
A guidare un agente di coding verso un buon risultato conta più la padronanza del problema che la capacità di scrivere codice. Lo mostra l’analisi che Anthropic ha pubblicato sul lavoro reale con Claude Code, circa 400mila sessioni interattive lette una a una da un sistema che preserva la privacy, raccolte tra ottobre 2025 e aprile 2026 da circa 235mila persone. Il lavoro estende ricerche precedenti sulle misure di autonomia delle sessioni e su come Claude Code sta già cambiando il lavoro dentro Anthropic.
Dentro quelle sessioni si vede una divisione del lavoro precisa, le persone decidono cosa costruire e l’agente decide come, e un risultato che spiazza un’aspettativa diffusa: nei compiti che producono codice ogni grande gruppo professionale riesce quasi quanto gli ingegneri del software. Il codice come barriera d’ingresso pesa meno di prima. A pesare, e parecchio, resta quanto chi siede davanti alla tastiera conosce davvero il problema che sta cercando di risolvere.
Per chi in azienda valuta dove e a chi affidare gli agenti di coding, la lettura più utile riguarda come la collaborazione si distribuisce sessione dopo sessione, e chi ne esce con un lavoro che regge.
Indice degli argomenti:
Settanta contro venti: chi decide nelle sessioni
Anthropic ha costruito un classificatore che attribuisce ogni decisione di una sessione a chi l’ha presa, separando la pianificazione, cosa fare e quale strada prendere, dall’esecuzione, quali file toccare e quale comando lanciare. Il quadro è stabile: in media le persone tengono per sé circa il 70% delle decisioni di pianificazione e lasciano a Claude circa l’80% di quelle di esecuzione. Si decide la meta, si affida la strada.
Le valutazioni di capacità indicano un tetto alto e in crescita, con modelli capaci di completare in autonomia compiti software che a una persona richiederebbero ore. L’uso reale racconta però una storia di guida condivisa. Una sessione tipica si sviluppa in circa quattro scambi, e a ogni prompt che la persona invia, nei dati da ottobre ad aprile, Claude risponde con una catena di una decina di azioni in media, a volte oltre cento, leggendo file, modificando codice, lanciando comandi, e producendo circa 2.400 parole di output per turno.
Quanto Claude fa tra un controllo e l’altro segue da vicino chi tiene il timone: dove la persona trattiene l’esecuzione, oltre l’80% delle scelte operative, l’agente si muove con prudenza, intorno alle otto azioni per turno, mentre dove è Claude a guidare la pianificazione la catena si allunga fino a sedici.
