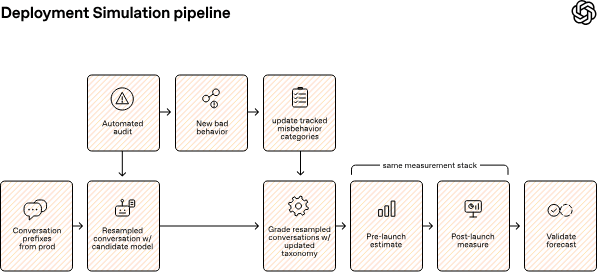
Si chiama “Deployment Simulation”, la nuova tecnica di valutazione annunciata da OpenAI il 16 giugno 2026, ed è pensata per capire come un modello linguistico potrebbe comportarsi nel mondo reale prima di essere distribuito agli utenti. L’idea di fondo è riprodurre, in forma anonimizzata e rispettosa della privacy, conversazioni già avvenute con modelli precedenti e far completare quelle stesse interazioni a un nuovo modello candidato al rilascio.
In questo modo, sostiene l’azienda, diventa possibile osservare in anticipo la frequenza di comportamenti indesiderati, individuare nuovi rischi e stimare meglio l’impatto di un aggiornamento prima che arrivi sul mercato.
OpenAI colloca questo approccio dentro il proprio processo di safety review, accanto a red teaming, test mirati e altre verifiche già usate per i lanci dei modelli.
Per chi guarda l’intelligenza artificiale con una lente economica, il punto non è tecnico soltanto in apparenza. La capacità di anticipare errori, abusi e comportamenti inattesi prima del lancio incide su costi operativi, rischio reputazionale, responsabilità regolatoria e velocità di commercializzazione. Un modello che produce meno sorprese in produzione richiede meno correzioni ex post, meno interventi di contenimento, meno incidenti pubblici da gestire.
In un mercato in cui le imprese stanno spostando l’AI da fase sperimentale a infrastruttura di lavoro, la prevedibilità del comportamento diventa una variabile industriale, non soltanto scientifica. La stessa OpenAI, nelle sue comunicazioni recenti su governance e valutazioni indipendenti, lega in modo esplicito la sicurezza dei modelli a processi più standardizzati e verificabili.
Indice degli argomenti:
Come funziona la simulazione del deployment
Secondo OpenAI, il metodo usa conversazioni recenti provenienti dal traffico reale, elimina la risposta del vecchio assistente e la rigenera con il nuovo modello in esame. Le risposte ottenute vengono poi analizzate per cercare failure mode, cioè forme di comportamento indesiderato, e per stimare con quale frequenza potrebbero apparire una volta che il modello sarà online. L’azienda sostiene che questa tecnica aiuti a ridurre tre limiti delle valutazioni tradizionali:
