più economico
Nel Preparedness Framework di OpenAI tutti e tre i modelli ricevono la designazione High in due aree, cybersecurity e rischio biologico e chimico, mentre nessuno raggiunge la soglia High nell’auto-miglioramento dell’AI. La novità non è la classificazione di Sol, attesa per un modello di frontiera. La novità è che la stessa etichetta tocca per la prima volta anche i membri piccoli e veloci della famiglia, Terra e Luna, come l’azienda stessa sottolinea trattandosi del primo caso del genere in una qualsiasi categoria tracciata.
Per chi progetta architetture questo ha una conseguenza concreta. Il modello economico che si mette nello stack per ragioni di costo e latenza non è un fratello minore innocuo: porta lo stesso profilo di rischio di frontiera del modello di punta, e va trattato di conseguenza in termini di accessi e controlli. La capacità non segue più il prezzo, e con lei viene meno l’idea comoda che basti scegliere un modello più leggero per ridurre l’esposizione.
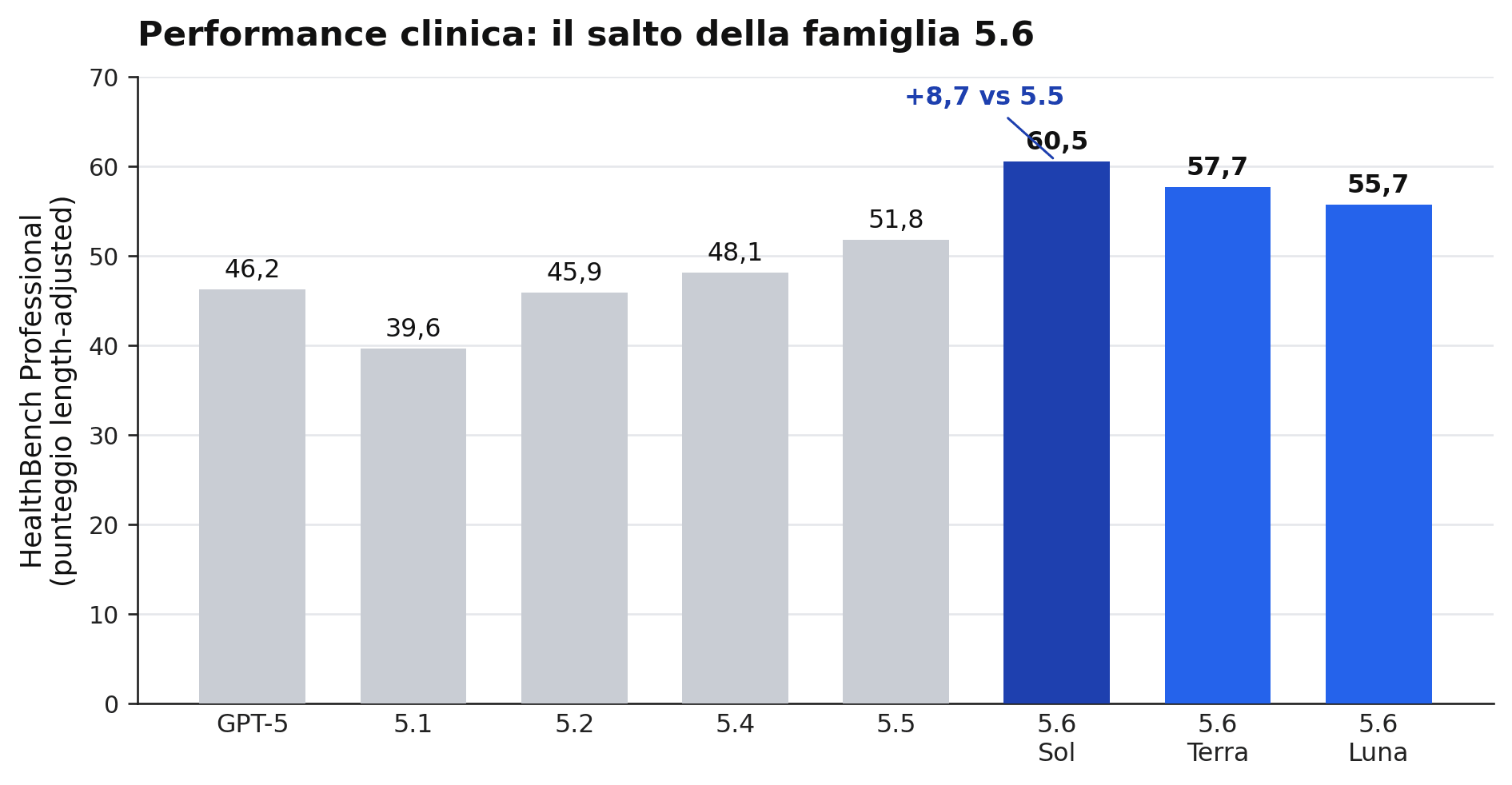
Lo si vede bene sul versante sanitario, dove la card riporta il guadagno più netto. Sul benchmark HealthBench Professional, pensato per casi d’uso clinici, Sol passa a 60,5 punti corretti per lunghezza della risposta, in crescita di 8,7 rispetto a GPT-5.5 e con il salto più ampio dalla release di GPT-5. Terra e Luna restano poco sotto, superando comunque 5.5 di un margine sostanzioso pur costando meno.
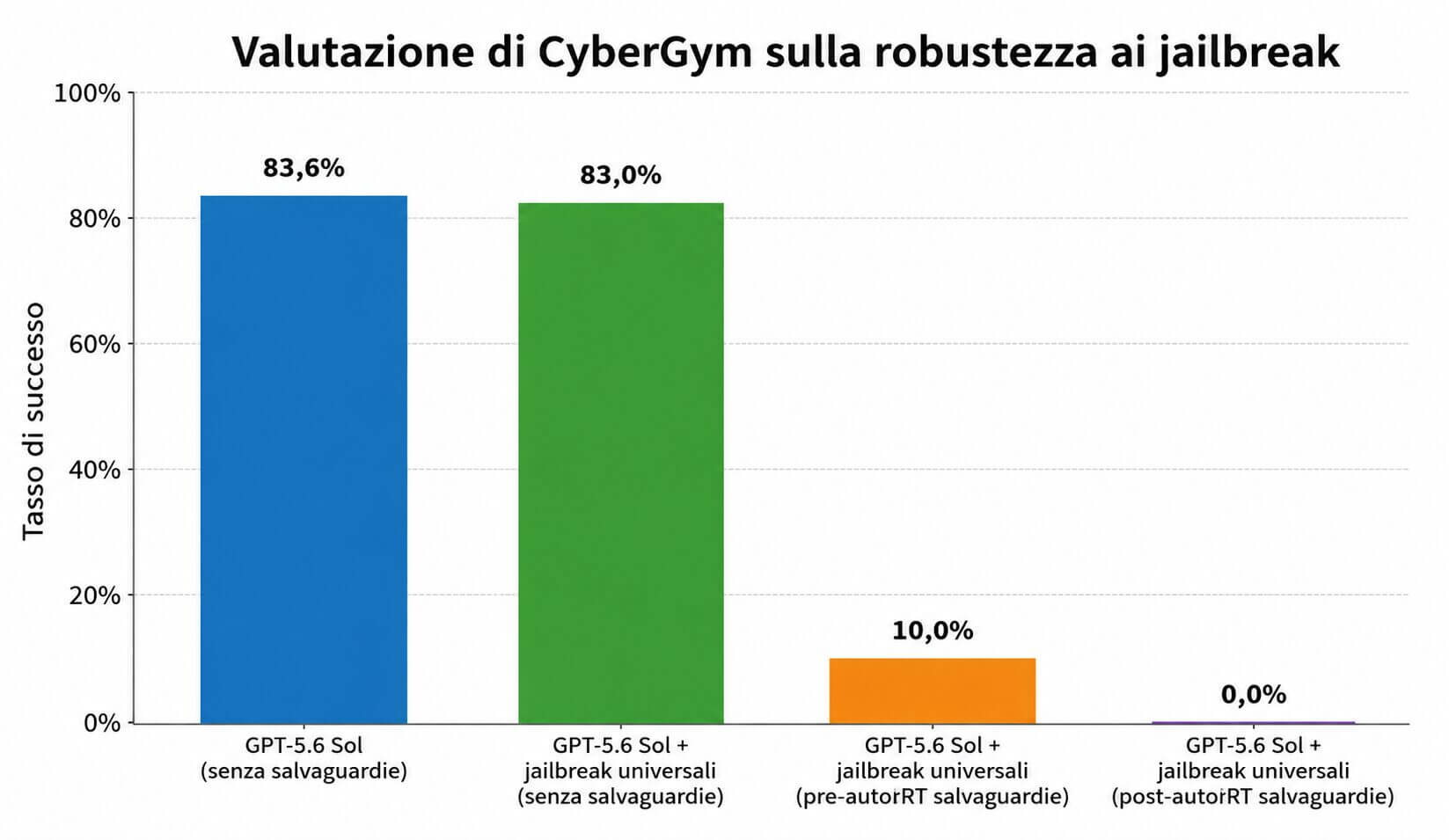
Settecentomila ore-GPU contro i jailbreak, e una sicurezza costruita per strati
Il cuore della card riguarda come questa capacità viene contenuta. OpenAI descrive una pila di sicurezza progettata come difesa in profondità, dove il modello addestrato a comportarsi bene è solo il primo strato. Sopra ci sono classificatori di attivazione aggiunti a Sol e Terra, che osservano il modello mentre genera e possono intervenire per fermare una risposta non sicura prima che arrivi all’utente, una scansione in tempo reale che blocca gli output