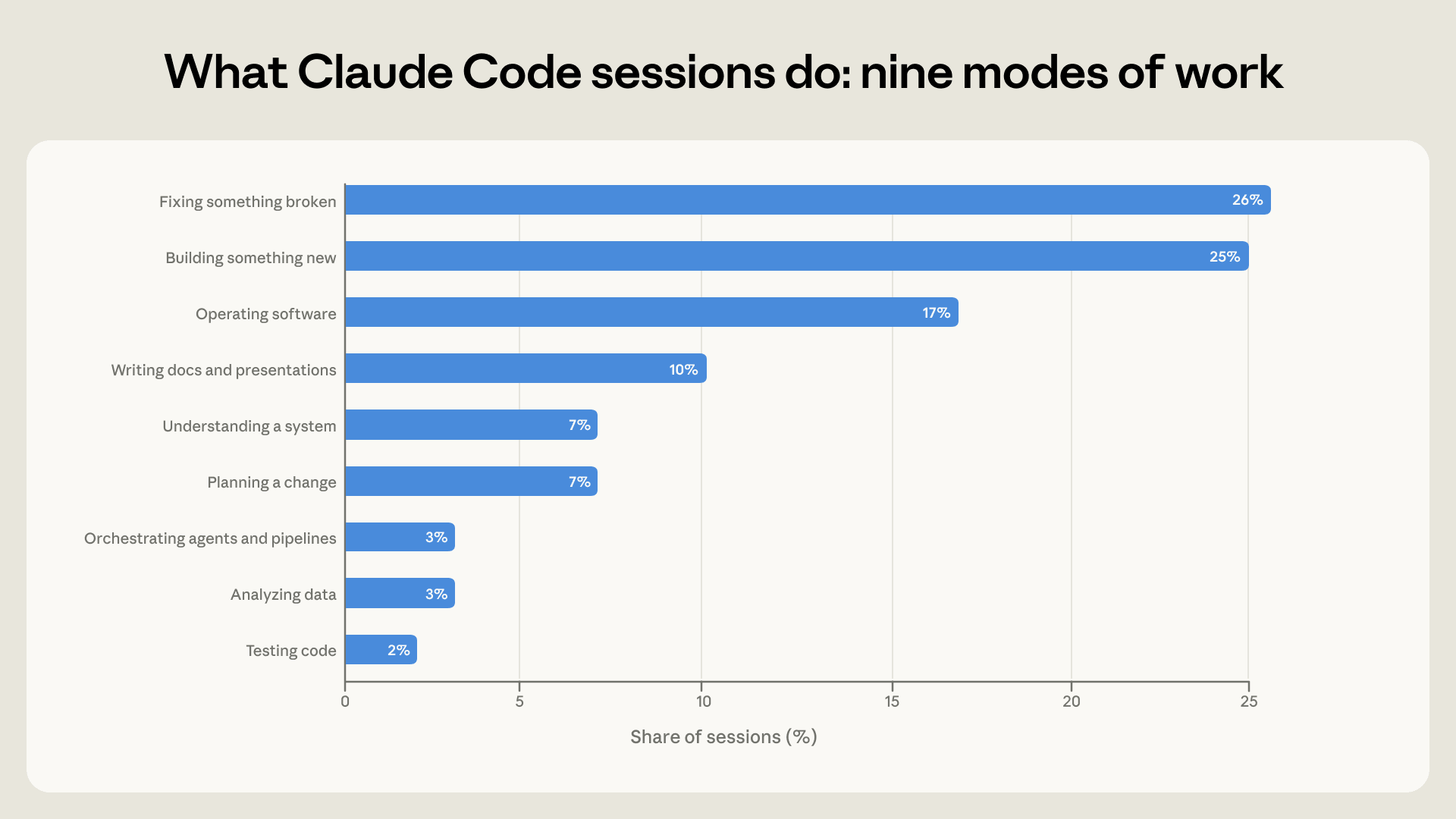
Sul piano dei contenuti, le sessioni si distribuiscono su nove modi di lavoro. Scrivere codice nuovo e correggere codice rotto pesano insieme per metà del totale, 25% e 26%, mentre far funzionare il software, dalla configurazione al monitoraggio, vale un altro 17%, e una quota crescente serve a capire un sistema, a pianificare una modifica, ad analizzare dati o a produrre testo.
Il contabile esperto e l’ingegnere principiante
Da ogni trascrizione un classificatore stima la competenza della persona sul compito, su una scala da uno a cinque, da principiante a esperto, e lo fa in modo agganciato al singolo task. Un ingegnere navigato che pone la sua prima domanda su Rust, lì, è un principiante. Un contabile che non ha mai scritto una riga di Python, ma sa esattamente quali regole di riconciliazione lo script deve rispettare e coglie il caso limite che salta alla chiusura di fine mese, su quel compito è un esperto. Gli esempi usati per tarare il classificatore vengono da un dataset pubblico di sessioni di coding.
Il classificatore guarda tre segnali:
- quanto la persona è precisa nel formulare le richieste,
- che cosa chiede di verificare,
- se è lei a correggere Claude o Claude a correggere lei.
Quanto questa competenza conti si vede nella reattività dell’agente. Nelle sessioni dei principianti ogni prompt mette in moto circa cinque azioni e seicento parole, in quelle degli esperti la catena raddoppia, dodici azioni, e l’output si moltiplica per cinque, oltre tremila parole. Lo scarto resta dentro ogni tipo di lavoro e ogni fascia di valore, e tiene anche controllando per il mestiere, il valore del compito, il mese e il modello usato, circa il 9% di azioni e il 13% di output in più per ogni gradino di competenza.
Quando la sessione si mette male
Misurare il successo, qui, richiede cautela, perché non si osservano gli esiti reali e nessuno chiede alla persona se ha ottenuto quello che voleva. Anthropic combina due letture della trascrizione, un giudizio sul fatto che la persona abbia raggiunto il suo obiettivo, e un controllo delle prove a sostegno, commit e pull request coerenti con il lavoro, test che passano, conferme esplicite di chi scrive. Il successo è verificato solo quando entrambe le cose tengono, il giudizio positivo e almeno un segnale duro.