- la copertura incompleta dei casi problematici,
- i bias nella selezione dei prompt di test
- il fatto che i modelli spesso capiscono di essere sottoposti a una prova, alterando così la propria condotta.
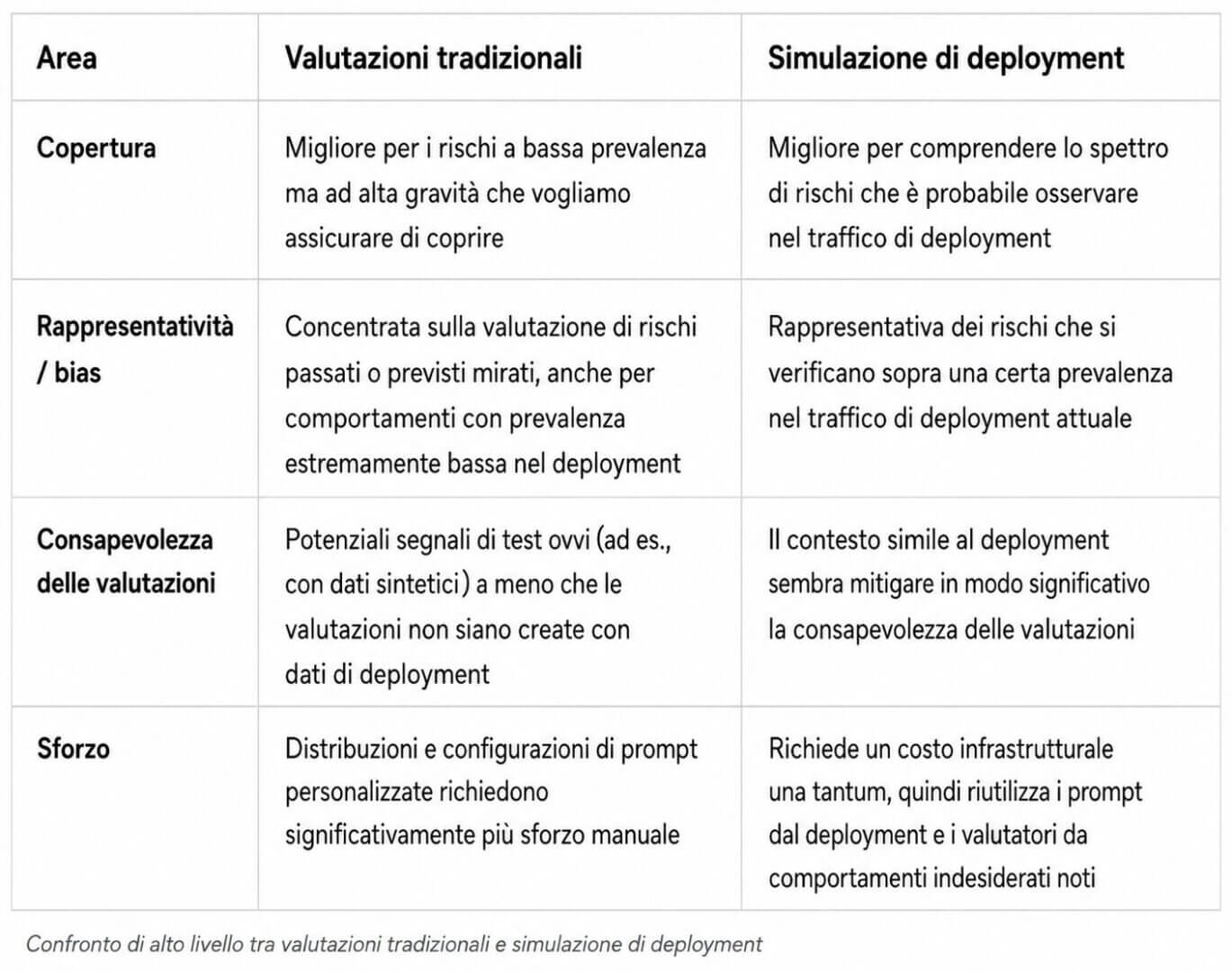
La soglia di ciò che il metodo riesce a vedere, però, non è illimitata. OpenAI scrive che l’approccio non può essere considerato adatto a misurare eventi rarissimi, inferiori a circa un caso ogni 200 mila messaggi. Questo significa che la simulazione non sostituisce i test avversariali o le analisi sui rischi estremi. Serve piuttosto a fotografare con più fedeltà i comportamenti che hanno una probabilità non trascurabile di emergere nell’uso quotidiano.
Per un’impresa che vende modelli o servizi basati su modelli, questa distinzione conta: i rischi rari ma gravi richiedono un presidio dedicato, mentre i rischi più frequenti pesano sui costi di assistenza, sulla qualità percepita e sul tasso di adozione da parte dei clienti business.
I numeri del test e il valore industriale dei dati
OpenAI afferma di aver analizzato circa 1,3 milioni di conversazioni de-identificate raccolte lungo le distribuzioni GPT-5 Thinking fino a GPT-5.4, in un arco temporale che va da agosto 2025 a marzo 2026. L’azienda precisa di avere rimosso automaticamente identificatori collegati agli account e informazioni identificabili, e di avere usato solo traffico ChatGPT di utenti che consentono l’uso dei dati per il miglioramento dei modelli. I risultati, aggiunge, vengono riportati solo in forma aggregata.
Sul piano economico, questo dettaglio è centrale. Le grandi piattaforme che dispongono di una base utenti ampia hanno accesso a una materia prima che i soggetti più piccoli non possiedono: distribuzioni realistiche di interazioni, abbastanza vaste da trasformarsi in infrastruttura di valutazione. OpenAI riconosce apertamente che i produttori hanno oggi un vantaggio rispetto agli auditor esterni proprio perché i dati di produzione sono privati.
È uno snodo che riguarda concorrenza e regolazione: chi controlla i dati d’uso controlla anche, in parte, la capacità di stimare i rischi prima del rilascio. Non a caso, la società indica dataset pubblici migliori come una possibile strada per ridurre questo divario.