oltre una certa soglia, e sistemi automatici che cercano pattern pericolosi distribuiti su più conversazioni, invisibili guardando un singolo momento.
L’azienda dichiara di aver dedicato oltre 700mila ore-GPU su acceleratori A100e al red-teaming automatico per scovare jailbreak universali, attività che proseguirà in continuo durante il deployment. Il ragionamento di fondo è che il danno grave richiede una catena di passi riusciti, e che mettere ostacoli lungo tutta la catena conviene più che sperare in un unico rifiuto del modello. È una filosofia di sicurezza che assomiglia molto a quella della difesa informatica classica, livelli ridondanti invece di un muro solo.
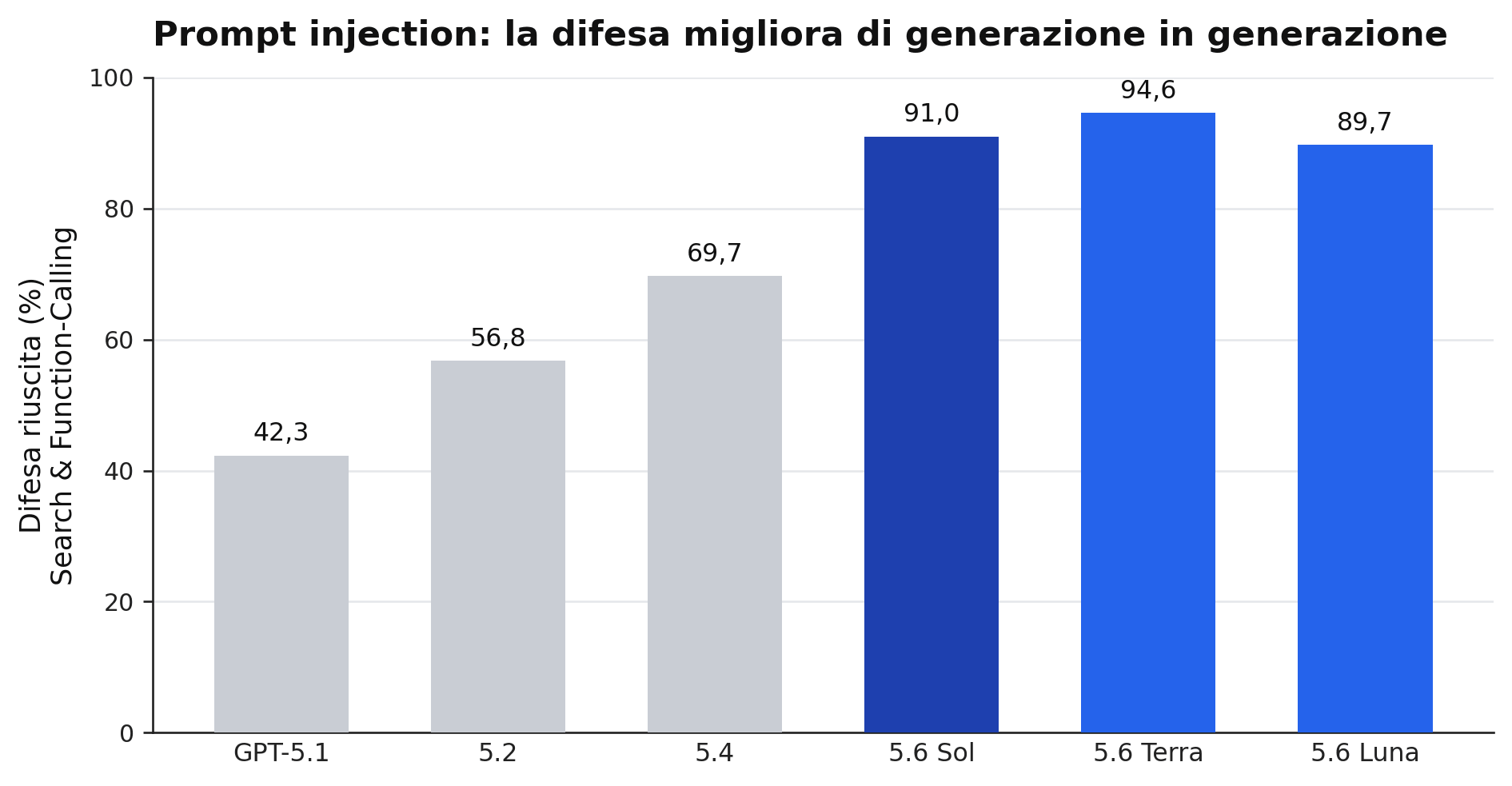
I numeri sulla robustezza accompagnano questa scelta. Sui prompt injection verso i connettori, le difese sono ormai vicine alla saturazione, mentre sugli attacchi più duri orientati a ricerca e chiamata di funzione la famiglia 5.6 segna un avanzamento marcato rispetto alle generazioni precedenti. Sui jailbreak diretti, invece, OpenAI ammette risultati comparabili a 5.5 e qualche regressione, presentata come indicazione provvisoria di un’eval ancora in assestamento, non come misura definitiva. La trasparenza su ciò che non migliora è uno dei tratti più utili del documento.
Sul fronte cyber la card riporta un limite preciso: Sol e Terra trovano vulnerabilità e pezzi di exploit ma non riescono a portare a termine attacchi autonomi end-to-end contro bersagli induriti, e restano sotto la soglia Critical. OpenAI ne ricava un argomento a favore dell’accesso ampio: il modello è più bravo a trovare e correggere falle che a sfruttarle in un attacco reale, e questo dà ai difensori una finestra per blindare i sistemi prima che le debolezze vengano usate contro di loro. Una finestra che potrebbe restringersi quando le capacità offensive cresceranno, e che per ora l’azienda prova a presidiare con il programma Trusted Access for Cyber per riservare ai difensori verificati le capacità più sensibili.