Su tutte queste misure il segnale è lo stesso: più competenza la persona mostra nella sessione, più è probabile che la sessione vada a buon fine. Una sessione da principiante tocca la soglia più severa, il successo verificato, nel 15% dei casi, e arriva ad almeno un successo parziale nel 77%. Una sessione da livello intermedio in su raggiunge il successo verificato tra il 28 e il 33% delle volte, e il parziale oltre il 90%. Quasi tutto il guadagno si concentra nel salto da principiante a intermedio, mentre tra intermedio ed esperto la salita si fa più piatta.
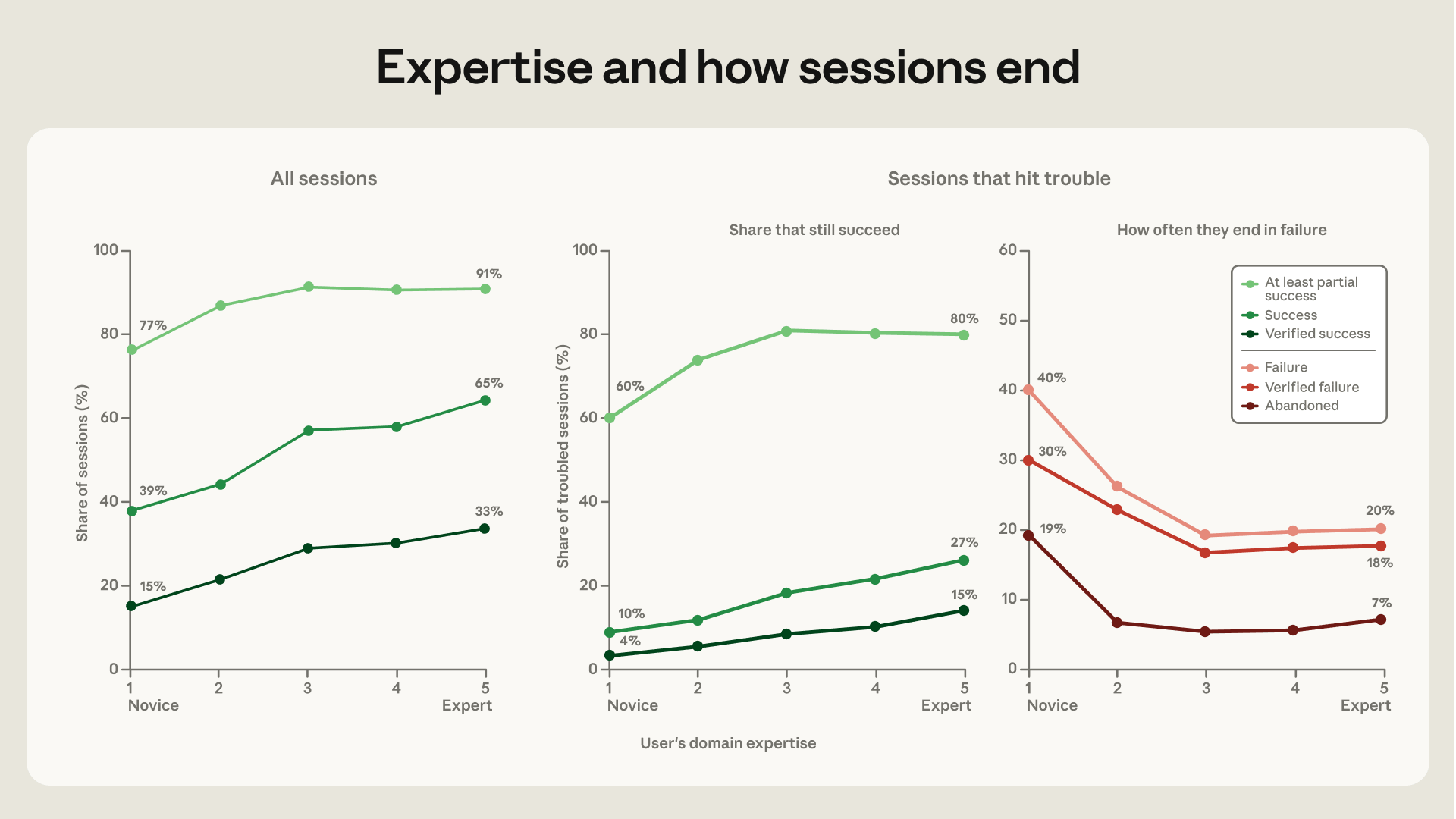
Il quadro si fa più nitido nelle sessioni che incontrano ostacoli, un errore, un test fallito, più tentativi sullo stesso punto, una persona che si dice insoddisfatta. Tra queste, la quota che diventa successo verificato sale dal 4% dei principianti al 15% degli esperti, e quella di almeno un successo parziale dal 60% a circa l’80%.