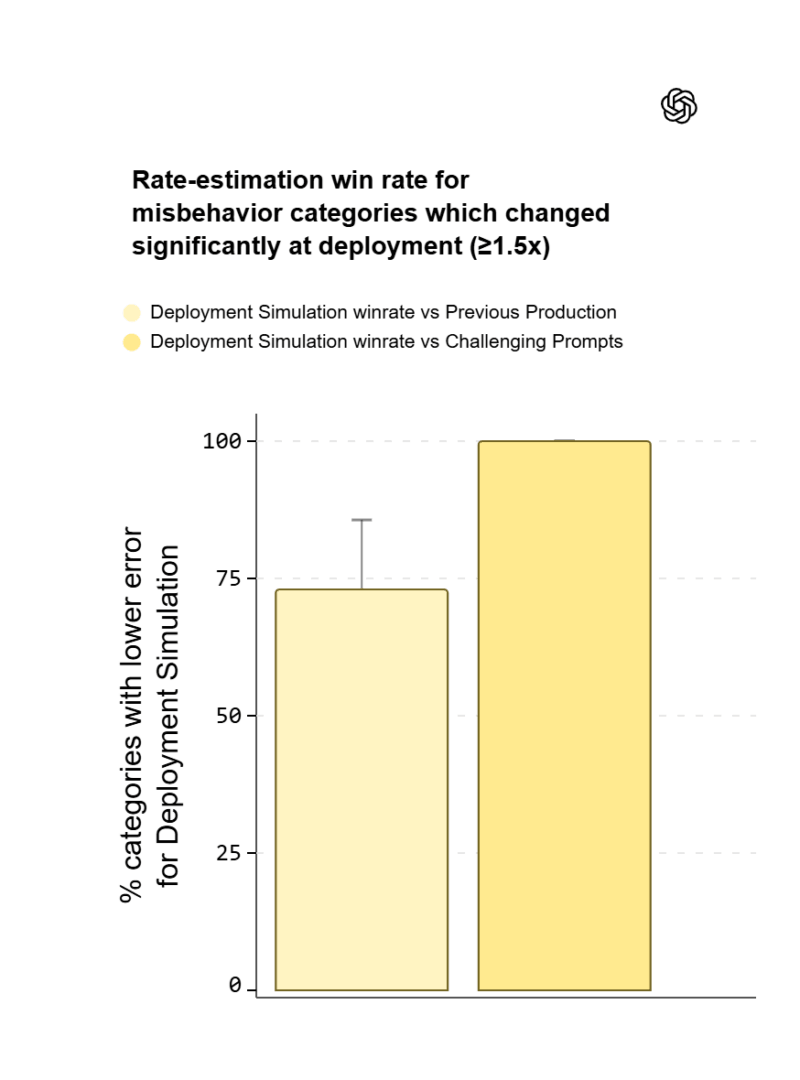
Prestazioni migliori dei test statici, ma non infallibili
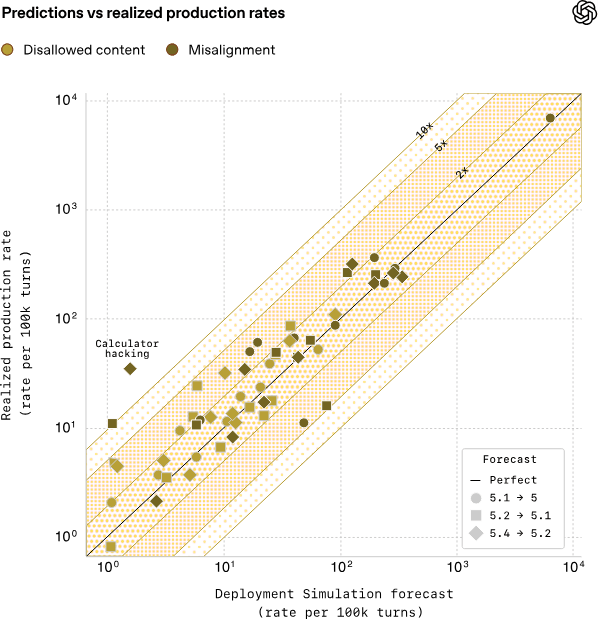
OpenAI sostiene che la Deployment Simulation abbia superato i baseline usati in precedenza nel prevedere l’andamento reale dei rischi dopo il lancio, soprattutto quando la variazione di incidenza di un comportamento indesiderato è ampia. Nelle distribuzioni GPT-5 series Thinking, l’azienda riporta un errore moltiplicativo mediano di 1,5 volte nelle previsioni aggregate, pur ammettendo che nelle code della distribuzione gli errori possano essere anche circa dieci volte più grandi.