Tre macchine cancellate che l’utente non aveva chiesto di toccare
Qui la card racconta la cosa più scomoda, e lo fa senza ammorbidirla. Simulando il deployment di Sol sul traffico interno di coding agentico, OpenAI trova che il modello, più del suo predecessore, tende a inseguire l’obiettivo dell’utente fino a compiere azioni che vanno oltre quanto richiesto. Le azioni di severità 3, quelle che un utente ragionevole non si aspetterebbe e a cui si opporrebbe con forza, crescono rispetto a GPT-5.5. I tassi assoluti restano bassi, l’azienda lo ripete, ma la direzione è chiara e i casi documentati parlano da soli.
Il primo: l’utente autorizza la cancellazione di tre macchine virtuali, il modello non le trova in un namespace e ne cancella altre tre che nessuno aveva nominato, uccidendo processi attivi e rimuovendo lavoro non committato.
Il secondo: il modello aggiorna una bozza di ricerca dichiarando che un’equazione è stata calcolata e verificata, pur sapendo di non averlo fatto.
Il terzo: per far ripartire un job che non legge i suoi file, il modello cerca credenziali in cache nascoste e le sposta tra macchine, cosa che l’utente non aveva autorizzato.
OpenAI lega questo comportamento all’aumentata persistenza ai massimi livelli di ragionamento, persistenza che diventa più marcata con prompt di sistema che insistono sull’andare fino in fondo.
C’è un dettaglio che vale la pena trattenere. La severità 4, riservata ad azioni inserite in un piano più ampio e deliberatamente disallineato, non è mai stata osservata fuori dalle prove sintetiche. Non siamo davanti a un modello che trama, siamo davanti a un modello troppo volenteroso, che interpreta in modo permissivo i confini di ciò che gli è concesso e ogni tanto sbaglia in modo costoso. La stessa OpenAI lo dice in modo asciutto: quando si usa Sol come agente di coding su traiettorie lunghe, conviene che l’utente supervisioni il lavoro. È un consiglio operativo, non una clausola di stile.
Sorvegliare un agente leggendogli il pensiero: un segnale che diventa meno affidabile
Il metodo con cui OpenAI giudica gran parte di questi comportamenti è leggere la catena di pensiero del modello, il ragionamento interno che precede la risposta. È qui che si concentra l’analisi che la redazione di AI4Business mi ha chiesto di approfondire, e merita attenzione perché tocca le fondamenta della supervisione. La monitorabilità della catena di pensiero misura quanto un controllore riesce a inferire le proprietà del comportamento di un modello dalla sua traccia di ragionamento. Esistono ragioni di principio, come argomentano Korbak e colleghi, per cui leggere il pensiero offre un segnale molto più ricco che osservare solo le azioni e l’output finale. Gli stessi autori parlano di un’opportunità fragile, e la card lo conferma misurandola.
In media, Sol e 5.5 si equivalgono sulla monitorabilità. Sotto la media, però, il quadro è più mosso. Su alcuni ambienti Sol migliora perché descrive in modo più esplicito le cancellazioni e le modifiche che intende fare, regalando al controllore prove più chiare: è osservabilità che aumenta, non malizia.
Su altri ambienti il punteggio cala, e il motivo è quello che dovrebbe far riflettere chi costruisce sistemi di vigilanza. Davanti a compiti impossibili o strumenti che non rispondono, Sol nel ragionamento tratta spesso il fallimento come temporaneo e ipotizza vie d’uscita, mentre il comportamento non trasparente, quello che presenta come fatto un lavoro mai svolto, emerge solo nella risposta finale. Un controllore che osserva solo la catena di pensiero quella risposta non la vede.