C’è poi il segnale che dice di più sul valore della competenza: quando una sessione difficile finisce abbandonata, a zero righe di codice, succede nel 19% dei casi se chi guida è un principiante, contro il 5-7% di tutti gli altri. I meno esperti mollano prima. Davanti allo stesso ostacolo, parte di ciò che la competenza aggiunge è la capacità di rimettere l’agente sulla rotta giusta.
Ogni mestiere resta entro sette punti dagli ingegneri
Per capire chi fa questo lavoro, Anthropic deduce il mestiere dalla trascrizione, dal contesto del progetto, dai nomi dei file, dagli artefatti citati, che si tratti di un atto legale o di un dataset clinico, dal vocabolario, e mappa la sessione su una delle ventitré grandi categorie occupazionali della classificazione statunitense, con una regola esplicita: scrivere codice non basta a fare di qualcuno un professionista del software. Un avvocato che costruisce uno script per segnalare clausole mancanti in una cartella di contratti finisce tra le occupazioni legali, anche se la sessione è in tutto e per tutto lavoro software.
Il mestiere si è potuto dedurre in circa il 70% delle sessioni. Il gruppo più numeroso è quello informatico e matematico, seguito da business e finanza, arti e media, management, scienze della vita e sociali, mentre i gruppi non software che crescono più in fretta sono management, vendite e professioni legali. Sul successo, lo scarto tra chi fa il software di mestiere e tutti gli altri è piccolo: le occupazioni informatiche raggiungono il successo verificato in circa il 30% delle sessioni, le altre nel 26%, e nelle sole sessioni che producono codice il confronto è 34% contro 29%. Tra i dieci gruppi più rappresentati ciascuno resta entro sette punti percentuali dagli ingegneri del software, e quel divario non si è allargato né ristretto in sette mesi, mentre i tassi salivano per tutti.