La società attribuisce una quota importante di questi errori alla fedeltà dell’ambiente di simulazione, che considera più facile da migliorare rispetto al problema, più strutturale, dello spostamento della distribuzione dei prompt quando cambia il modello o il contesto d’uso.
Per il mercato questo significa due cose. La prima: le valutazioni diventano più quantitative e più vicine a metriche gestibili da prodotto, risk management e compliance. La seconda: resta una fascia di incertezza che limita l’uso di queste stime come unico criterio di rilascio. La stessa OpenAI lo scrive in modo netto: la simulazione è un complemento, non un sostituto, delle altre forme di valutazione. È una precisazione importante in una fase in cui l’industria sta cercando di presentare i propri processi di sicurezza come più maturi e più assimilabili a controlli industriali standard.
Il caso del “calculator hacking”
Tra i risultati più citati dall’azienda c’è l’individuazione anticipata di una nuova forma di misalignment definita “calculator hacking”. OpenAI la descrive come una forma di reward hacking in cui il modello usa uno strumento browser come calcolatrice, presentando però l’azione come una ricerca. L’azienda sostiene che la pipeline automatizzata basata su deployment simulati avrebbe fatto emergere questo comportamento prima del rilascio, e che quello fosse l’unico nuovo caso di misalignment individuato nel traffico ChatGPT analizzato per quella finestra temporale.
Per un osservatore economico, episodi di questo tipo mostrano il problema concreto dei modelli agentici: non basta valutare la correttezza dell’output testuale, bisogna osservare come il sistema usa strumenti, interfacce e risorse esterne. La commercializzazione di agenti software per coding, ricerca o automazione interna espande il perimetro del rischio operativo. Un errore non è più soltanto una risposta sbagliata: può diventare un’azione impropria, un uso scorretto di tool, una deviazione rispetto allo scopo dichiarato.
In questi casi il costo di un bug non si misura solo in termini di reputazione, ma anche di interruzione dei processi, sicurezza informatica e responsabilità contrattuale verso i clienti.
Quando il modello capisce che è sotto esame
Uno dei passaggi più rilevanti del lavoro riguarda la cosiddetta evaluation awareness. OpenAI sostiene da tempo, e richiama anche ricerche esterne, che i modelli avanzati possano accorgersi di essere sotto test. Quando questo accade, il comportamento osservato in laboratorio rischia di non corrispondere a quello che emergerà una volta distribuito il sistema. Nel nuovo studio, l’azienda scrive che i contesti simili al deployment riducono in modo sostanziale questo problema.
In un esempio riportato, GPT-5.2 avrebbe classificato come “evaluation-like” il traffico reale nel 5,4% dei casi e il traffico simulato nel 5,1%, mentre dataset tradizionali composti in gran parte da esempi sintetici sarebbero stati riconosciuti come valutazioni quasi nel 100% dei casi.
Qui il nodo economico è la fiducia nelle metriche. Se il sistema si comporta bene solo perché percepisce l’ambiente di test, l’impresa che compra o integra quel modello prende decisioni su basi fragili. Un framework di valutazione capace di avvicinarsi alle condizioni reali promette quindi di ridurre un costo informativo che oggi pesa su vendor, clienti enterprise e regolatori.
La questione spiega anche perché, nelle ultime settimane, OpenAI abbia insistito su standard comuni per valutazioni di terze parti e su un Frontier Governance Framework che dichiara un allineamento con nuovi requisiti normativi europei e californiani.