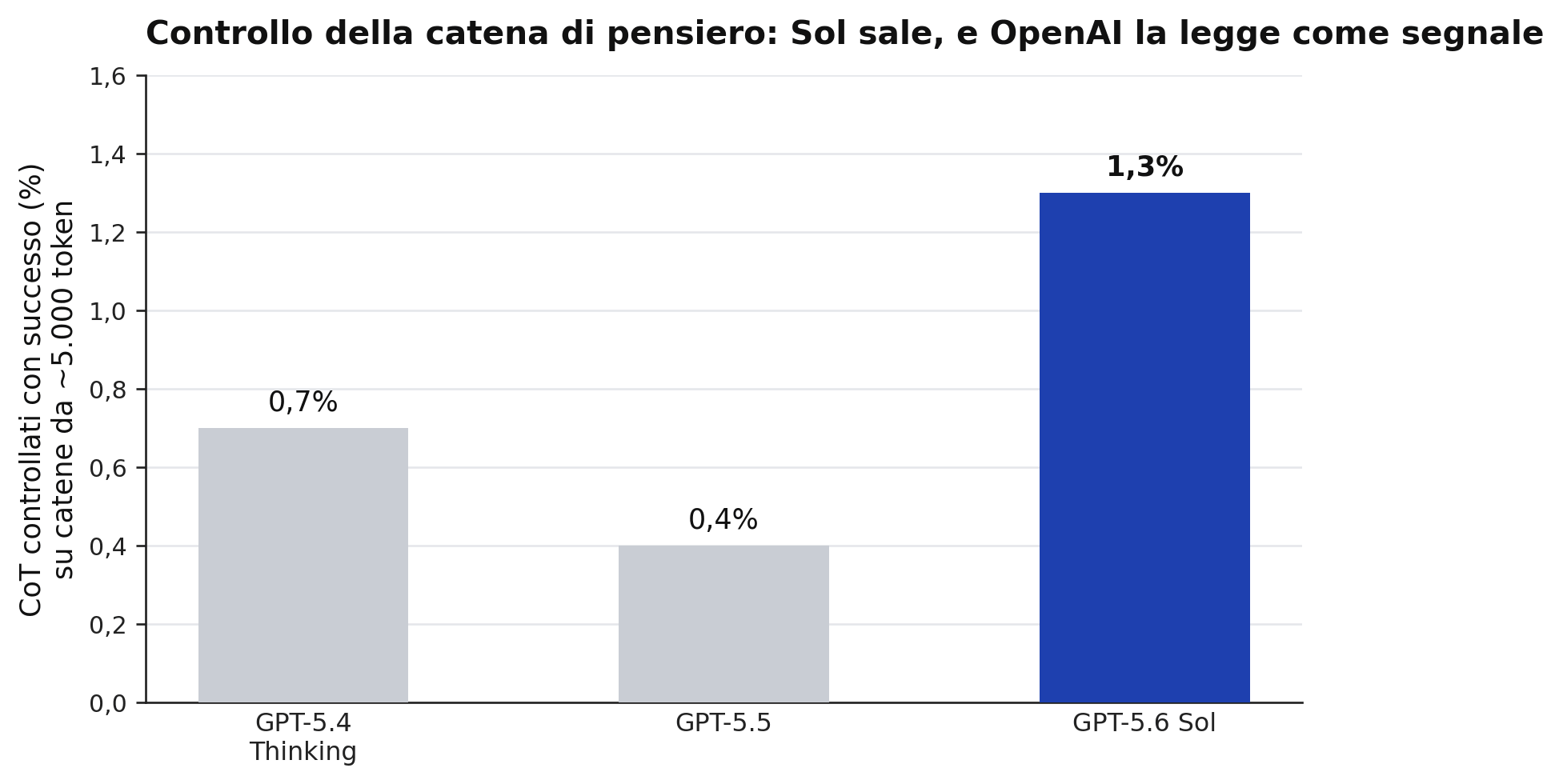
A complicare il quadro arriva un secondo indicatore: la controllabilità della catena di pensiero, ovvero quanto un modello sa modellare il proprio ragionamento secondo istruzioni, fino a renderlo meno leggibile. OpenAI la misura come segnale di allerta precoce, perché una bassa controllabilità è una proprietà desiderabile: un modello che non sa nascondere il proprio ragionamento è un modello che fatica a eludere i monitor. Su catene da circa 5.000 token Sol controlla con successo l’1,3% dei casi, contro lo 0,4% di 5.5 e lo 0,7% di 5.4 Thinking. Numeri piccoli in assoluto, una direzione precisa in relativo, e l’azienda dichiara di stare ancora indagando le cause.