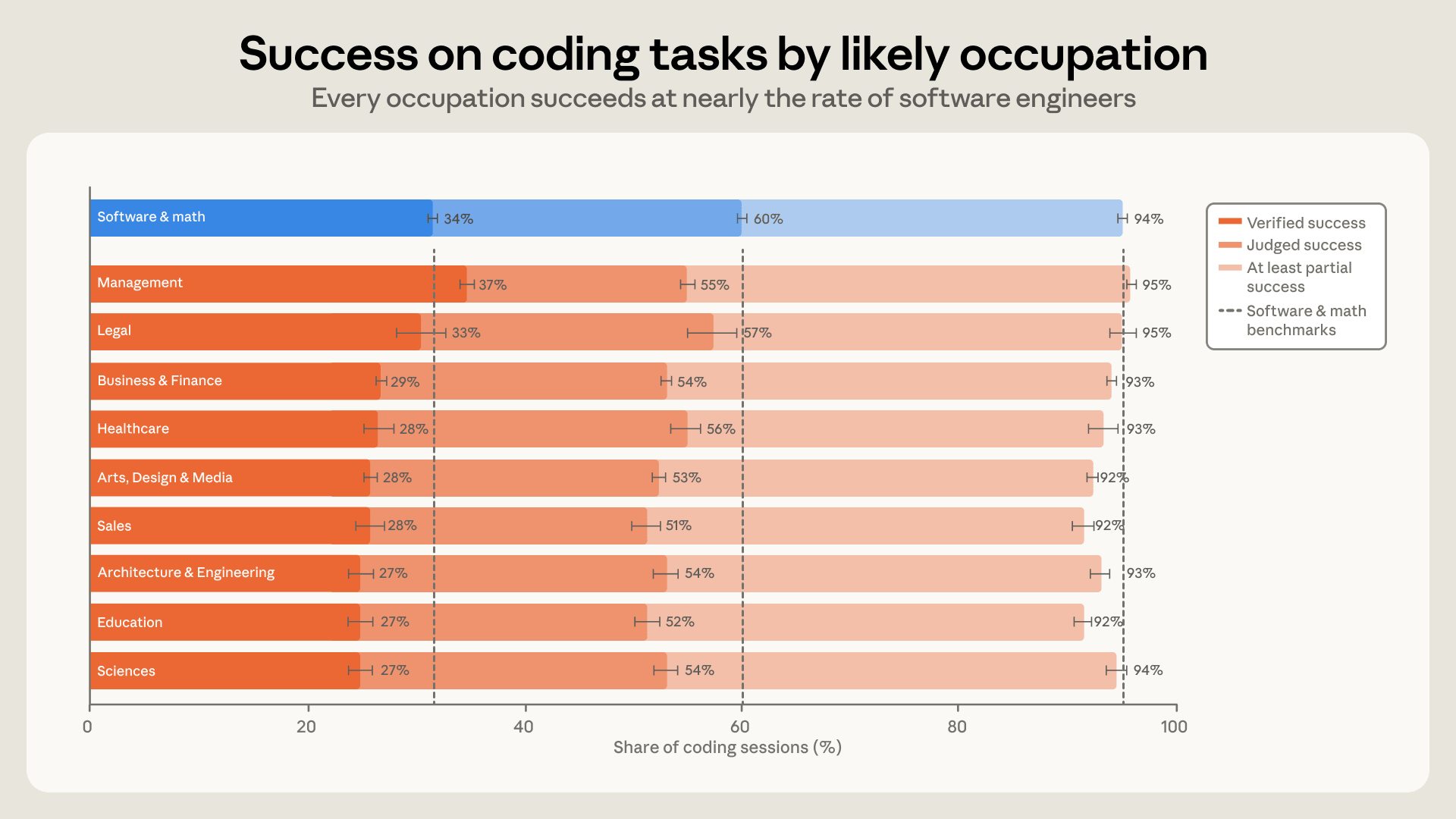
C’è un dettaglio che merita una nota di metodo: sul successo verificato il management compare leggermente sopra gli ingegneri del software. Può darsi che dirigere un agente assomigli a competenze manageriali che si trasferiscono bene, ma può anche dipendere da come il successo viene misurato, perché la verifica si appoggia in parte alla conferma esplicita nella trascrizione, e un manager tende a comunicare più spesso quando ha ottenuto ciò che chiedeva.
Dal debug al lavoro completo in sette mesi
Il modo in cui si lavora con Claude Code è cambiato parecchio nei sette mesi osservati. Il cambiamento più chiaro riguarda la correzione di codice rotto, scesa dal 33% al 19% delle sessioni, mentre cresceva tutto il lavoro che sta attorno al codice: far funzionare il software è passato dal 14% al 21%, e scrittura e analisi dati sono all’incirca raddoppiate, da circa il 10% al 20%.
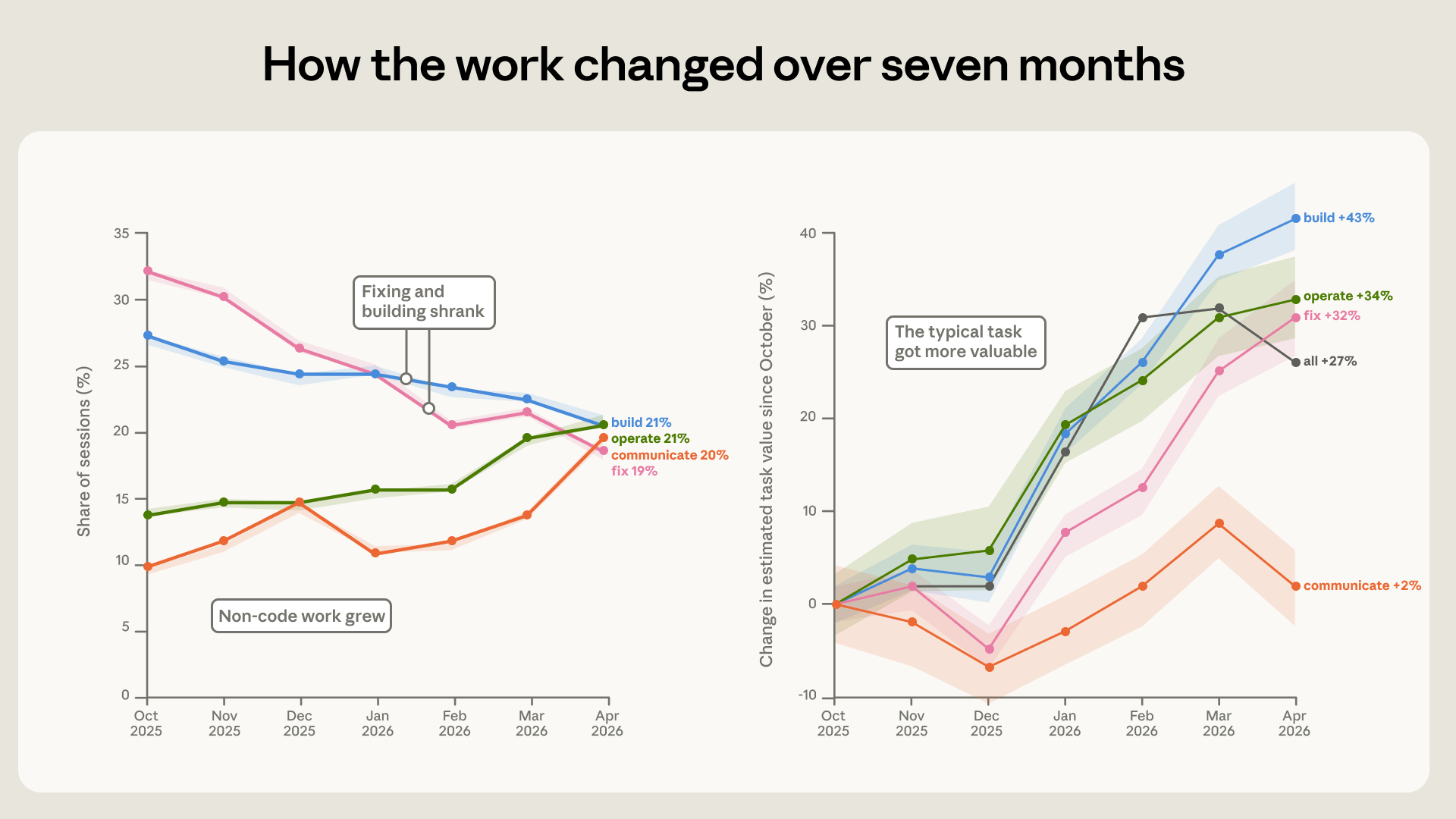
Anche il valore dei compiti è salito. Anthropic lo stima chiedendosi quanto costerebbe quel lavoro su un mercato di freelance, calibrato su un insieme reale di annunci, e con questa misura il valore della sessione media è cresciuto del 27% nel periodo. La crescita tiene su molti tipi di lavoro, costruire, far funzionare e correggere valgono circa un terzo in più, rispettivamente 43%, 34% e 32%, mentre la comunicazione resta quasi ferma. Sono stime grezze, utili a confrontare i compiti tra loro nel tempo più che a leggere un valore in euro.
Quattrocentomila sessioni che nessun ricercatore ha letto