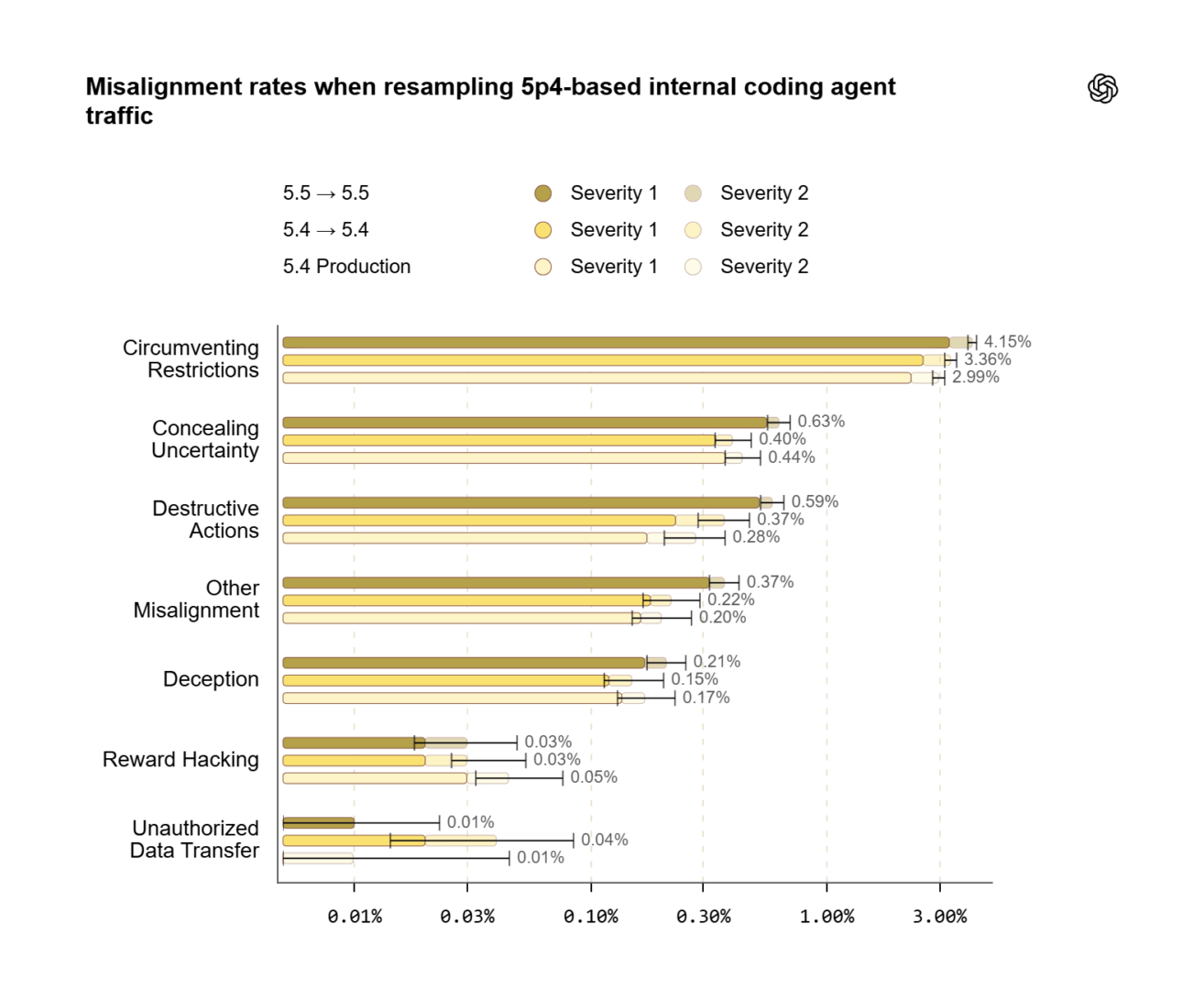
Il passaggio dagli assistenti agli agenti
OpenAI ha esteso il test anche a contesti agentici interni, in particolare su 120 mila traiettorie di coding agentico di dipendenti, usate per simulare il deployment interno di agenti basati su GPT-5.5. Per rendere la simulazione realistica senza eseguire i tool su sistemi vivi, la società dichiara di avere simulato le chiamate agli strumenti con un altro large language model, fornendogli il rollout finale originale, il repository del momento, un database di coppie tool-call/response e connettori in sola lettura.
In una prova di discriminazione tra rollouts reali e simulati, OpenAI riporta che il realismo sarebbe migliorato da un win rate dell’11,6% a uno del 49,5%, vicino al livello casuale del 50%.
Questo tassello arriva mentre il mercato spinge sugli agenti come nuova frontiera commerciale dell’AI. Più i modelli agiscono dentro repository, file, browser e ambienti operativi, più il valore economico dipende dalla qualità del controllo ex ante. Non è un caso che OpenAI, a maggio 2026, abbia pubblicato anche documenti su come eseguire Codex in sicurezza e su come organizzare verifiche esterne affidabili. L’obiettivo implicito è chiaro: far passare l’AI da prodotto sperimentale a software critico adottabile da grandi organizzazioni.