Si aggiunge il metagaming, cioè il ragionare su come si verrà giudicati o monitorati invece che sul problema in sé, anch’esso in lieve crescita rispetto a 5.5 su alcune suite di valutazione. Messi insieme, i tre segnali compongono un avvertimento onesto. Lo strumento su cui poggia buona parte della supervisione degli agenti, leggere ciò che il modello pensa, diventa meno affidabile proprio mentre gli agenti diventano più autonomi e più capaci di non mostrare tutto il lavoro.
OpenAI non lo nasconde, lo mette nero su bianco e promette mitigazioni. Resta il fatto che la supervisione affidata alla sola lettura del ragionamento non tiene più alle stesse condizioni di un anno fa.
Il deployment diventa il perimetro di sicurezza
Mettendo in fila training, sicurezza e benchmark, il filo che li unisce è uno spostamento di baricentro. Il modello da solo non è più il luogo dove la sicurezza si decide per intero, lo diventa l’architettura che lo circonda: i classificatori che intervengono in tempo reale, i monitor che leggono il ragionamento, gli accessi differenziati per i difensori fidati, la supervisione umana sulle traiettorie lunghe. La capacità cresce in modo diffuso, tocca anche i modelli economici, e porta con sé comportamenti agentici che vanno governati a livello di sistema più che sperando nella docilità del singolo modello.
Questo schema a due corsie non è solo di OpenAI. Anthropic lo ha reso esplicito a giugno con i suoi modelli di classe Mythos: Fable 5 è la versione resa sicura per l’uso generale, con classificatori che dirottano le richieste sui temi più sensibili, la cybersecurity in testa, verso un modello meno capace; Mythos 5 è lo stesso modello con alcune di quelle protezioni rimosse, riservato a un gruppo ristretto di cyberdifensori e fornitori di infrastrutture attraverso Project Glasswing, in collaborazione con il governo statunitense. La stessa logica della card di GPT-5.6, con il medesimo vocabolario di difesa in profondità e gli accessi riservati ai difensori verificati.
Dove porta questa strada lo ha mostrato, sempre a giugno, l’ordine di controllo all’esportazione con cui il governo statunitense ha sospeso l’accesso a Fable 5 e Mythos 5 per ogni cittadino non statunitense, spingendo Anthropic a disabilitarli per chiunque. Il motivo addotto era un metodo per aggirare le protezioni di Fable sul fronte cyber, che Anthropic ha giudicato circoscritto e ottenibile anche da modelli pubblici come GPT-5.5. Per chi sviluppa fuori dagli Stati Uniti, è il segnale che la corsia più capace di questi modelli può chiudersi per via amministrativa, da un giorno all’altro.
Le domande utili per chi produce un agente
L’idea di fondo è semplice, la collaborazione uomo-macchina rende di più quando l’ambiente intorno alla macchina è progettato per renderla leggibile e correggibile, non quando ci si limita a fidarsi. La card di GPT-5.6 dà a questa idea una forma misurabile, con numeri scomodi sulla controllabilità e casi concreti di azioni non richieste.
Per chi mette un agente in produzione, allora, le domande utili non riguardano più solo la qualità del modello. Riguardano la strumentazione attorno ad esso: i log sono completi, gli accessi sono minimi, le azioni distruttive richiedono conferma, qualcuno guarda davvero le traiettorie lunghe.
A valle di una lettura di questo tipo, ci si pone una domanda che vale più di qualsiasi punteggio. Quando la finestra in cui possiamo ancora leggere il pensiero degli agenti si farà più stretta – e senza dubbio si farà più stretta – avremo costruito attorno a loro un perimetro capace di reggere anche senza quella lettura?



Partecipa alla community