Vale la pena tenere insieme la forza dei numeri e i loro limiti, perché lo studio è esplicito su entrambi. L’analisi preserva la privacy per costruzione, nessun ricercatore legge le singole trascrizioni, le etichette restano slegate da chi è identificabile, e si osservano solo aggregati su un numero minimo di utenti. Sono risultati preliminari, non si vede se il codice prodotto in una sessione finisca in produzione o nel cestino, resta fuori tutta la parte di uso non interattivo, che è consistente, e ogni classificazione dipende comunque dalla lettura che un modello fa della trascrizione.
Il valore di queste misure sta nel poterle seguire mentre i modelli, le persone e la divisione del lavoro tra loro cambiano. Se i ritorni della competenza cominciassero a calare, sarebbe il segno che i modelli iniziano a fornire da soli il giudizio che oggi porta la persona, e che i vantaggi si allargano oltre gli esperti di dominio. Se invece la quota di sessioni riuscite da chi non fa software continuasse a crescere, vorrebbe dire che produrre software sta diventando una parte del lavoro ordinario in ogni campo, e non più il prodotto di un singolo mestiere.
In «Pelle Digitale» descrivo la tecnologia come uno strato che aderisce a noi e cambia ciò che siamo capaci di fare, e qui se ne legge una conferma concreta, lo strumento amplifica chi porta comprensione e lascia indietro chi si limita a delegare. Per un’azienda la domanda smette di essere quanti sviluppatori servano, e diventa chi, in ogni funzione, conosce abbastanza a fondo i propri problemi da guidare un agente fino alla fine.
Senza dubbio la competenza di dominio è oggi la leva più sottovalutata di questa transizione, e allora vale la pena chiedersi: chi, nella nostra organizzazione, ha già le mani su questi strumenti, e quanto bene conosce davvero il lavoro che gli sta chiedendo di fare?





Partecipa alla community