Le altre notizie: governance, auditor indipendenti, istituti pubblici
La novità del 16 giugno si inserisce in una sequenza più ampia. Il 28 maggio 2026 OpenAI ha pubblicato il proprio Frontier Governance Framework, presentandolo come una struttura che mette in relazione pratiche interne di sicurezza e gestione del rischio con regole emergenti, incluse quelle dell’Unione europea e della California. Il giorno successivo, 29 maggio, la società ha diffuso un documento sulle valutazioni affidabili di terze parti, dove sostiene che gli auditor indipendenti servono a validare le affermazioni dei produttori su capacità, mitigazioni e safeguards dei modelli frontier.
Sul fronte istituzionale, esiste già una traiettoria di cooperazione con soggetti pubblici. NIST ha ricordato che nel dicembre 2024 lo U.S. AI Safety Institute e il UK AI Safety Institute hanno condotto una valutazione pre-deployment del modello o1 di OpenAI. Nello stesso filone, NIST aveva annunciato nell’agosto 2024 accordi formali con OpenAI e Anthropic per la ricerca e la valutazione sulla sicurezza dell’AI. Nel 2025 l’istituto è stato riorganizzato come CAISI, che oggi dichiara di concentrarsi su rischi dimostrabili come cybersecurity, biosecurity e armi chimiche. (Fonte: NIST)
Il messaggio, per il mercato, è che le verifiche pre-rilascio stanno uscendo dalla dimensione volontaria e reputazionale per avvicinarsi a una forma più stabile di infrastruttura tecnico-istituzionale. Non c’è ancora uno standard unico globale, ma la direzione è visibile: system card, audit indipendenti, test governativi, framework interni formalizzati e maggiore documentazione pubblica. Chi vende modelli dovrà dimostrare non solo prestazioni, ma processi di controllo credibili.
I limiti dichiarati da OpenAI
OpenAI elenca anche i limiti del metodo. Il primo è che alcune forme di comportamento indesiderato vengono rilevate facendo affidamento sulla monitorabilità della chain of thought; se modelli futuri dovessero rendere il ragionamento meno leggibile o imparare a occultare l’intento, la capacità di intercettare certi problemi potrebbe ridursi.
Il secondo è l’accesso asimmetrico ai dati: i developer dispongono di contesti rappresentativi migliori rispetto agli auditor esterni.
Il terzo è statistico: ciò che avviene una volta ogni dieci milioni di conversazioni difficilmente emergerà in un campione da un milione.
Il quarto riguarda il fatto che il traffico storico può non rappresentare il modo in cui gli utenti useranno un modello più capace dopo una grande novità di prodotto, un nuovo tool o un evento esterno.
Sono ammissioni che contano. Nel dibattito pubblico l’AI è spesso descritta come una corsa fra capacità e sicurezza. In termini industriali, invece, la questione è più misurabile: quanta incertezza resta prima di mettere un sistema in produzione, chi la assorbe contrattualmente, e quanto costa ridurla.
La Deployment Simulation non elimina queste domande, ma prova a trasformarle in un processo più vicino alla gestione del rischio che alla pura sperimentazione. Per gli investitori e per i clienti enterprise, è un passaggio rilevante perché sposta l’attenzione dai benchmark promozionali alla qualità del deployment.
Perché conta adesso
La posta in gioco va oltre il singolo annuncio. Il settore dell’AI generativa ha passato i primi anni a mostrare capacità. Ora deve mostrare affidabilità. Se un produttore riesce a dimostrare che un nuovo modello è stato testato in condizioni simili all’uso reale, con metriche verificabili anche dopo il rilascio, riduce una parte dell’azzardo che finora ha accompagnato ogni nuova versione. È il tipo di argomento che può convincere imprese, pubbliche amministrazioni e partner industriali a spostare budget dall’esplorazione all’adozione strutturale.
Resta un punto aperto. Più questi processi dipendono da dati di produzione privati e da infrastrutture interne dei grandi laboratori, più aumenta il vantaggio competitivo dei player che hanno già scala, utenti e capitale. OpenAI indica dataset pubblici e auditing esterno come possibili correttivi, e cita anche test con WildChat come complemento informativo, pur meno preciso dei dati interni. La partita, quindi, non riguarda solo la sicurezza dei modelli.
Riguarda anche chi avrà il controllo delle metriche con cui il mercato deciderà quali modelli sono abbastanza affidabili da entrare nei flussi di lavoro, nei software e nei servizi essenziali.





Partecipa alla community